Security on AWS: Best Practices
As discussed in Cloudera Enterprise in the Cloud, Cloudera clusters can be deployed to the cloud using any of the three leading cloud providers, including Amazon Web Services (AWS). Unlike on-premises clusters running securely under the complete control of your IT department, cloud-based clusters require you to manage greater risk.
For example, organizations must connect to the cloud provider and set up the instances to support the cluster, and then install and launch a Cloudera cluster. Whether the cluster runs for 5 minutes or 5 months, it must be configured so that it is available only to the appropriate people and processes, and that it is always available when they need it.
Furthermore, although cloud providers can handle many aspects of security for you, Cloudera adds enterprise security capabilities for clusters beyond what cloud providers can offer. Cloudera customers can be in complete control of their security—managing encryption keys outside the control of the cloud provider or enabling users to authenticate to the cloud through the organization’s Active Directory (or other LDAP) server, for example. How can you get the best of both worlds—on premises and cloud—while ensuring security for your system and its data? This guide aims to help you do just that.
This guide focuses on security best practices for Cloudera clusters deployed to the Amazon Web Services (AWS) cloud.
Preliminary Planning
Organizations deploying clusters to any of the public clouds can achieve cost-savings, productivity, high availability, and many other benefits by carefully considering the best practices for different deployment patterns in the context of a specific use case.
In addition to meeting cost-savings and other goals, organizations must also ensure that cloud deployments meet all relevant privacy, integrity, and confidentiality requirements. For example, organizations in highly regulated industries may need to keep extensive audit trails and be able to track data lineage over time.
- Identify the people and processes that need to use the cluster: Are they members of the same division in your organization?
- Identify your users and the specific levels of access to cluster resources and data needed so you can effectively shape your identity, authentication, and authorization requirements.
- Do you need to comply with industry or government regulations for privacy, confidentiality, or other security requirements?
- Do you need to be able to identify distinct users or processes that acted on any data as part of a complete audit trail, for example?
- For a given cluster or for a specific dataset on Amazon S3, should all users who have access be allowed to see all the data? If not, you must set up a multi-tenant cluster.
- Does your organization use an LDAP-based directory (for example, Microsoft Active Directory) for identity management, and if so, do you want to leverage that service when you deploy to the cloud? Or would your organization rather manage an additional set of credentials for all users, just for use in the cloud?
- Identify the locations, format, structure, of data sources.
- Identify encryption mechanisms, keys, and other specific details about how you encrypt data at rest now or plan to in the future.
- Test different sample workloads from your production system to determine the optimal deployment architecture.
These are just some of the questions to consider before deploying any cluster, with security in mind.
- Lifetime of the cluster (transient or persistent)
- Tenancy or usage profile (single-user or multi-tenant)
Other distinguishing characteristics of the architectural patterns are shown in the table below.
| Lifetime | Tenancy | Key Components | Data Source/Target |
|---|---|---|---|
| Transient | Single-user | Apache Hive, Apache Spark, Hive on Spark, HDFS | Amazon S3 |
| Persistent | Multi-tenant | Apache Impala, Apache Spark, Hive on Spark, HDFS | Amazon S3 |
| Persistent | Multi-tenant | Apache HBase, Apache Spark | HDFS, Amazon S3 |
Regardless of type and architectural pattern, all cloud deployments to AWS must first consider network security.
Network Security
Deploying a cluster to the Amazon public cloud starts by configuring and securing the necessary network infrastructure hosted by the cloud provider. For clusters deployed to the Amazon Web Services cloud, this requires an Amazon Virtual Private Cloud (VPC).
Amazon automatically provisions a default VPC for each customer AWS account. The default VPC includes several related networking infrastructure entities, including a default subnet, default security group, default routing table, and so on. The defaults are fine for proof-of-concept deployments, but follow the best practices below for production systems.
Create and Configure a VPC
- Create a VPC. The VPC will support the instances you want to deploy to the cloud, including an instance needed for Altus Director (if you plan to use that deployment tool), and for the specific EC2 instances that you will create to support the cluster or clusters, for specific workloads.
- Create public and private subnets to isolate traffic within the VPC. Plan out the IP addresses you will need for the security groups needed to secure the cluster.
- Add and configure a VPC Endpoint so the private subnet can connect to your Amazon S3 storage.
- Add a VPN (virtual private network) to the VPC to securely connect
your on-premises data center to the Amazon cloud. The VPN lets your on-premises network communicate securely with the VPC. Amazon offers four types of VPN Connections, so pick the one that’s best for
your use case:
- AWS hardware VPN: Supports IPsec VPN connections
- AWS Direct Connect: Use this for a dedicated secure connection between your corporate network and Amazon AWS. This choice requires coordination between your organization’s network infrastructure team and Amazon AWS, as well as hardware setup and configuration. See AWS Direct Connect for details.
- AWS VPN CloudHub: Supports multiple remote networks. Use this if you have several remote branch offices, for example, that you want to connect to the VPC.
- Software VPN: Runs on an EC2 instance using third-party software.
Create Security Groups
- Create one security group for the cluster’s edge node (or nodes, for high availability configurations). Also known as the “gateway node,” an edge node runs instances of specific gateway roles that let end-users and applications use cluster services.
- Give the edge node security group unlimited outbound access to the public internet.
- Limit inbound access to specific IP addresses from your corporate network or other approved IP addresses.
- Use IP addresses from the public subnet to make specific gateway roles accessible to users.
- Create a second security group for the other nodes of the cluster—the master nodes, worker nodes, and management nodes. The EC2 instances comprising the cluster must be able to communicate with each other through various ports, so these can be configured in the private subnet.
- Give this security group outbound access to the internet, for use with other AWS services and Amazon S3 storage and to access external repositories for software updates. For example, the EC2 instance that’s used for Altus Director must be able to access the software repository to download and install the Altus Director software.
- Use private IP addresses for the nodes to communicate internally.
- Do not use a public IP address for Cloudera Manager.
- Cloudera Enterprise Reference Architecture for AWS Deployments, specifically, the “Networking, Connectivity, and Security” section.
- Getting Started on Amazon Web Services (AWS) in the Altus Director documentation, specifically, Setting up the AWS Environment.
- Amazon Virtual Private Cloud (VPC) and Amazon EC2 (Network and Security) documentation.
Transient Single-User Clusters Using Amazon S3
| Architectural Pattern | Transient single-user clusters backed by Amazon S3 |
| Cluster Services | Apache Hive, Apache Spark, Spark on Hive, and HDFS |
| Dependencies | Altus Director running on a persistent Amazon EC2 instance |
| Use Case | Data engineering, ETL for data warehousing, data pipelines |
Transient single-user clusters are ideal for extract, transform, and load (ETL) data pipelines and other workloads that have relatively short durations. Cloud resources are shut down when the workload completes. The processes may be initiated and managed by a single user or a small group, or launched by means of a cron job.
In general, transient single-user clusters make sense for any workload that has a limited lifespan and small number of users with equivalent access privileges. These are also comparatively easy to secure—only coarse-grained authorization privileges are needed because the assumption is that anyone given access to the cluster is entitled to access all of the data associated with that cluster.
Example Use Case
Assume that data from several different applications and database systems, including extracts from an Oracle database, customer reports from Salesforce, and .csv files from legacy systems, is uploaded to Amazon S3 (Object Storage), to a raw_input bucket.
Twice a week, a member of the etl_team uses Altus Director to launch EC2 instances, spins up the cluster, runs the workload, and then shuts down the cluster when the workload completes. As the job runs on the cluster, results are written back to Amazon S3 to the etl-results bucket.
Given the small number of possible users—all of whom have the same permissions to the source data and to the resources needed to run the job—this workload can use Amazon Identity and Access Management for identity, authentication, and authorization within the cluster, and can use Altus Director to launch and manage the cluster when needed.
Identity, Authentication, and Authorization
For transient single-user clusters, use Amazon Identity and Access Management (IAM) to create an IAM role that can be used to launch the EC2 instances and run all aspects of the workload.
The Amazon IAM role takes care of both authentication and authorization for the cluster in the Amazon cloud, and access to the Amazon S3 storage bucket. When you set up an IAM role and use the profile to launch the cluster as described below, any user logging into the cluster can access all data in the Amazon S3 bucket specified in the policy, without the need to provide any other credentials.
- Use your AWS Management Console to create an IAM role for EC2. When you do this, the console creates the role and an instance profile that will be available to use when you launch your EC2 instances.
- Add a policy to the Amazon S3 bucket (Bucket Policy) that specifies
what authenticated users (the IAM role is authenticated by AWS) can do.
For example, here’s a policy that let's the IAM role list, read, write, and delete objects on the Amazon S3 etl-results bucket. Both bucket-name and bucket-name/* are required in the Resource list, as shown in this example (etl-results/*,
etl-results):
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:DeleteObject", "s3:GetObject", "s3:GetObjectAcl", "s3:PutObject", "s3:PutObjectAcl", "s3:GetBucketAcl", "s3:ListBucket" ], "Resource": [ "arn:aws:s3::: etl-results/*", "arn:aws:s3::: etl-results" ] } ] } - Launch the EC2 instances using the instance
profile created for the IAM role. For ease of deployment, use Altus Director to launch transient single-user clusters. Altus Director provides two different tools for deploying clusters: Altus
Director UI or the Altus Director command-line:
- Altus Director UI is a web-server-hosted console that can be accessed at https://your.instance.hosting.director.ui:7187. Enter the profile name in the Advanced Options section of an instance template, as shown here:
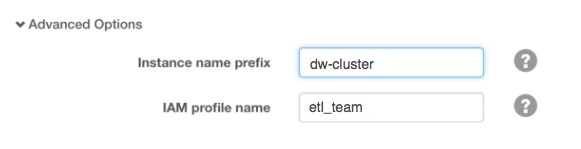
- Altus Director command-line lets you submit the details in a cluster configuration file to the Altus Director server. For example, here is the iamProfileName setting from the sample template for the Cloudera Enterprise Reference Architecture for AWS Deployments (obtain scripts
from GitHub's Altus Director scripts section):
... # Name of the IAM Role to use for this instance type # iamProfileName: iam-profile-REPLACE-ME iamProfileName: etl_team ...
- Altus Director UI is a web-server-hosted console that can be accessed at https://your.instance.hosting.director.ui:7187. Enter the profile name in the Advanced Options section of an instance template, as shown here:
Whether deployed using the Altus Director UI console or the command-line, the EC2 instance is launched using the instance profile (‘iamProfileName’) containing the IAM role, and the result is that your EC2 instances can all use the Amazon S3 bucket associated with the profile.
Encryption (Data in Transit)
Cloudera generally recommends configuring TLS/SSL to encrypt network communications. However, for transient clusters that may have no active management involved and for which the Cloudera Manager instance has been deployed merely to facilitate cluster installation and deployment, TLS/SSL may not be a strict requirement. For short-lived clusters dedicated to limited sets of processing tasks running under the control of a single user account or an IAM role, the setup required for TLS/SSL may be more costly in terms of time than the use case demands.
If you do have a strict requirement to encrypt communications within the cluster, however, you can script this yourself and use Altus Director to automate the process. See How-to: Deploy a Secure Enterprise Data Hub on AWS for more information.
Encryption (Data at Rest)
- Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3)—Keys are generated and managed by Amazon.
- Server-Side Encryption using Amazon Key Management Server (SSE-KMS)—Keys are created and managed using AWS Key Management Server. Supply the key name in the IAM profile (the IAM user launching the cluster must have permission to use the key).
Cloudera clusters fully support both these options, so use the mechanism that makes the most sense for your specific use case.
- How to Configure Encryption for Amazon S3 in Cloudera Security
- Writing Encrypted Data to Secure S3 Buckets From Altus Jobs in the Cloudera Altus documentation
- Protecting Data Using Server-Side Encryption in the Amazon AWS documentation
Auditing
Transient clusters that process data pipelines and ETL jobs typically do not require extensive audit trails. You can enable Amazon S3 logging (through the AWS Management Console) to track events that occur on the Amazon S3 storage bucket. However, AWS has limited auditing capabilities, so be aware
of the limitations in the context of your workload. For example, according to Amazon (Server
Access Logging documentation), although Amazon S3 server logs can provide “an idea of the nature of traffic against your bucket," they are not meant as “a complete accounting of all requests."
This example of an Amazon S3 log message captures an unauthorized access request:

Persistent Multi-Tenant Clusters Using Amazon S3
| Architectural Pattern | Persistent multi-tenant clusters backed by Amazon S3 |
| Cluster Services | Apache Impala, Apache Hive, Hive on Spark, and HDFS |
| Dependencies | Kerberos, Sentry, TLS/SSL, |
| Use Case | Data Warehouse |
- part (but not all) of a given dataset must be shared but at a very granular level—not only files, but specific columns and rows within tables;
- the number of clusters needed to support the per-user (or per-user group with the same permissions) would be too costly and unmanageable;
- casual users do not want to learn about cloud infrastructure, or spin-up their own clusters, or wait for a cluster to start up; or
- users want to get access to cluster quickly, based on their identity in the organization’s enterprise directory.
The best practices included in this section are the same as Cloudera recommendations for conventional on-premises clusters with some exceptions, where support for the Amazon S3 storage is not yet fully implemented in a Hadoop ecosystem component or security mechanism.
Example Use Case
Results from many ETL pipelines converge in Impala tables hosted on Amazon S3 for use by various subdivisions and teams within the organization. The Impala tables comprise what amounts to a vast data store used to derive everything from financial reports and sales-team bonuses, to operational dashboards and performance metrics for management.
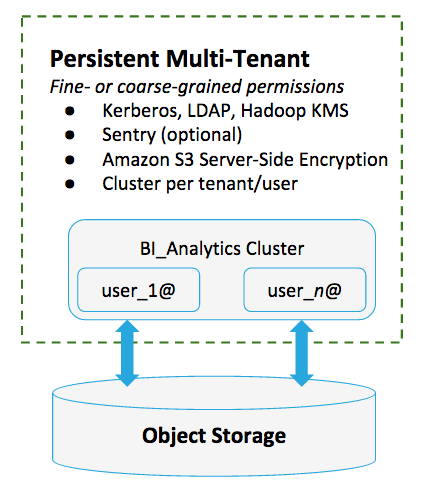
Access permissions to the system vary by user, team, and division. Privileges can also vary by subset of data in the tables. See Using Impala with the Amazon S3 Filesystem for details.
Identity
Cloudera recommends using your organization’s identity-management infrastructure so you can leverage your organization's existing users and groups instead of creating new ones. Organizations with existing LDAP directory services (Microsoft Active Directory, OpenLDAP) can integrate these with Amazon Web Services. This allows user’s directory group membership to determine what data they are allowed to access within the cluster, and it also eliminates the need for separate passwords for end-users. See How-to: Deploy a Secure Enterprise Data Hub on AWS and How-to: Deploy a Secure Enterprise Data Hub on AWS (Part 2) for more information.
For small workgroups, the Linux user/group directory can be used instead of an external enterprise directory.
Authentication
- Enable Kerberos and use LDAP/Active Directory to support login credentials. Use your existing Active Directory (see How-to: Deploy a Secure Enterprise Data Hub on AWS for more information).
- Use the Altus Director client in combination with the appropriate cluster configuration file to create and deploy a Kerberized cluster. See How-to: Deploy a Secure Enterprise Data Hub on AWS (Part 2) for an example.
- Do not give non-admin users root access to any of the nodes and do not allow them to directly access or manage any AWS compute resources. Instead, grant non-admin users (through their LDAP credentials) login privileges to specific edge nodes and client services.
- Create an EC2 instance;
- Setup a Windows domain controller (domain controllers host the Active Directory service instance) on that EC2 instance;
- Configure the domain controller to obtain its LDAP objects from your on-premises directory tree.
Authorization
When all users are allowed to access all data that the cluster can access, using Sentry for authorization is not necessary. However, if different users have different privileges, Cloudera recommends using Sentry for authorization. Apache Sentry is a unified role-based access control (RBAC) service for Hadoop clusters. Sentry includes a service, a backend database, and plug-ins for various components in the Hadoop ecosystem, including Apache Hive, Hive Metastore/HCatalog, Apache Solr, Impala, and HDFS.
Various roles are defined and stored in Sentry’s database as mappings between user:group identities and Hadoop Group Mappings for the various components.
For example, the data warehouse running on a persistent cluster might be used by dozens of employees with the role bi_analyst while the role analyst_grade_v may be limited to a handful of senior staff who have spend privileges above $20,000 US. Although these two employee classes have some target systems in common, the privileges on the target component vary widely between the two roles.
Sentry requires Kerberos. Only trusted users (those who have been authenticated by Kerberos) can access the Sentry service to manage the system, define roles, and map roles to permissions.
Currently, each cluster requires its own Sentry service because permissions are managed separately, per cluster. See Authorization with Apache Sentry in Cloudera Security for details.
Encryption (Data in Transit)
- Encrypt pathways where credentials (such as Kerberos keytabs) flow. This includes Cloudera Manager agent hosts.
- Encrypt data traffic leaving the cluster, such as to and from Amazon S3 buckets.
- Encrypt all of the other pathways where data can flow within the cluster.
See How to Configure TLS Encryption for Cloudera Manager in Cloudera Security for details about configuring the Cloudera Manager server and agent host systems for encryption and browser connections to Cloudera Manager Admin Console for HTTPS.
For the specific components running on the cluster, such as Impala, Hive, or Hue, see component-specific details in Cloudera Security, starting with Configuring TLS/SSL Encryption for CDH Services.
In general, however, the process of configuring various services and role instances is much the same for each component. Typically, cluster administrators will use Cloudera Manager to enable TLS/SSL and specify the path and filename for the X.509 artifacts, such as JKS or PEM certificate store, truststore, private key, and password needed for the respective private keystore.
For example, this excerpt from a cluster’s core-site.xml file shows the property that enables TLS/SSL for connections to Amazon S3 storage:
<property>
<name>fs.s3a.connection.ssl.enabled</name>
<value>true</value>
<description>Enables or disables SSL connections to S3.</description>
</property>
Encryption (Data at Rest)
Always encrypt data at rest on production clusters. For persistent clusters deployed to the Amazon cloud, that may involve three different types of storage—Amazon S3, local storage (for the EC2 instance), and Amazon EBS (Elastic Block Storage) as auxiliary storage.
Amazon S3 Storage
Enable encryption for Amazon S3 storage using either SSE-KMS or SSE-S3.
Use Server-Side Encryption with AWS KMS–Managed Keys (SSE-KMS) SSE-KMS (supported as of Cloudera Manager/CDH 5.11) to retain complete control over the encryption key material, including generating your own key material using hardware-based solutions if you like. If you choose this approach, you must also set up AWS Key Management Service (AWS KMS).
If you prefer not to manage your own encryption keys, use Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3) (supported as of Cloudera Manager/CDH 5.10) and let AWS automatically assign, manage, and retrieve encryption keys (completely transparently) for your users.
See How to Configure Encryption for Amazon S3 in Cloudera Security for information about configuring either of these encryption mechanisms.
Local Storage (HDFS on the Amazon EC2 Instance)
Encrypt data within the cluster itself by using HDFS Transparent Encryption for the local storage associated with the EC2 instances that comprise the nodes of the cluster. The instance store is ephemeral. It exists for the duration of the EC2 instance, in other words, for the lifetime of the persistent or long-running cluster.
Auxiliary Storage (Amazon EBS)
Amazon Elastic Block Store (Amazon EBS) is persistent storage that can be added to an EC2 instance—an EBS volume can be added to a running cluster to support HDFS processing.
Use EBS Encryption for any EBS volumes you add to the cluster. Disk I/O, snapshots from the volume, and the data at rest on the volume itself are all encrypted using the key you configure (with the AWS Key Management Service ). See Using EBS Volumes for Cloudera Manager and CDH for more information.
See Protecting Data at Rest in Cloudera Security for an overview of all mechanisms available to Cloudera clusters and HDFS, including encryption for data spills.
Auditing
- Enable Amazon S3 logging to record S3 events emitted by AWS. By default, this feature is disabled but can be enabled through the AWS Management Console for the Amazon S3 bucket. See AWS documentation Server Access Logging for details. According to Amazon, server logs can provide “an idea of the nature of traffic against your bucket” but are not meant as “a complete accounting of all requests.”
- Use Cloudera Navigator to audit the local storage for the EC2 instances and any auxiliary storage on EBS volumes. For Amazon S3 storage, Cloudera Navigator currently collects technical metadata only, such as source type (S3), type , bucket, path, region, owner, S3 encryption, and other object-related attributes. See Cloudera Navigator Auditing (in Cloudera Data Management documentation) for information about Cloudera Navigator functionality for HDFS backed clusters.
See Auditing Mechanisms for Cloudera Clusters for an introduction to Cloudera Navigator.
See Cloudera Data Management for configuration and usage details.
Persistent Multi-Tenant Clusters Using HDFS
| Architectural Pattern | Persistent multi-tenant clusters backed by HDFS |
| Cluster Services | HBase, Apache Hive, Hive on Spark, and HDFS |
| Dependencies | Kerberos, Sentry, TLS/SSL |
| Use Case | Operational Database |
Persistent multi-tenant clusters backed by HDFS are recommended for operational databases and other use cases that demand exceptionally fast performance, inherent transactional support (that is, without the need to augment Amazon S3’s eventual consistency model), or when you want to use client-side encryption available with HDFS transparent encryption and have complete control over all keys.
Example Use Case
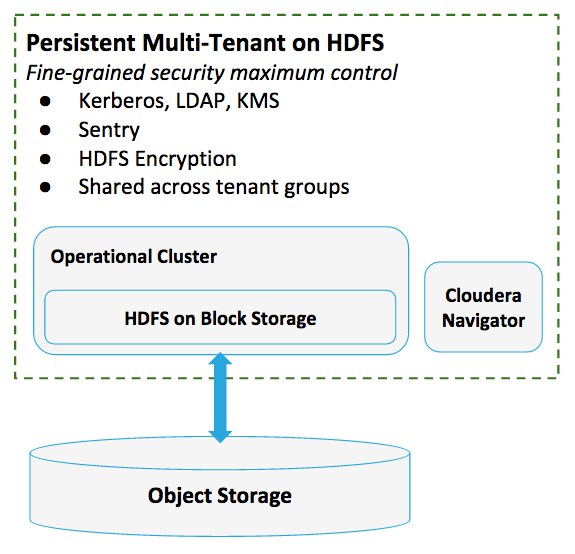
| Identity | Use your LDAP-compliant directory service (Microsoft Active Directory, OpenLDAP) as discussed in Persistent Multi-Tenant Clusters on Amazon S3 (the approach is much the same). See How-to: Deploy a Secure Enterprise Data Hub on AWS for more details. |
| Authentication | Use Kerberos (MIT Kerberos, Microsoft Active Directory) for authentication. |
| Authorization | Use Sentry and RecordService for role-based access control and fine-grained permissions to row- and column-data, respectively. |
| Encryption (data in transit) | Configure TLS/SSL for all the cluster and for all services and roles. See How to Configure TLS Encryption for Cloudera Manager for details. |
| Encryption (data at rest) | Use HDFS Transparent Encryption for data-at-rest encryption or Cloudera Navigator Encrypt. In either case, use Cloudera Navigator Key Trustee Server (KTS) to manage your encryption keys. To generate your own key material using a hardware security module (HSM), integrate your HSM with Navigator KTS by adding Cloudera Navigator Key HSM to your setup. |
| Auditing | Use Cloudera Navigator to log all events that affect data, to meet auditing, data lineage, and governance requirements. |
Identity
Organizations that use Microsoft Server for identity, directory, or authentication services can leverage these services when they deploy clusters to AWS. See How-to: Deploy a Secure Enterprise Data Hub on AWS for details.
Authentication
- Create an EC2 instance and set up Windows Server as a domain controller on that instance.
- Create the instance in the same VPC you plan to use for both Altus Director and for the cluster.
- Configure the domain controller so that it obtains its directory service database from your on-premises directory service instance (the Active Directory on-premises forest).
For faster deployment, Altus Director client (bootstrap command) or Altus Director server (bootstrap-remote) with the appropriate version of the configuration file (aws.kerberos.sample.conf, modified for your specifics) to create and deploy a cluster pre-configured to integrate with your site’s Kerberos key server.
The configuration file assumes that the Kerberos KDC (key distribution center) is already set up and running, and that it is reachable by the Altus Director instance.
- How-to: Deploy a Secure Enterprise Data Hub on AWS: This post shows you how to integrate any cluster, on-premises or in the AWS cloud, with an existing Active Directory instance. The post also discusses leveraging Centrify with Active Directory for Linux user ID authentication, and how to use Microsoft Active Directory Certificate Services to handle X.509 certificates needed by TLS/SSL.
- How-to: Deploy a Secure Enterprise Data Hub on AWS (Part 2): This post builds on the first, showing you how to use Altus Director to deploy the cluster using configuration files. The post includes a step-through of a custom bootstrap script and how it installs and configures DNS, dependency packages, Java (JDK and cryptography extensions), and other subsystems needed to join the hosts to the Active Directory domain controller, obtain and prepares certificates from ADCS, and completes all other tasks.
Authorization
Use Apache Sentry for role-based access to cluster components (see Authorization with Apache Sentry for more background).
Encryption (Data in Transit)
Always configure the cluster and all services to use TLS/SSL whether deployed on-premises or on clusters backed by Amazon S3. The blog post How-to: Deploy a Secure Enterprise Data Hub on AWS includes details, including how to obtain certificates using an offline multi-tier PKI setup (leveraging features of Windows Server). See also How to Configure TLS Encryption for Cloudera Manager.
Encryption (Data at Rest)
Encrypt data at rest for most use cases, especially when data contains patient medical records, customer financials, or any other type of sensitive personally-identifiable information (PII), trade secrets, classified information, and the like.
Cloudera supports using Amazon EBS for HDFS and using EBS encryption for data stored on EBS volumes.
For high availability, set up two Navigator KTS instances. A second on-premises cluster can share the same on-premises KTS as the cloud cluster. See Cloudera Navigator Key Trustee Server High Availability for details.
- Set up Cloudera Navigator Key Trustee Server on-premises.
- Set up the Key Management Service (KMS) to point to the on-premises KTS (using Cloudera Manager). (To mitigate latency between the on-premises cluster and the cloud, Hadoop KMS maintains a local cache of encryption keys).
Auditing
Use Cloudera Navigator to audit service access events. Audit events capture activities occurring at the cluster, host, role, service, or user level, recording the events in a central repository for viewing, filtering, and exporting through the Navigator UI. Event details include dozens of available attributes, such as user name, IP address of the host on which the event occurred, service name, session ID, object type, delegation token ID, and commands invoked (HBase, HDFS, Hive, Hue, Impala, Sentry, Solr, among others).
On-going Security Best Practices
After you deploy production workloads to the cloud, the real test of security begins. Here are some other general recommendations:
- Before running a production workload in the cloud, step-through the perimeter check detailed in How to secure ‘Internet exposed’ Apache Hadoop.
- Regularly visit the Cloudera Security Bulletins
page to find out about known security issues that may arise.
- Customers with support contracts are notified directly by Cloudera whenever a security issue arises.
- Customers without support contracts should pro-actively monitor Cloudera Security Bulletins on a regular basis.
- Get active in the Cloudera Community to learn more about clusters and the cloud.
- Read the Cloudera Engineering Blog and get hands-on guidance from Cloudera engineers for a wide range of cluster deployment, management, and security tasks, both on-premises and cloud.