Cloudera Enterprise Reference Architecture for Google Cloud Platform Deployments
Abstract
An organization’s requirements for a big-data solution are simple: Acquire and combine any amount or type of data in its original fidelity, in one place, for as long as necessary, and deliver insights to all kinds of users, as quickly as possible.
Cloudera, an enterprise data management company, introduced the concept of the enterprise data hub (EDH): a central system to store and work with all data. The EDH has the flexibility to run a variety of enterprise workloads (for example, batch processing, interactive SQL, enterprise search, and advanced analytics) while meeting enterprise requirements such as integration to existing systems, robust security, governance, data protection, and management. The EDH is the emerging center of enterprise data management. The EDH builds on Cloudera Enterprise, which consists of the open-source Cloudera Distribution including Apache Hadoop (CDH), a suite of management software and enterprise-class support.
In addition to needing an enterprise data hub, enterprises are looking to move or add this powerful data-management infrastructure to the cloud for operational efficiency, cost reduction, compute and capacity flexibility, and speed and agility.
As organizations embrace Hadoop-powered big-data deployments in cloud environments, they also want enterprise-grade security, management tools, and technical support--all of which are part of Cloudera Enterprise.
Customers of Cloudera and Google Cloud Platform can now run the EDH in the Google cloud, leveraging the power of the Cloudera Enterprise platform and the flexibility of the Google cloud.
Cloudera Reference Architecture documents illustrate example cluster configurations and certified partner products. The Cloud RAs are not replacements for official statements of supportability, rather they’re guides to assist with deployment and sizing options. Statements regarding supported configurations in the RA are informational and should be cross-referenced with the latest documentation.
Cloudera on Google Cloud Platform
Cloudera and Google make it possible for organizations to deploy the Cloudera solution as an EDH on Google Cloud Platform. This joint solution combines Cloudera’s expertise in large-scale data management and analytics with Google’s expertise in cloud computing.
In this white paper, we provide an overview of best practices for running Cloudera Enterprise on Google Cloud Platform and leveraging different Google Cloud Platform services such as Compute Engine, Cloud Storage, and Cloud Interconnect.
Google Cloud Platform Overview
Run your application on Google’s infrastructure, the same infrastructure that provides fast query results, serves video, and provides email services to millions. Their offerings consists of several different services, ranging from storage to compute, to higher up the stack for automated scaling, messaging, queuing, and other services. Cloudera Enterprise deployments can use the following service offerings.
Compute Engine
With Google Compute Engine, users can utilize high-performance virtual machines powered by Google’s global network, paying only for what they use. For this deployment, Compute Engine instances are the equivalent of servers that run Hadoop. Compute Engine offers several different types of instances with different pricing options. For Cloudera Enterprise deployments, each individual node in the cluster conceptually maps to an individual server. A list of supported instance types and their roles in a Cloudera Enterprise deployment are described later in this document.
Cloud Storage
Google Cloud Storage allows users to store and retrieve various sized data objects using simple API calls. Several product options are available, depending on the performance needs of the organization; all options provide a high degree of durability.
Interconnect
Google Cloud Hybrid Connectivity provides several means to establish connectivity between your data center and Compute Engine networks, ranging from Cloud VPN to direct peering to carrier interconnect.
Deployment Architecture
System Architecture Best Practices
This section describes Cloudera’s recommendations and best practices applicable to Hadoop cluster system architecture.
Java
Refer to CDH and Cloudera Manager Supported JDK Versions for a list of supported JDK versions.
Right-size Server Configurations
Cloudera recommends deploying three or four machine types into production:
- Master Node. Runs the Hadoop master daemons: NameNode, Standby NameNode, YARN Resource Manager and History Server, the HBase Master daemon, Sentry server, and the Impala StateStore Server and Catalog Server. Master nodes are also the location where Zookeeper and JournalNodes are installed. The daemons can often share single pool of servers. Depending on the cluster size, the roles can instead each be run on a dedicated server. Kudu Master Servers should also be deployed on master nodes.
- Worker Node. Runs the HDFS DataNode, YARN NodeManager, HBase RegionServer, Impala impalad, Search worker daemons and Kudu Tablet Servers.
- Utility Node. Runs Cloudera Manager and the Cloudera Management Services. It can also host a MySQL (or another supported) database instance, which is used by Cloudera Manager, Hive, Sentry and other Hadoop-related projects.
- Edge Node. Contains all client-facing configurations and services, including gateway configurations for HDFS, YARN, Impala, Hive, and HBase. The edge node is also a good place for Hue, Oozie, HiveServer2, and Impala HAProxy. HiveServer2 and Impala HAProxy serve as a gateway to external applications such as Business Intelligence (BI) tools.
For more information refer to Cluster Hosts and Role Assignments.
Workloads, Roles, and Machine Types
In this reference architecture, we consider different kinds of workloads that run on top of an enterprise data hub and make recommendations on the Google Compute Engine machine types that are suitable for each of these workload types. The recommendations consider machine types with various storage options, including magnetic disks and SSDs. You choose machine types based on the workload you run on the cluster. You should also do a cost-performance analysis, specifically for SSD storage.
Master Nodes
Master nodes for a Cloudera Enterprise deployment run the master daemons and coordination services, which may include:
- ResourceManager
- NameNode
- Standby NameNode
- JournalNodes
- ZooKeeper
Allocate a vCPU for each master service. The more master services you are running, the larger the machine will need to be. For example, if running YARN, Spark, and HDFS, a machine with eight vCPUs is sufficient (two for the OS plus one for each YARN, Spark, and HDFS is five total and the next smallest instance vCPU count is eight). If you add HBase, Kafka, and Impala, you would pick a machine type with more vCPU and memory. The memory footprint of the master services tend to increase linearly with overall cluster size, capacity, and activity.
Cloudera supports running master nodes on both local- and persistent disk-backed machines.
Utility Nodes
Utility nodes for a Cloudera Enterprise deployment run management, coordination, and utility services, which may include:
- Cloudera Manager
- JournalNode
- ZooKeeper
- Oozie
- Hive Server
- Impala Catalog Server
- Impala State Store
- Job History Server
- Cloudera Management Services
Refer to Master node requirements.
Worker Nodes
Worker nodes for a Cloudera Enterprise deployment run worker services. These may include:
- HDFS DataNode
- YARN NodeManager
- HBase RegionServer
- Impala Daemon
- Solr Servers
Allocate a vCPU for each worker service. For example an HDFS DataNode, YARN NodeManager, and HBase Region Server would each be allocated a vCPU. You will need to consider the memory requirements of each service. Some services like YARN and Impala can take advantage of additional vCPUs to perform work in parallel. Consider your cluster workload and storage requirements, determine the vCPU and memory resources you wish to allocate to each service, then select a machine type that’s capable of satisfying the requirements. Don’t forget to include two vCPUs for the OS.
Edge Nodes
An edge node contains client-facing configurations and services, including gateway configurations for HDFS, MapReduce, Hive, and HBase. Hadoop client services run on edge nodes. These services may include:
- Third-party tools
- Hadoop command-line client
- Beeline client
- Flume agents
- Hue Server
Edge node services are typically deployed to the same type of hardware as those responsible for master node services, however any machine type can be used for an edge node so long as it has sufficient resources for your use. Depending on the size of the cluster, there may be numerous systems designated as edge nodes.
Machine Types
The following matrix shows the different workload categories, machine types, and the roles they are suited for in a cluster.
| Typical Services | Machine Types for Master Nodes | Machine Types for Worker Nodes |
|
n1-highmem-2 |
n1-standard-8 |
|
n1-highmem-8 |
n1-highmem-16 n1-highmem-32 n1-highmem-64 |
|
n1-highmem-16 |
n1-highmem-16 n1-highmem-32 n1-highmem-64 |
For dedicated Kafka brokers we recommend n1-standard-4 instances.
A detailed list of configurations and pricing for the different machine types is available on the Google Compute Engine pricing page.
Regions and Zones
Regions are collections of zones, which are isolated locations in a general geographic location. Some regions have more zones than others. Zones maintain high-bandwidth, low-latency network connections to other zones in the same region. Zones can provide unique features such as specific processor types or high-core machines. When provisioning, you can choose a specific availability zone.
When planning a deployment, make sure to review the pricing for data transfer in and out of zones. Consider the ingress, transfer between, and egress out of zones.
Cloudera EDH deployments are restricted to single regions. Clusters spanning regions are not supported. For more information, consult Appendix A: Spanning GCP Zones.
Networking, Connectivity, and Security
Each VM instance is assigned to a single network, which controls how the instance can communicate with other instances and systems outside the network. The default network allows inbound SSH connections (port 22) and disallows all other inbound connectivity. Outbound connectivity is not restricted, nor is connectivity between instances on the same network.
When provisioned, each VM instance is assigned an internal IP and an ephemeral external IP. Cloudera recommends that you use the internal instance IP addresses when configuring the cluster.
More information about instances and network is available in the Google Compute Engine documentation.
Recommended Images
Google Compute Engine is compatible with numerous operating systems and provides support for many prebuilt images. Cloudera Enterprise deployments on Google Compute Engine are only supported when installed on operating systems supported by both Cloudera and Compute Engine, such as modern CentOS, Red Hat, Ubuntu.
RHEL is considered a premium operating system; VMs launched with premium images incur additional hourly fees based in part on the machine type being launched.
Storage Options and Configuration
Google Cloud Platform offers different storage options that vary in performance, durability, and cost.
Google Compute Engine
Persistent Disks
Persistent disks are used as primary storage for VM instances. These disks provide durable network storage that can be attached to VM instances. If the VM instance fails or is terminated, the disk can simply be reattached to another instance. Depending on performance requirements, persistent storage can be backed by either standard hard disks or SSDs.
Cloudera requires using standard SSD persistent disks for master servers, one each dedicated for DFS metadata and ZooKeeper data. While these volumes don’t suffer from the contention issues that can arise when using ephemeral disks, using dedicated volumes for each service can simplify resource monitoring. Cloudera requires standard SSD persistent disk volumes have a minimum capacity of 100 GB to maintain sufficient IOPs, although volumes can be sized larger to accommodate cluster activity.
Cloudera recommends using standard persistent disks as DataNode storage, no more than two per VM instance. Because a persistent disk volume’s throughput increases linearly with volume size, the recommended minimum volume size is 1.5 TB.
Cloudera does not support regional persistent disks.
Local SSD
Local SSD provides local-attached storage to VM instances, providing increased performance at the cost of availability, durability, and flexibility. The lifetime of the storage is the same as the lifetime of the VM instance. If you stop or terminate the VM instance, the storage is lost. Local SSD cannot be used as a root disk. Users of local SSD should take extra precautions to back up their data.
Google Cloud Storage
Google Cloud Storage can be used to ingest or export data to or from your HDFS cluster. In addition, it can provide disaster recovery or backup during system upgrades. The durability and availability guarantees make it ideal for a cold backup that you can restore in case the primary HDFS cluster goes down.
Refer to Configuring Google Cloud Storage Connectivity for details.
For a hot backup, you need a second HDFS cluster holding a copy of your data. Refer to Backup and Disaster Recovery for details.
Root Device
When instantiating the VM instances, you can define the root device size. The root device size for Cloudera Enterprise clusters should be at least 500 GB to allow parcels and logs to be stored. By default, the root device is partitioned only with enough space for its source image or snapshot; repartitioning the root persistent disk may require manual intervention, depending on the operating system used.
Capacity Planning
Using Google Compute Engine allows you to scale your Cloudera Enterprise cluster up and down easily. If your storage or compute requirements change, you can provision and deprovision instances and meet your requirements quickly, without buying physical servers. However, some advance planning makes operations easier. You must plan for whether your workloads need a high amount of memory or compute. The available VM instances have different amounts of memory and compute, and deciding which instance type and generation make up your initial deployment depends on the storage and workload requirements. The operational cost of your cluster depends on the type and number of instances you choose, combined with the amount and type of storage provisioned.
Relational Databases
Cloudera Enterprise deployments require relational databases for the following components: Cloudera Manager, Cloudera Navigator, Hive metastore, Hue, Sentry, Oozie, and others. The database credentials are required during Cloudera Enterprise installation. Refer to Cloudera Manager and Managed Service Datastores for more information.
For operating relational databases in Google Compute Platform, Cloudera requires you to provision VM instances and install and manage your own database instance. For more information, see to the list of supported database types and versions.
Installation and Software Configuration
Preparation
Provisioning Instances
To provision Google Compute Engine instances, you can use the Google Cloud SDK, the Google Developers Console, or Cloudera Director. When provisioning instances, make sure to specify the following:
- A recommended image
- A root disk of the proper size
- For DataNodes, one or two properly sized persistent disks
You must also provision relational databases. The database credentials are required during Cloudera Enterprise installation.
Setting Up Instances
Once the instances are provisioned, perform the following to prepare them for deploying Cloudera Enterprise:
- Disable iptables
- Disable SELinux
- Format and mount the instance storage, if not done during provisioning
- Resize the root volume if it does not show full capacity
For more information on operating system preparation and configuration, see the Cloudera Manager installation instructions.
Deploying Cloudera Enterprise
If you are using Cloudera Manager, log into the instance that you have elected to host Cloudera Manager and follow the Cloudera Manager installation instructions.
Cloudera Director is another deployment option that is tailored for the cloud. Cloudera Director allows you to easily deploy, monitor and modify clusters in Google Cloud Platform and other cloud providers. Detailed information regarding environment setup and prerequisites are provided in Director’s Getting Started on Google Cloud Platform documentation. Cloudera Director provides additional capabilities to grow or shrink your cluster to match changing needs in your workload.
Cloudera Enterprise Configuration Considerations
HDFS
Durability
For Cloudera Enterprise deployments in Google Compute Engine, the recommended storage option is standard persistent storage. HDFS on SSD persistent storage or local SSD are not recommended configurations. Guarantee data durability in HDFS by keeping replication at three. Cloudera does not recommend lowering the replication factor.
Availability
Ensure HDFS availability by deploying the NameNode with high availability with at least three JournalNodes.
ZooKeeper
Cloudera recommends running at least three ZooKeeper servers for availability and durability.
Flume
For durability in Flume agents, use file channel. Flume’s memory channel offers increased performance at the cost of no data durability guarantees. File channels offer a higher level of durability guarantee because the data is persisted on disk in the form of files. For guaranteed data delivery, use persistent disk-backed storage for the Flume file channel.
Security Integration
The Cloudera Security guide is intended for system administrators who want to secure a cluster using data encryption, user authentication, and authorization techniques.
It provides conceptual overviews and how-to information about setting up various Hadoop components for optimal security, including how to setup a gateway to restrict access. The guide assumes that you have basic knowledge of Linux and systems administration practices, in general.
Summary
Cloudera and Google Cloud Platform allow users to deploy and use Cloudera Enterprise on Google Cloud Platform infrastructure, combining the scalability and functionality of the Cloudera Enterprise suite of products with the flexibility and economics of the Google cloud. This white paper provided reference configurations for Cloudera Enterprise deployments in Google Cloud Platform. These configurations leverage different Google Cloud services such as Compute Engine, Cloud Storage, and Cloud Interconnect.
Appendix A: Spanning GCE Zones
Spanning a CDH cluster across multiple Zones can provide highly available services and further protect data against GCE host, rack, and datacenter failures.
We recommend the following deployment methodology when spanning a CDH cluster across multiple GCE zones.
GCE Provisioning
Provision all GCE instances in a single VPC network but within zones.
Deploy across three (3) zones within a single region.
CDH Deployment
Deploy HDFS NameNode in High Availability mode with Quorum Journal nodes, with each master placed in a different zone. For example, if you’ve deployed the primary NameNode to us-east1-b you would deploy your standby NameNode to us-east1-a or us-east1-c. You should place a QJN in each zone.
Although HDFS currently supports only two NameNodes, the cluster can continue to operate if any one host, rack, or zone fails:
- lose active NameNode, standby NameNode takes over
- lose standby NameNode, active is still active; promote 3rd zone master to be new standby NameNode
- lose zone without any NameNode, still have two viable NameNodes
Deploy YARN ResourceManager nodes in a similar fashion.
Deploy a three node ZooKeeper quorum, one located in each zone.
Deploy edge nodes to all three zones and configure client application access to all three.
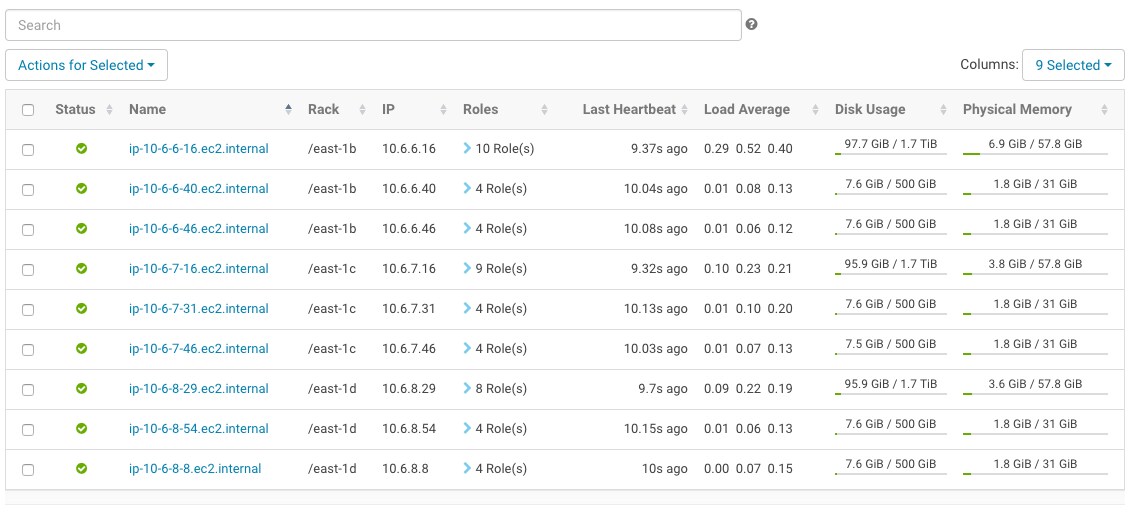
Configure rack awareness, one rack per zone. See the following screenshot for an example.
Considerations
There are data transfer costs associated with GCE network data sent between zones.
DFS throughput will be less than if cluster nodes were provisioned within a single zone.
Network throughput and latency vary based on zone and GCE machine size and neither are guaranteed. GCE machines have a 2 Gbps egress cap per vCPU (up to 16 Gbps/machine). Expect a drop in throughput when a smaller instance is selected and a slight increase in latency as well; both ought to be verified for suitability before deploying to production.