Troubleshooting Altus Director
This topic contains information on problems that can occur when you set up, configure, or use Altus Director, their causes, and their solutions.
Viewing Altus Director Logs
- Altus Director client
- One shared log file per user account:
$HOME/.cloudera-director/logs/application.log
- One shared log file per user account:
- Altus Director server
- One file for all clusters:
/var/log/cloudera-director-server/application.log
- One file for all clusters:
- Altus Director client: /etc/cloudera-director-client/logback.xml
- Altus Director server: /etc/cloudera-director-server/logback.xml
<root level="DEBUG">
<logger name="com.cloudera.launchpad" level="DEBUG"/>
The logback.xml file can be reconfigured in many other ways to adjust how logging is performed. See Logback configuration in the Logback project documentation to learn more. Note that major changes to log format and contents will hamper the effectiveness of Cloudera Support, if you should need to forward logs to them as part of troubleshooting.
Routing Server Logs to Separate Log Files
By default, the Altus Director server sends all log messages to a single file: /var/log/cloudera-director-server/application.log. This can make troubleshooting challenging when Director works with multiple clusters at once because log messages about all of the different cluster activities are combined and interlaced in a single file.
When the name of the environment, deployment, or cluster is available, the Director server records the name in each thread that handles an API call. You can configure server logging so that log messages generated by specific API calls are routed to separate log files based on the environment, deployment, and cluster names included in the thread.
The Director server also records the names of certain background tasks, such as those that periodically refresh its deployment and cluster states, in threads that execute those tasks. You can also configure server logging so that log messages pertaining to those tasks are routed to separate log files.
The Director server uses the logback logging library to route log messages to files. You can use the server logback.xml file to define a discriminator that determines where to send a message. You can set only one discriminator at a time, but the value is selected from one of several configured subkeys. The first subkey whose target content is recorded in a thread determines the value of the discriminator.
Threads that do not include a discriminator are sent to the standard application.log file. All logs files are created in the directory configured for the main application.log file.
| Item | Description |
|---|---|
| environmentName |
Environment name included in the thread. Example: env123 |
| deploymentName |
Deployment name included in the thread. Example: depl456 |
| clusterName |
Cluster name included in the thread. Example: cluster789 |
| deploymentKey |
The combination of the environment and deployment names included in the thread, separated by double underscores (__). Example: env123__depl456 |
| clusterKey |
The combination of the environment, deployment, and cluster names included in the thread, separated by double underscores (__). Example: env123__depl456__cluster789 |
| task |
The name of the task included in the thread. Example: refreshDeployments |
The server logback.xml file includes an example sifting appender that logs task and cluster activity into separate log files named after each task and cluster. Uncomment that appender, and comment the non-sifting appender, and then restart the server to start logging to separate files by task and cluster name. Edit the appender configuration to sift logs by a different discriminator.
Configuring Tag-on-create for AWS GovCloud (US) and China (Beijing) Regions
In most AWS regions, Altus Director assigns a tag during the creation of each instance it creates to facilitate instance management. The GovCloud (US) and China (Beijing) regions do not support tagging of instances on creation, so for instances in these regions, the tag is created after the instance is created.
useTagOnCreate: false
The aws-plugin.conf file can be found at /var/lib/cloudera-director-plugins/aws-provider-plugin_version/etc/ on your Altus Director EC2 instance.
Backing Up the H2 Embedded Database
/var/lib/cloudera-director-server/state.h2.db
Back up the state.h2.db file to avoid losing environment and cluster data. To ensure that your backup copy can be restored, use the H2 backup tools instead of simply copying the file. For more information, see the H2 Tutorial.
Bootstrap fails in Azure when custom image has an attached data disk and dataDiskCount is not 0
Symptom
Bootstrap fails in Azure when a custom image is used that has an attached data disk and dataDiskCount is not set to 0. The error message displayed is, "Cannot specify user image overrides for a disk already defined in the specified image reference."
Cause
This error originates in Azure. It occurs because the Azure image has a data disk attached, while the dataDiskCount value wrongly indicates that Altus Director is trying to attach an additional disk or disks. The conflict causes an error to be thrown.
Solution
If you deploy a cluster in Azure with a custom image that has a data disk attached, you must set dataDiskCount to 0. You can use the Azure Portal to check if your custom image has a data disk attached. If you simply comment out the dataDiskCount setting, it will default to 5. Bootstrap fails if the dataDiskCount value is not 0. See Deploying Clusters with Custom Images.
Slow or Failed OS Updates in Some AWS Regions
Symptom
In AWS, Altus Director triggers operating system updates and performs software downloads on instances it allocates in your chosen region. Depending on the local network configuration, these updates and downloads might go slowly or fail.
Solutions
-
Disable instance normalization. This causes Altus Director to not perform usual automated, general work on new instances. You should replace that work with your own, either by building a custom AMI with the work already accomplished, or by using a bootstrap script. Normalization can be disabled using a configuration file.
-
Create a preloaded AMI. Altus Director can avoid downloading Cloudera Manager and CDH software if it is already present in expected locations on instances. This also speeds up deployment and cluster bootstrap processes, even when download speeds from Cloudera repositories are reasonable. See the documentation for more information.
-
Mirror Cloudera repositories. Instead of preloading an AMI with Cloudera software, you can host them at local mirrors, and point Altus Director to them as alternative download locations. As with preloaded AMIs, taking this step can speed up bootstrap processes, and make your architecture less vulnerable to network problems. See the documentation for more information.
Altus Director Bootstrap Fails with DNS Error
Altus Director Bootstrap Fails with IAM Permissions Error
Symptom
ErrorInfo{code=PROVIDER_EXCEPTION, properties={message=User:
arn:aws:sts::code:assumed-role/ClouderaDirector-Director-instance
is not authorized to perform: iam:GetInstanceProfile on resource: instance profile test}Solution
Configure the required IAM permissions. Check the list of required IAM permissions: Creating AWS Identity and Access Management (IAM) Policies.
Cloudera Manager API Call Fails
Altus Director Cannot Manage a Cluster That Was Kerberized Through Cloudera Manager
Symptom
Altus Director cannot manage a cluster after Cloudera Manager is used to enable Kerberos on the cluster.
Cause
Once a cluster is deployed through Altus Director, some changes to the cluster that are made using Cloudera Manager cause Altus Director to be out of sync and unable to manage the cluster. See Altus Director and Cloudera Manager Usage.
RDS Name Conflicts
New Cluster Fails to Start Because of Missing Roles
Cause
Altus Director does not validate that all required roles are assigned when provisioning a cluster. This can lead to failures during the intial run of a new cluster. For example, if the gateway instance group was removed, but the Flume Agent and Kafka Broker were assigned to roles in that group, the cluster fails to start.
Altus Director Server Will Not Start with Unsupported Java Version
Symptom
Exception in thread "main" java.lang.UnsupportedClassVersionError: com/cloudera/launchpad/Server : Unsupported major.minor version 51.0
Cause
You are running Altus Director server against an older, unsupported version of the Oracle Java SE Development Kit (JDK).
Solution
Update to a supported version of the Oracle JDK. For information on supported versions, see Supported Software and Distributions.
Error Occurs if Tags Contain Unquoted Special Characters
Symptom
com.typesafe.config.ConfigException$WrongType: ... <x> has type OBJECT rather than STRING
DNS Issues
Symptom
[27/Mar/2017 20:26:16 +0000] 12596 Thread-13 https ERROR Failed to retrieve/store URL: http://ip-10-202-202-109.ec2.internal:7180/cmf/parcel/download/CDH-5.10.0-1.cdh5.10.0.p0.41-el7.parcel.torrent -> /opt/cloudera/parcel-cache/CDH-5.10.0-1.cdh5.10.0.p0.41-el7.parcel.torrent <urlopen error [Errno -2] Name or service not known>
Cause
- DNS Hostnames is not set to Yes in the Edit DNS Hostnames VPC configuration setting.
- The Amazon Virtual Private Cloud (VPC) is not set up for forward and reverse hostname resolution. Forward and reverse DNS resolution is a requirement for many components of the Cloudera EDH platform, including Altus Director.
In the AWS Management Console, go to and click VPC. In the VPC Dashboard, select your VPC and click Action. In the shortcut menu, click Edit DNS Hostnames and click Yes. If this does not fix the issue, continue with the instructions that follow to configure forward and reverse hostname resolution.
python -c "import socket; print socket.getfqdn(); print socket.gethostbyname(socket.getfqdn())"
For more information on DNS and Amazon VPCs, see DHCP Options Sets in the Amazon VPC documentation.
-
Log in to the AWS Management Console.
-
Select VPC from the Services navigation list box.
-
In the left pane, click Your VPCs. A list of currently configured VPCs is displayed.
-
Select the VPC you are using and note the DHCP options set ID.
-
In the left pane, click DHCP Option Sets. A list of currently configured DHCP Option Sets is displayed.
-
Select the option set used by the VPC.
-
Check for an entry similar to the following and make sure the domain-name is specified. For example:
domain-name = ec2.internal domain-name-servers = AmazonProvidedDNS
-
If it is not configured correctly, create a new DHCP option set for the specified region and assign it to the VPC. For information on how to specify the correct domain name, see the AWS Documentation.
Server Does Not Start
Solution
Run Altus Director on an instance that has at least 1 GB of free memory. See Resource Requirements for more details on Altus Director hardware requirements.
Problem When Removing Hosts from a Cluster
Cause
You are trying to shrink the cluster below the HDFS replication factor. See How to Remove Instances from a Cluster (Note) for more information about replication factors.
Problems Connecting to Altus Director Server
Cause
Configuration of security group and iptables settings. For more information about configuring security groups, see Preparing Your AWS EC2 Resources. For commands to turn off iptables, see either Installing Altus Director Server and Client on the EC2 Instance or Installing Altus Director Server and Client on Google Compute Engine. Some operating systems have IP tables turned on by default, and they must be turned off.
Shrinking an H2 Database
If you use an H2 database for Altus Director's data, the database should not be larger than a few megabytes. The H2 database grows when Altus Director runs over a long period of time because the database is not able to reclaim disk space when entries are deleted. As the database file grows larger, the risk of database corruption increases.
- Back up the existing H2 database file.
- Stop Altus Director.
- Make a backup script using H2's Script command:
# Make a backup script (backup.zip) # NOTE: Do not include ‘.h2.db’ when specifying the db file $ java -cp <h2 jar file> org.h2.tools.Script -url \ "jdbc:h2:/var/lib/cloudera-director-server/state;MV_STORE=false; \ MVCC=true;DB_CLOSE_ON_EXIT=TRUE;AUTO_SERVER=TRUE;TRACE_LEVEL_FILE=4;TRACE_LEVEL_SYSTEM_OUT=0" \ -user sa -password sa -script backup.zip -options compression zip
- Delete the old database.
- Create a new, smaller database from the script using H2's RunScript command:
# Create a new database from the script (backup.zip) # NOTE: Do not include ‘.h2.db’ when specifying the db file $ java -cp <h2 jar file> org.h2.tools.RunScript -url \ "jdbc:h2:/var/lib/cloudera-director-server/state;MV_STORE=false; \ MVCC=true;DB_CLOSE_ON_EXIT=TRUE;AUTO_SERVER=TRUE;TRACE_LEVEL_FILE=4;TRACE_LEVEL_SYSTEM_OUT=0" \ -user sa -password sa -script backup.zip -options compression zip
- Start Altus Director.
For more information on H2 databases, see the H2 documentation at H2 Database Engine.
Migrating the Altus Director Database from H2 to MySQL Without Using the copy-database Script
Altus Director provides a script to move Altus Director data from one database to another database. You can use the copy-database script to move data from the default H2 database to a MySQL database. For more information about the copy-database script, see Migrating the Altus Director Database.
Step 1: Prepare databases
- Stop Altus Director and back up the H2 database file, state.h2.db. The H2 database file is located at /var/lib/cloudera-director-server/state.h2.db.
- Create a user on the MySQL server for Altus Director:
CREATE USER director IDENTIFIED BY password;
- Create a database on the MySQL server for exporting the data from H2:
CREATE DATABASE directorexport CHARACTER SET utf8; GRANT ALL PRIVILEGES ON directorexport.* TO 'director'@'%';
- Create a database on the MySQL server for use by Altus Director:
CREATE DATABASE director CHARACTER SET utf8; GRANT ALL PRIVILEGES ON director.* TO 'director'@'%';
Step 2: Export data from H2 database
- Install SQuirreL SQL.
- Download SQuirreL SQL from the SQuirreL SQL web site.
- Install SQuirreL SQL with the H2 and MySQL database plugins enabled.
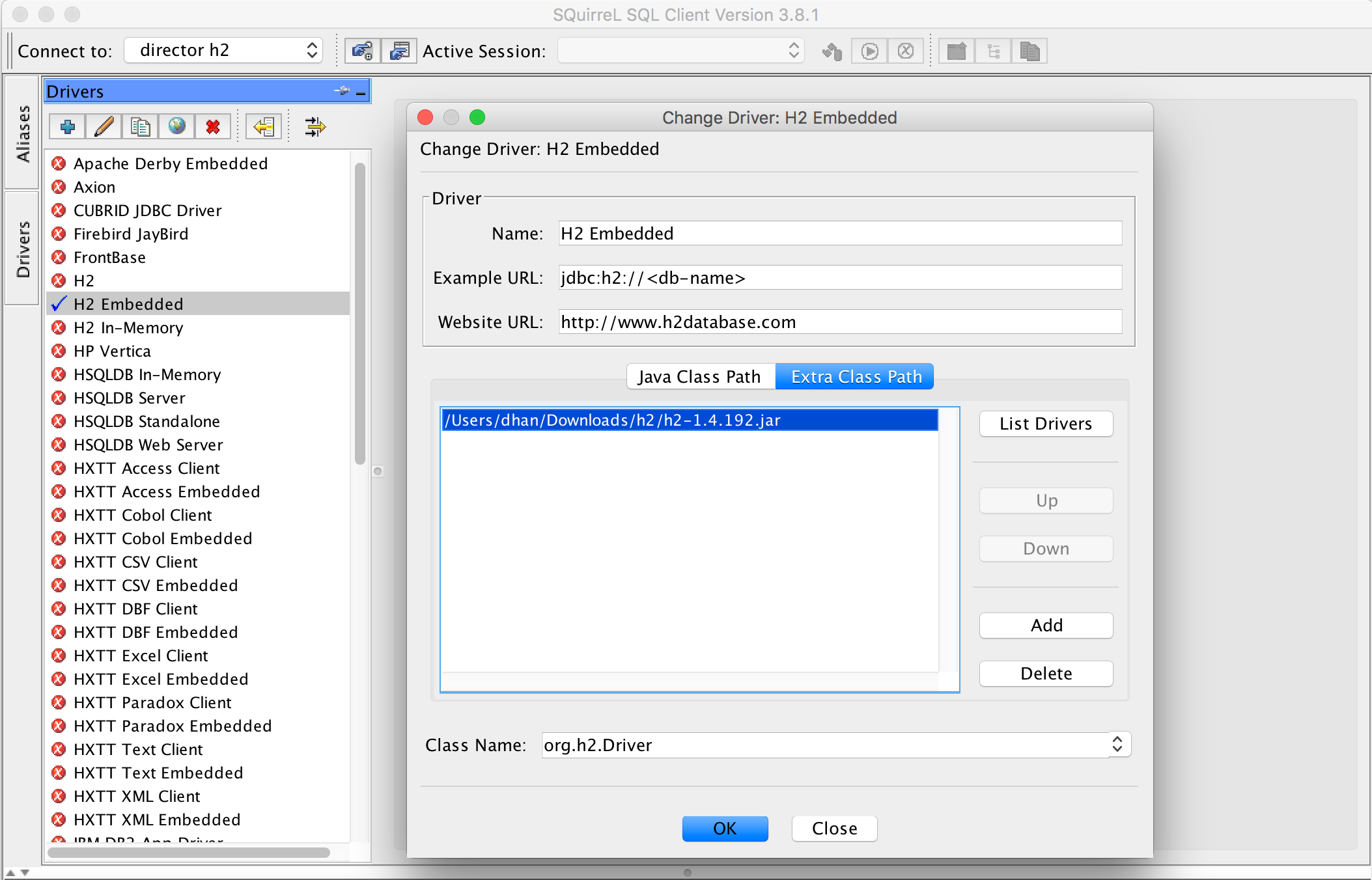
- Enable the H2 Embedded driver in SQuirreL SQL.
- Download H2 from http://www.h2database.com/html/download.html.
- Edit the H2 Embedded driver, adding the downloaded jar file to the Extra Class Path.
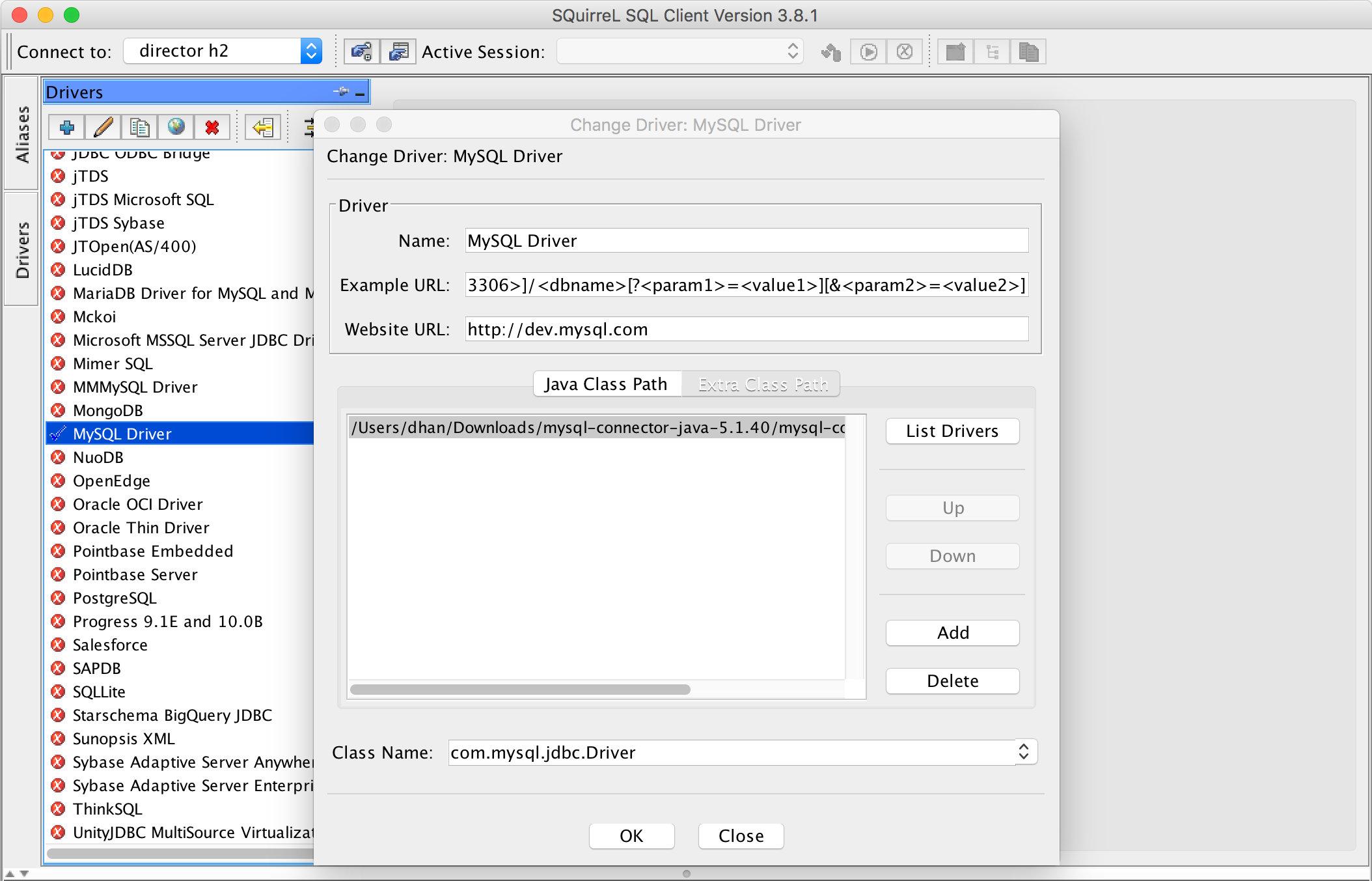
- Enable the “MySQL Driver” driver in SQuirreL SQL.
- Download the MySQL driver from the MySQL Downloads site.
- Edit the “MySQL Driver” driver, adding the MySQL connector jar to the Extra Class Path.
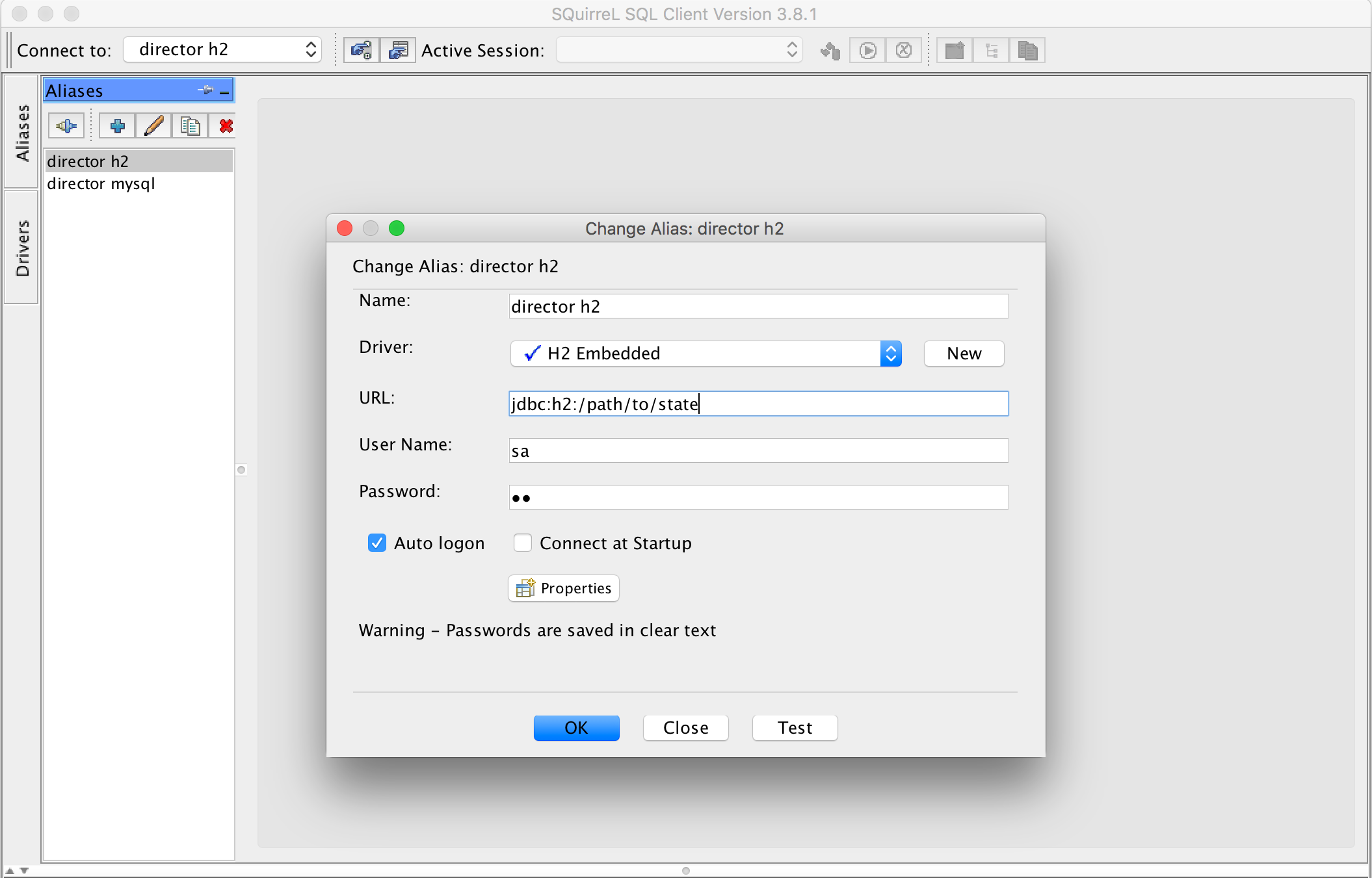
- Create an alias for the H2 database. Test the connection to make sure you can connect to the database.
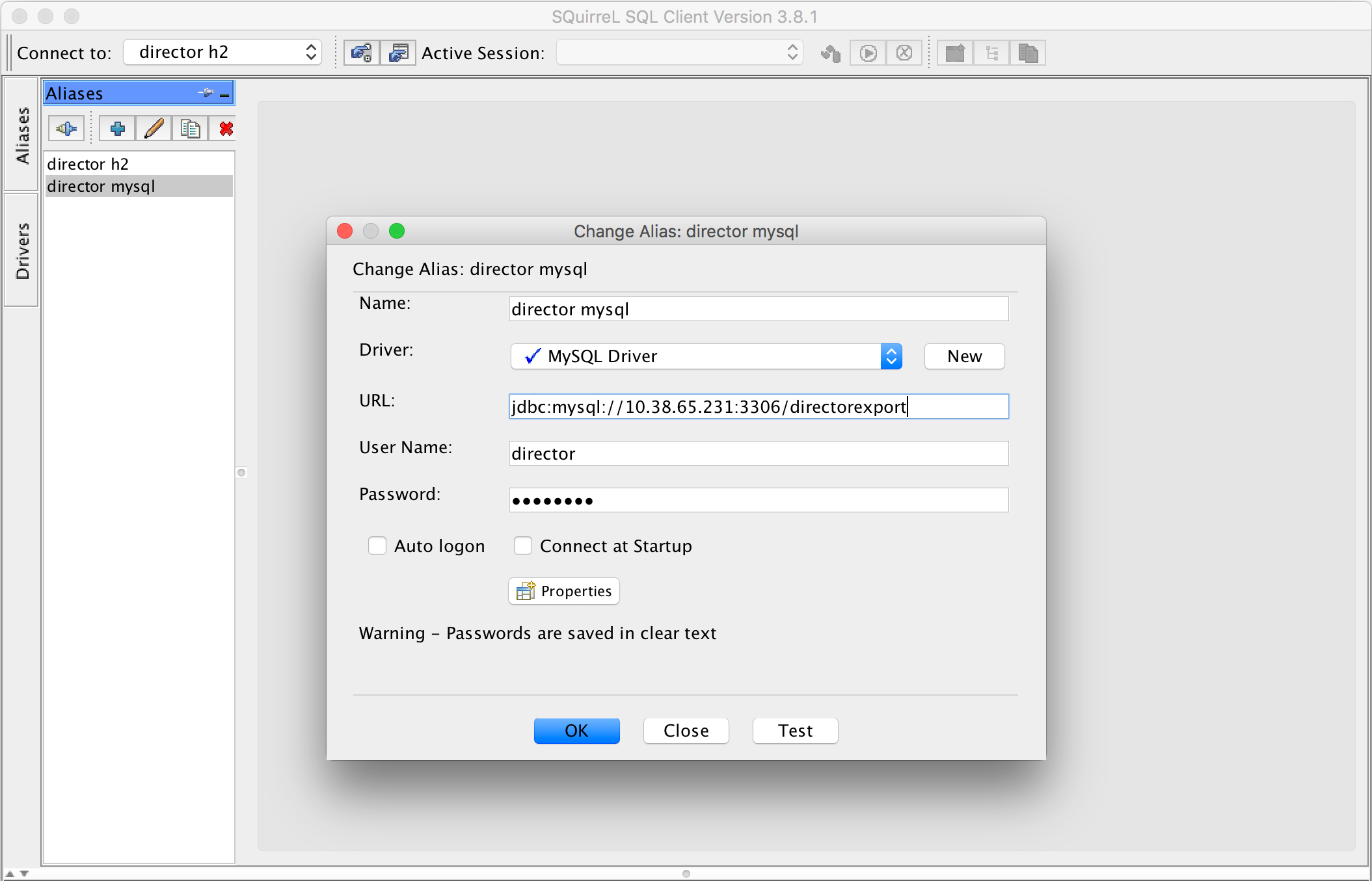
- Create alias for MySQL data export database. Test the connection to make sure you can connect to the database.
- Prepare the H2 database for data export. H2 generates names for indexes that are longer than what is permitted in MySQL, so you must rename the indexes in H2 to ensure that they do not
violate the MySQL length limit. For example:
ALTER INDEX DEPLOYMENTS_UNIQUE_PER_ENVIRONMENT_BY_DEPLOYMENT_NAME_INDEX_8 RENAME TO DEPLOYMENTS_UNIQUE_PER_ENVIRONMENT_BY_DEPLOYMENT_NAME ALTER INDEX UK_EXTERNAL_DATABASE_SERVERS_UNIQUE_PER_ENVIRONMENT_BY_NAME_INDEX_8 RENAME TO UK_EXTERNAL_DATABASE_SERVERS_UNIQUE_PER_ENVIRONMENT_BY_NAME
- Prepare MySQL for data export.
- Depending on the Altus Director and MySQL versions you are running, you might need the following step. If you see the error message invalid default value
after performing the next step, you need to do this. Otherwise, this step is optional.
select @@global.sql_mode // Keep the value somewhere if you would like to restore the value // at the end of this procedure. (See step 9c below.) set @@global.sql_mode = "..."; // remove NO_ZERO_IN_DATE,NO_ZERO_DATE from previous value.
- Reconnect to the MySQL alias for this change to apply to your session.
- Depending on the Altus Director and MySQL versions you are running, you might need the following step. If you see the error message invalid default value
after performing the next step, you need to do this. Otherwise, this step is optional.
- Export data from H2 to MySQL.
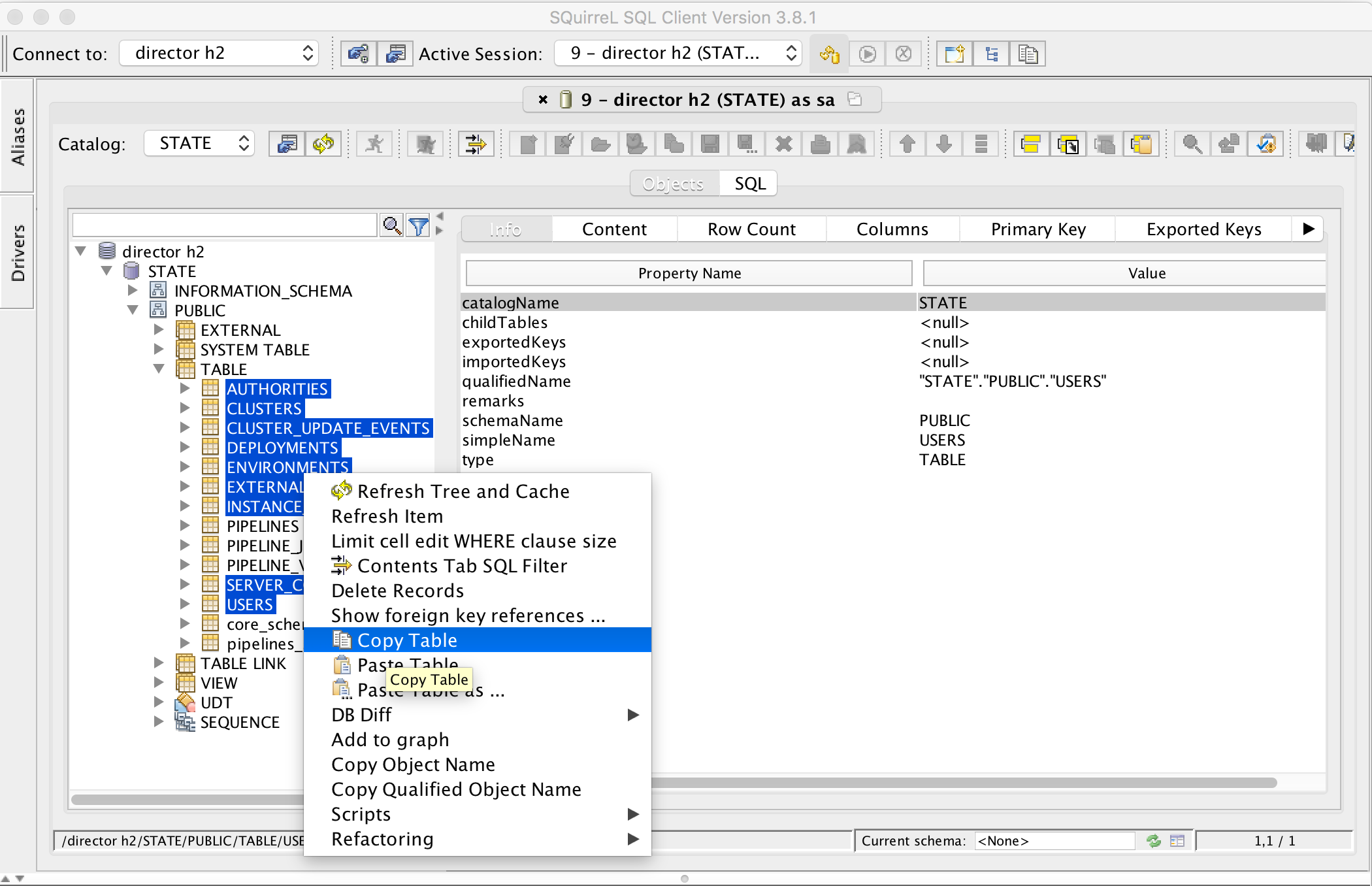
- Go to the Alias pane in SQuirreL SQL, and connect to H2.
- Go to . Select all tables except for the PIPELINES* and *schema_versions tables, right click and select
Copy Table.
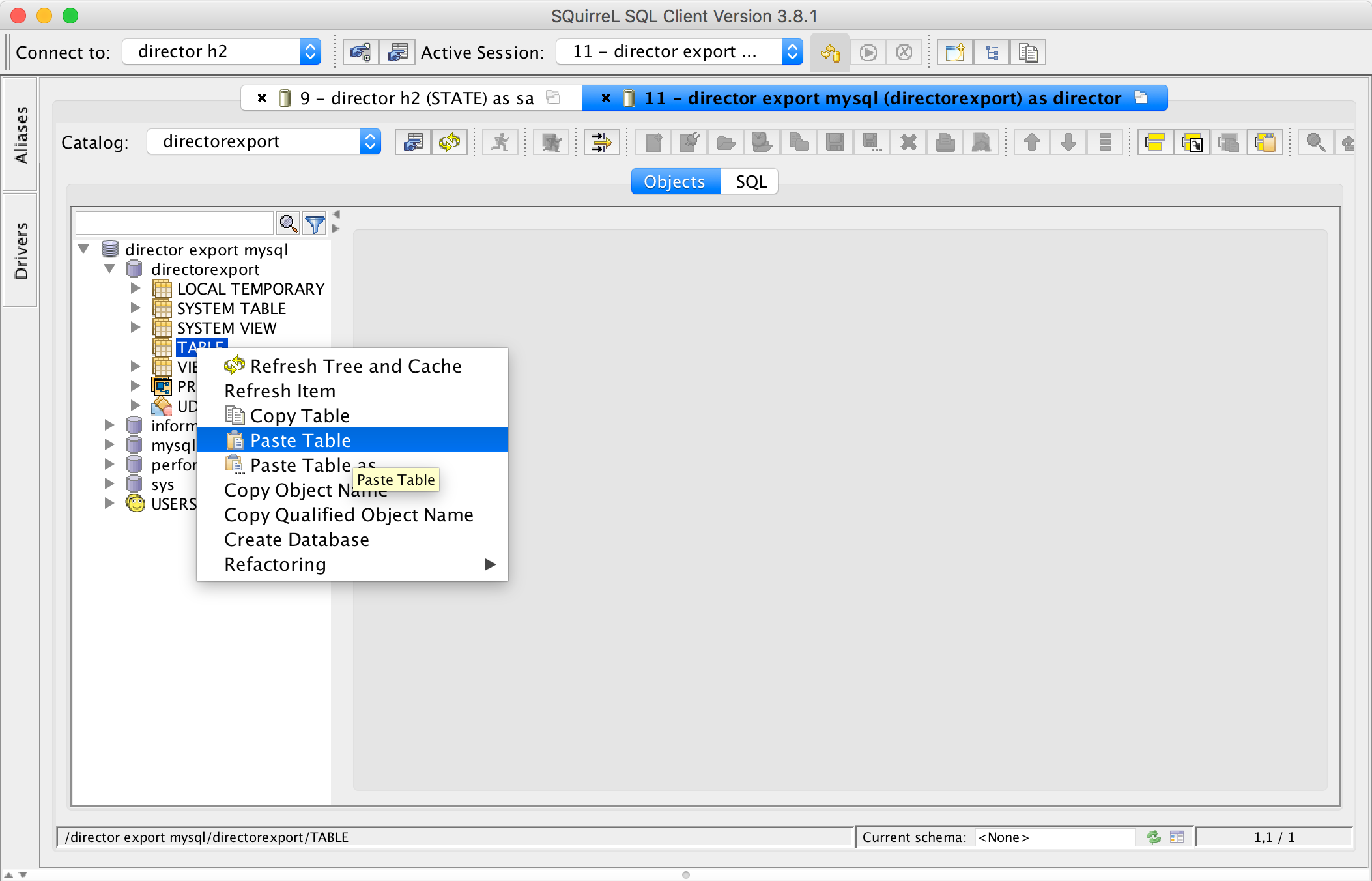
- Go to the Alias pane in SQuirreL SQL and connect to MySQL.
- Go to ,
right click TABLE and select Paste Table.
- Restore sql_mode, if desired (for more about sql_mode, see Prepare MySQL for data export above).
Step 3: Prepare MySQL database for data import
- Configure Altus Director to use MySQL, as described in Configuring Altus Director Server to use the MySQL Database.
- Start Altus Director with MySQL. When Altus Director starts, the database schema will be created.
- Stop Altus Director to prevent modification of the database during data import.
- Delete all values from the AUTHORITIES, USERS, and SERVER_CONFIGS tables. Altus Director populates these tables with some values by default. These values should be deleted so they will
not conflict with the imported data.
DELETE FROM AUTHORITIES; DELETE FROM USERS; DELETE FROM SERVER_CONFIGS;
Step 4: Import data to MySQL
- Dump the data only (no schema) from the export database. You can use the -h option if running mysqldump against a remote
host.
$ mysqldump -u [user] -p --no-create-info directorexport > directorexport.sql
- Import the data into Altus Director’s database. You may use the -h option if running mysql against a remote host.
$ mysql -u [user] -p director < directorexport.sql