Navigator Metadata Server Management
The Navigator Metadata Server is one of the two roles that provides Cloudera Navigator data management functionality. The Navigator Metadata Server manages, indexes, and stores entity metadata extracted from cluster services. Using policies defined by data stewards and others, the Navigator Metadata Server can tag entities with metadata or take other actions during the extraction process. It is the metadata that enables data discovery and data lineage functions for Cloudera Navigator.
This section starts with an overview of the Navigator Metadata Server system architecture and then covers administrator tasks that require Cloudera Manager Admin Console such as adding the Navigator Metadata Server role to an existing cluster, tuning for optimal performance, and setting up the LDAP or Active Directory groups to use Cloudera Navigator role-based access privileges.
Navigator Metadata Architecture
The figure below shows a high-level view of the key components that make up the Cloudera Navigator Metadata Architecture. Extracting, indexing, and storing metadata from cluster entities, both on-premises and in the cloud, are some of the important processes implemented by this architecture. As shown in the figure below, Cloudera Navigator can also extract metadata from entities stored on cloud services (Amazon S3) and from clusters running on Amazon EC2 or Cloudera Altus.
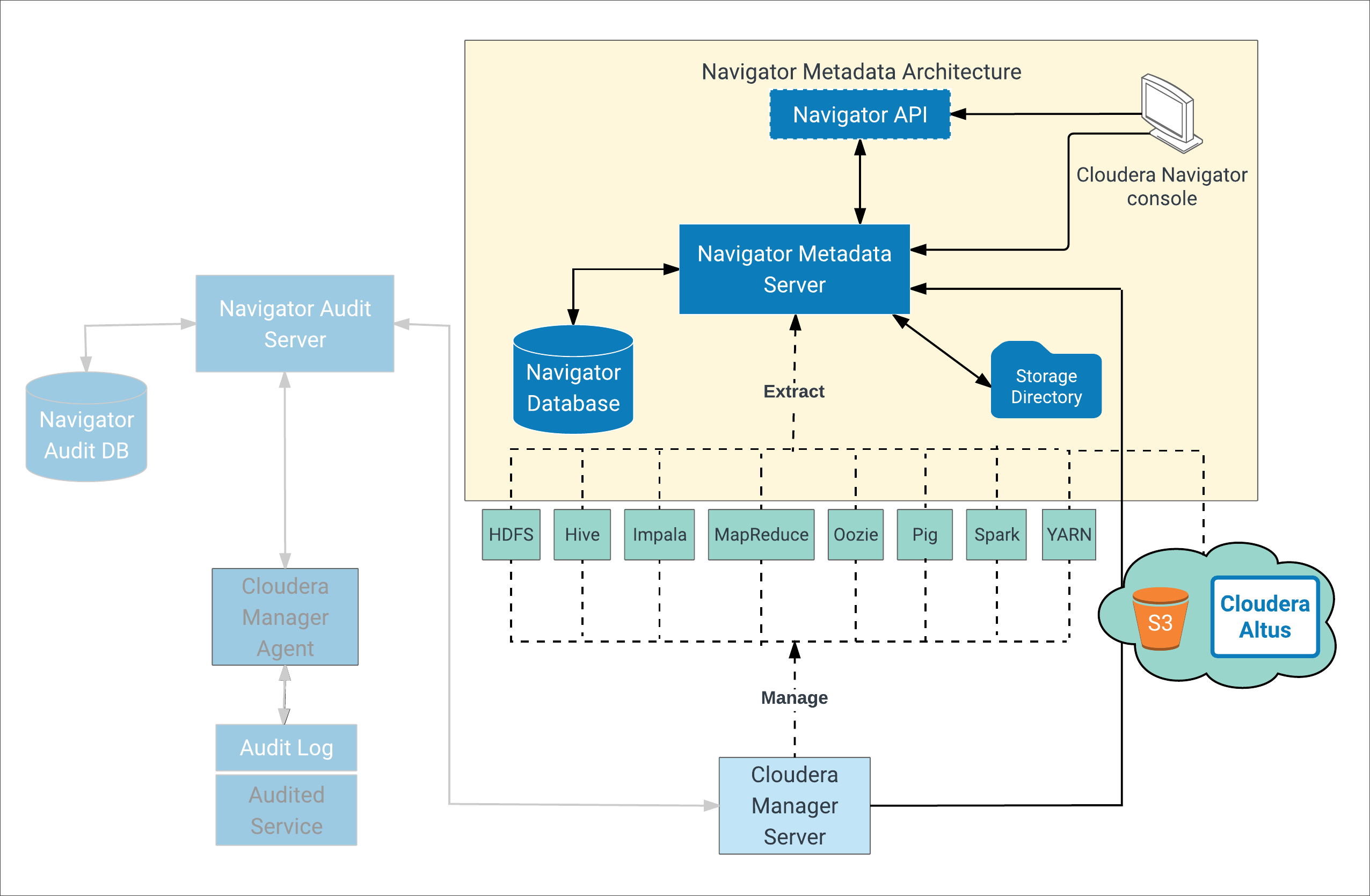
For example, a policy may specify that all Hive table entities with table name budget_2017 be tagged with the managed metadata property name finance-team, or that any entities with a file creation date (technical metadata) prior to 2014 be labeled with the prefix archive-yyyy, with the specific year obtained from the file creation date and applied to the label.
Extracted metadata is then indexed for later search using the embedded Solr instance. Solr Documents that comprise the index are stored on disk in the storage directory at the location configured in Cloudera Manager Admin Console for the Navigator Metadata Server datadir. See Services Supported for Metadata Extraction for more detail.
- Manages authorization data for Cloudera Navigator users
- Manages audit report metadata
- Generates metadata and audit analytics
- Exposes the Cloudera Navigator APIs
- Hosts the web server that provides the Cloudera Navigator console. (The web server and the console are also used to support the Cloudera Navigator Auditing services.)
The Navigator Database stores policies, user authorization and audit report metadata, and analytic data. Extracted metadata and the state of extractor processes is kept in the storage directory.
Services Supported for Metadata Extraction
| Resource Type | Metadata Extracted | Extraction Method |
|---|---|---|
| HDFS | HDFS metadata at the next scheduled extraction run after an HDFS checkpoint. If the cluster is configured for high availability (HA), metadata is extracted at the same time it is written to the JournalNodes. | Pull |
| Hive Server 2 | Query metadata is pushed to Navigator as queries occur. See Managing Hive and Impala Lineage Properties. | Push |
| Hive Metastore | Database asset metadata (database, tables, views, partitions, columns). See Managing Hive and Impala Lineage Properties. HMS entities include tables that result from Impala queries and Sqoop jobs. | Pull |
| Impala | Query metadata is pushed to Navigator from the Impala Daemon lineage logs. See Managing Hive and Impala Lineage Properties. | Push |
| MapReduce | Job metadata from the JobTracker. The default setting in Cloudera Manager retains a maximum of five jobs; if you run more than five jobs between Navigator extractions, the Navigator Metadata Server extracts the five most recent jobs. | Pull |
| Oozie | Oozie workflows from the Oozie Server. | Pull |
| Pig | Pig script runs from the JobTracker or Job History Server. | Pull |
| S3 | Bucket and object metadata. | Pull |
| Spark | Query metadata is pushed to Navigator as queries occur. Spark job metadata from YARN logs is pulled as part of the YARN extractor. Note that Spark 1.6, which is included with CDH, and CDS 2 Powered by Apache Spark include integration with Navigator. Third-party versions of Spark do not produce metadata for Navigator lineage. | Push |
| Sqoop 1 | Query metadata is pushed to Navigator as queries occur. Database and table metadata comes from the HMS extraction. | Push |
| YARN | Job metadata from the ResourceManager. | Pull |
Metadata Extraction Timing
The two types of Navigator extractors have different timing: Push extractors send metadata to Navigator after each event that generates metadata (Hive Server 2, Impala, Spark, Sqoop). Pull extractors run about every 10 minutes, when Navigator Metadata Server triggers them (Oozie, YARN, HDFS, HMS, S3). When the 10 minute mark comes around for a given service, Navigator checks to see if an extraction process is already running; if one is, Navigator resets the wait time without starting another extraction. Extractors for different services typically run simultaneously, inserting new metadata into Navigator in a regular cadence. However, extractor behavior and timing for HMS and HDFS can be more complicated because of the volume of metadata they collect in a single extractor run.
HMS Extraction
Navigator extracts metadata from Hive Metastore (HMS) through a pull extractor where Navigator Metadata Server triggers the extraction. Every time Navigator extracts HMS metadata, it reviews all databases for all data assets: tables, views, partitions, etc. There is no incremental extraction from HMS. When your HMS includes many databases and lots of assets, the extraction can take a long time: certainly more than the 10 minute extraction interval.
As it progresses through the extraction, Navigator creates new entities for any data assets that aren't already represented in Navigator.
HDFS Extraction
Navigator extracts metadata for HDFS from the namenode. After the initial extraction, Navigator users iNotify to extract changes to HDFS contents rather than re-extracting all entities again. The initial HDFS extraction process still requires a long period; subsequent extractions may be more likely to conform to the 10-minute pattern. If Navigator encounters an a iNotify failure, it will fall back to bulk extraction.
Calculating Lineage from Metadata
As described in detail in Lineage Generation Architecture, lineage is generated when Navigator combines the metadata for data assets (such as file, tables, views) with the metadata for operation executions (queries and jobs). Tables and views come from HMS extraction, while operation executions come from push extractors for Impala, Hive Server 2, Spark, YARN, and Sqoop. If any of the metadata is missing (not extracted yet), lineage relationships aren't calculated or displayed. For lineage relationships to be displayed completely, Navigator must have completed extraction from each of the services involved and then it must run a lineage calculation process called "linking."
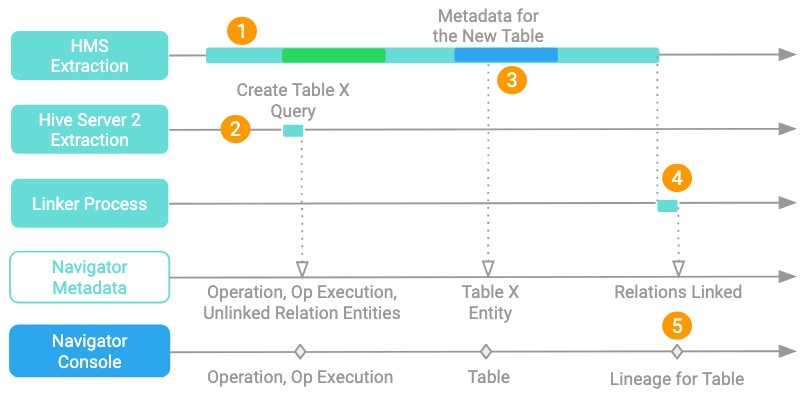
- HMS Extraction is a long-running process that steps through HMS one database at a time.
- Query engines such as Hive Server 2 push metadata updates to Navigator as soon as an event occurs: In this example, a query that creates table X is pushed to Navigator and Navigator creates an operation entity and an operation execution entity to represent the query. Navigator creates lineage relationship entities for the new table, but the relationships are left "unlinked" because the new table doesn't yet exist in Navigator.
- The HMS extraction gets to the database where the table was created and passes the metadata to Navigator, which creates a new entity for the table.
- After the HMS extraction finishes, Navigator triggers a linker process that reviews the "unlinked" lineage relations and connects them to the correct entities. Now the table created in step 2 is included in the lineage relationship created to describe the query.
- Lineage for the new table appears in the Navigator console.
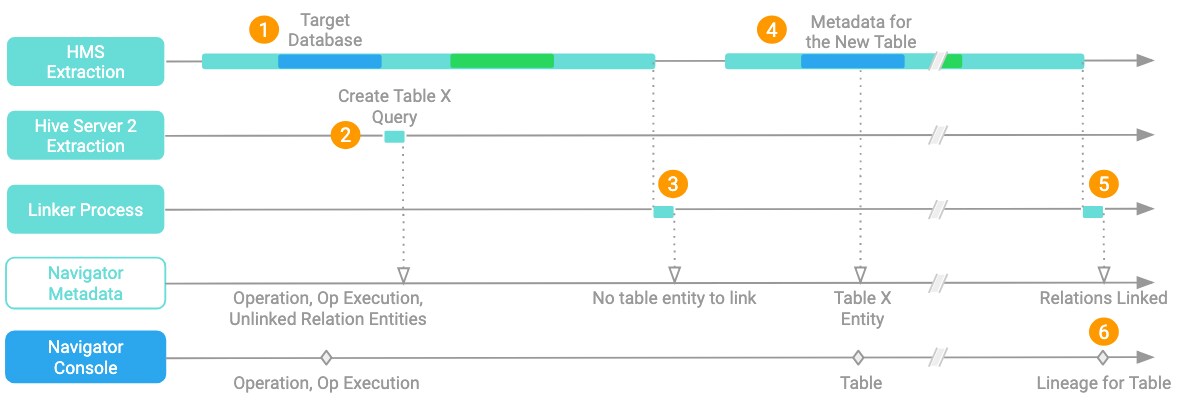
Note that step 3 is a variable here: it's possible that the HMS extraction run may have already processed the relevant database (1) before the query occurred (2). In that case, the HMS extraction would complete and linking would run (3), but there would not be an entity in place for the new table. Lineage for the new table doesn't appear until the next HMS extraction run reaches the relevant database (4) to create the table entity; then linking runs at the end of the HMS extraction (5) and adds the correct lineage information (6).
Troubleshooting
If Navigator is missing entities for:
- Queries: check the push extractor processing. The Navigator logs won't show any problems in this case. Instead, check the Cloudera Manager agent log on the host where the suspect service is running.
- Data asset entities: check the HMS pull extractor processing in the Navigator Metadata Server log.
- Filesystem entities: check the HDFS or S3 extractor processing in the Navigator Metadata Server log.
If Navigator is missing lineage, make sure that Navigator shows the entities for both the data assets and the queries that describe the lineage; then give enough time for the lineage processing to complete. If you still don't see lineage relations, check to make sure the linker is running (in the Navigator Metadata Server log). If HMS extraction never completes, you may see metadata for some data assets, but the linking process may not have been triggered. Check the Navigator Metadata Server log.
The pull extraction frequency can be configured using nav.extractor.poll_period in the Navigator Metadata Server Advanced Configuration Snippet (Safety Valve) for cloudera-navigator.properties in Cloudera Manager. Note that lowering the polling period won't affect latency if your system has one of the problems described here.
To find pull extractor events in the Navigator Metadata Server log, look for "extraction tasks for service", then filter further on the specific services you are interested in. For example:
2019-04-15 20:15:58,858 INFO com.cloudera.nav.extract.CdhClientExtractionTask [[ExtractorServiceExecutor-3] Cluster 1::HIVE-1]: Enqueuing 6 extraction tasks for service 'Cluster 1::HIVE-1'... 2019-04-15 20:26:00,095 INFO com.cloudera.nav.extract.CdhClientExtractionTask [[ExtractorServiceExecutor-3] Cluster 1::HIVE-1]: All cdh-client extraction tasks for service 'Cluster 1::HIVE-1' finished. 2019-04-15 20:35:58,882 INFO com.cloudera.nav.extract.CdhClientExtractionTask [[ExtractorServiceExecutor-7] Cluster 1::HIVE-1]: Enqueuing 6 extraction tasks for service 'Cluster 1::HIVE-1'... 2019-04-15 20:56:00,541 INFO com.cloudera.nav.extract.CdhClientExtractionTask [[ExtractorServiceExecutor-7] Cluster 1::HIVE-1]: All cdh-client extraction tasks for service 'Cluster 1::HIVE-1' finished. 2019-04-15 21:05:59,117 INFO com.cloudera.nav.extract.CdhClientExtractionTask [[ExtractorServiceExecutor-4] Cluster 1::HIVE-1]: Enqueuing 6 extraction tasks for service 'Cluster 1::HIVE-1'...
In this example, it took 10 minutes to finish the first extraction (20:26:00 - 20:15:58). Navigator waited 10 minutes to start the second extraction (20:35:58). The second extraction took 20 minutes to finish (20:56:00 - 20:35:58). The third extraction started 10 minutes after the second one finished (21:05:59), a total of 30 minutes after the start time of the second extraction.
Metadata Indexing
After metadata is extracted, the embedded Solr engine indexes it and makes it available for searching. The Solr instance indexes entity properties and the relations among entities. Relationship metadata is implicitly visible in lineage diagrams and explicitly available by downloading the lineage using the Cloudera Navigator APIs.
Data stewards and other business users explore entities of interest using the Cloudera Navigator console. Metadata and lineage that has been extracted, linked, and indexed can be found using Search. See Lineage, Metadata and other sections in this guide for Cloudera Navigator console usage information. The following sections focus on using the Cloudera Manager Admin Console for systems management tasks.