Migrating from MapReduce 1 (MRv1) to MapReduce 2 (MRv2, YARN)
This is a guide to migrating from Apache MapReduce 1 (MRv1) to the Next Generation MapReduce (MRv2 or YARN).
See the following sections for more information:
- Introduction
- Terminology and Architecture
- For MapReduce Programmers: Writing and Running Jobs
- For Administrators: Configuring and Running MRv2 Clusters
- Web UI
- Summary of Configuration Changes
- JobTracker Properties and ResourceManager Equivalents
- JobTracker Properties and JobHistoryServer Equivalents
- JobTracker Properties and MapReduce ApplicationMaster Equivalents
- TaskTracker Properties and NodeManager Equivalents
- TaskTracker Properties and Shuffle Service Equivalents
- Per-Job Configuration Properties
- Miscellaneous Properties
- MRv1 Properties that have no MRv2 Equivalents
Introduction
MapReduce 2, or Next Generation MapReduce, is a long needed upgrade to the way that scheduling, resource management, and execution occur in Hadoop. At their core, the improvements separate cluster resource management capabilities from MapReduce-specific logic. They enable Hadoop to share resources dynamically between MapReduce and other parallel processing frameworks, such as Impala, allow more sensible and finer-grained resource configuration for better cluster utilization, and permit it to scale to accommodate more and larger jobs.
This document provides a guide to both the architectural and user-facing changes, so that both cluster operators and MapReduce programmers can easily make the transition.
Terminology and Architecture
MapReduce from Hadoop 1 (MapReduce MRv1) has been split into two components. The cluster resource management capabilities have become YARN (Yet Another Resource Negotiator), while the MapReduce-specific capabilities remain MapReduce. In the MapReduce MRv1 architecture, the cluster was managed by a service called the JobTracker. TaskTracker services lived on each host and would launch tasks on behalf of jobs. The JobTracker would serve information about completed jobs.
In MapReduce MRv2, the functions of the JobTracker have been split between three services. The ResourceManager is a persistent YARN service that receives and runs applications (a MapReduce job is an application) on the cluster. It contains the scheduler, which, as previously, is pluggable. The MapReduce-specific capabilities of the JobTracker have been moved into the MapReduce ApplicationMaster, one of which is started to manage each MapReduce job and terminated when the job completes. The JobTracker function of serving information about completed jobs has been moved to the JobHistory Server. The TaskTracker has been replaced with the NodeManager, a YARN service that manages resources and deployment on a host. It is responsible for launching containers, each of which can house a map or reduce task.
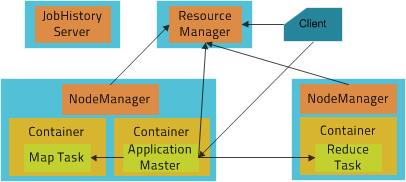
The new architecture has its advantages. First, by breaking up the JobTracker into a few different services, it avoids many of the scaling issues faced by MapReduce in Hadoop 1. More importantly, it makes it possible to run frameworks other than MapReduce on a Hadoop cluster. For example, Impala can also run on YARN and share resources with MapReduce.
For MapReduce Programmers: Writing and Running Jobs
Nearly all jobs written for MRv1 can run without any modifications on an MRv2 cluster.
Java API Compatibility
MRv2 supports both the old (mapred) and new (mapreduce) MapReduce APIs used for MRv1, with a few caveats. The difference between the old and new APIs, which concerns user-facing changes, should not be confused with the difference between MRv1 and MRv2, which concerns changes to the underlying framework. CDH 4 and CDH 5 both support the new and old MapReduce APIs.
| Binary Incompatibilities | Source Incompatibilities | |
|---|---|---|
| CDH 4 MRv1 to CDH 5 MRv1 | None | None |
| CDH 4 MRv1 to CDH 5 MRv2 | None | Rare |
| CDH 5 MRv1 to CDH 5 MRv2 | None | Rare |
The following are the known source incompatibilities:
- KeyValueLineRecordReader#getProgress and LineRecordReader#getProgress now throw IOExceptions in both the old and new APIs. Their superclass method, RecordReader#getProgress, already did this, but source compatibility will be broken for the rare code that used it without a try/catch block.
- FileOutputCommitter#abortTask now throws an IOException. Its superclass method always did this, but source compatibility will be broken for the rare code that used it without a try/catch block. This was fixed in CDH 4.3 MRv1 to be compatible with MRv2.
- Job#getDependentJobs, an API marked @Evolving, now returns a List instead of an ArrayList.
Compiling Jobs Against MRv2
If you are using Maven, compiling against MRv2 requires including the same artifact, hadoop-client. Changing the version to Hadoop 2 version (for example, using 2.2.0-cdh5.0.0 instead of 2.0.0-mr1-cdh4.3.0) should be enough. If you are not using Maven, compiling against all the Hadoop JARs is recommended. A comprehensive list of Hadoop Maven artifacts is available at: Using the CDH 5 Maven Repository.
If you want your job to run against both MRv1 and MRv2, compile it against MRv2.
Job Configuration
As in MRv1, job configuration options can be specified on the command line, in Java code, or in the mapred-site.xml on the client machine in the same way they previously were. The vast majority of job configuration options that were available in MRv1 work in MRv2 as well. For consistency and clarity, many options have been given new names. The older names are deprecated, but will still work for the time being. The exceptions to this are mapred.child.ulimit and all options relating to JVM reuse, as these are no longer supported.
Submitting and Monitoring Jobs
The MapReduce command line interface remains entirely compatible. Use of the Hadoop command line tool to run MapReduce related commands (pipes, job, queue, classpath, historyserver, distcp, archive) is deprecated, but still works. The mapred command line tool is preferred for these commands.
Selecting Appropriate JAR files for Your Jobs
The following table shows the names and locations of the JAR files used in MRv1 and the corresponding names and locations in YARN:
| Name | MapReduce MRv1 location | YARN location |
|---|---|---|
| Streaming |
/usr/lib/hadoop-0.20-mapreduce/contrib/streaming/ hadoop-streaming-2.0.0-mr1-cdh<version>.jar |
/usr/lib/hadoop-mapreduce/ hadoop-streaming.jar |
| Rumen |
N/A |
/usr/lib/hadoop-mapreduce/ hadoop-rumen.jar |
| Hadoop Examples |
/usr/lib/hadoop-0.20-mapreduce/ hadoop-examples.jar |
/usr/lib/hadoop-mapreduce/ hadoop-mapreduce-examples.jar |
| DistCp v1 |
/usr/lib/hadoop-0.20-mapreduce/ hadoop-tools.jar |
/usr/lib/hadoop-mapreduce/ hadoop-extras.jar |
| DistCp v2 |
N/A |
/usr/lib/hadoop-mapreduce/ hadoop-distcp.jar |
| Hadoop archives |
/usr/lib/hadoop-0.20-mapreduce/ hadoop-tools.jar |
/usr/lib/hadoop-mapreduce/ hadoop-archives.jar |
Requesting Resources
A MapReduce job submission includes the amount of resources to reserve for each map and reduce task. As in MapReduce 1, the amount of memory requested is controlled by the mapreduce.map.memory.mb and mapreduce.reduce.memory.mb properties.
MapReduce 2 adds additional parameters that control how much processing power to reserve for each task as well. The mapreduce.map.cpu.vcores and mapreduce.reduce.cpu.vcores properties express how much parallelism a map or reduce task can take advantage of. These should remain at their default value of 1 unless your code is explicitly spawning extra compute-intensive threads.
For Administrators: Configuring and Running MRv2 Clusters
Configuration Migration
Since MapReduce 1 functionality has been split into two components, MapReduce cluster configuration options have been split into YARN configuration options, which go in yarn-site.xml, and MapReduce configuration options, which go in mapred-site.xml. Many have been given new names to reflect the shift. As JobTrackers and TaskTrackers no longer exist in MRv2, all configuration options pertaining to them no longer exist, although many have corresponding options for the ResourceManager, NodeManager, and JobHistoryServer.
- yarn-site.xml configuration
<?xml version="1.0" encoding="UTF-8"?> <configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>you.hostname.com</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration> - mapred-site.xml configuration
<?xml version="1.0" encoding="UTF-8"?> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
See Deploying MapReduce v2 (YARN) on a Cluster for instructions for a full deployment.
Resource Configuration
One of the larger changes in MRv2 is the way that resources are managed. In MRv1, each host was configured with a fixed number of map slots and a fixed number of reduce slots. Under YARN, there is no distinction between resources available for maps and resources available for reduces - all resources are available for both. Second, the notion of slots has been discarded, and resources are now configured in terms of amounts of memory (in megabytes) and CPU (in “virtual cores”, which are described below). Resource configuration is an inherently difficult topic, and the added flexibility that YARN provides in this regard also comes with added complexity. Cloudera Manager will pick sensible values automatically, but if you are setting up your cluster manually or just interested in the details, read on.
Configuring Memory Settings for YARN and MRv2
| Cloudera Manager Property Name | CDH Property Name | Default Configuration | Cloudera Tuning Guidelines |
|---|---|---|---|
| Container Memory Minimum |
yarn.scheduler. minimum-allocation-mb |
1 GB | 0 |
| Container Memory Maximum |
yarn.scheduler. maximum-allocation-mb |
64 GB | amount of memory on largest node |
| Container Memory Increment |
yarn.scheduler. increment-allocation-mb |
512 MB | Use a fairly large value, such as 128 MB |
| Container Memory |
yarn.nodemanager. resource.memory-mb |
8 GB | 8 GB |
| Map Task Memory | mapreduce.map.memory.mb | 1 GB | 1 GB |
| Reduce Task Memory | mapreduce.reduce.memory.mb | 1 GB | 1 GB |
| Map Task Java Opts Base | mapreduce.map.java.opts | -Djava.net.preferIPv4Stack=true | -Djava.net.preferIPv4Stack=true -Xmx768m |
| Reduce Task Java Opts Base | mapreduce.reduce.java.opts | -Djava.net.preferIPv4Stack=true | -Djava.net.preferIPv4Stack=true -Xmx768m |
| ApplicationMaster Memory |
yarn.app.mapreduce. am.resource.mb |
1 GB | 1 GB |
| ApplicationMaster Java Opts Base |
yarn.app.mapreduce. am.command-opts |
-Djava.net.preferIPv4Stack=true | -Djava.net.preferIPv4Stack=true -Xmx768m |
Resource Requests
From the perspective of a developer requesting resource allocations for a job’s tasks, nothing needs to be changed. Map and reduce task memory requests still work and, additionally, tasks that will use multiple threads can request more than 1 core with the mapreduce.map.cpu.vcores and mapreduce.reduce.cpu.vcores properties.
Configuring Host Capacities
In MRv1, the mapred.tasktracker.map.tasks.maximum and mapred.tasktracker.reduce.tasks.maximum properties dictated how many map and reduce slots each TaskTracker had. These properties no longer exist in YARN. Instead, YARN uses yarn.nodemanager.resource.memory-mb and yarn.nodemanager.resource.cpu-vcores, which control the amount of memory and CPU on each host, both available to both maps and reduces. If you were using Cloudera Manager to configure these automatically, Cloudera Manager will take care of it in MRv2 as well. If configuring these manually, simply set these to the amount of memory and number of cores on the machine after subtracting out resources needed for other services.
Virtual Cores
To better handle varying CPU requests, YARN supports virtual cores (vcores) , a resource meant to express parallelism. The “virtual” in the name is somewhat misleading - on the NodeManager, vcores should be configured equal to the number of physical cores on the machine. Tasks should be requested with vcores equal to the number of cores they can saturate at once. Currently vcores are very coarse - tasks will rarely want to ask for more than one of them, but a complementary axis that represents processing power may be added in the future to enable finer-grained resource configuration.
Rounding Request Sizes
Also noteworthy are the yarn.scheduler.minimum-allocation-mb, yarn.scheduler.minimum-allocation-vcores, yarn.scheduler.increment-allocation-mb, and yarn.scheduler.increment-allocation-vcores properties, which default to 1024, 1, 512, and 1 respectively. If tasks are submitted with resource requests lower than the minimum-allocation values, their requests will be set to these values. If tasks are submitted with resource requests that are not multiples of the increment-allocation values, their requests will be rounded up to the nearest increments.
To make all of this more concrete, let’s use an example. Each host in the cluster has 24 GB of memory and 6 cores. Other services running on the nodes require 4 GB and 1 core, so we set yarn.nodemanager.resource.memory-mb to 20480 and yarn.nodemanager.resource.cpu-vcores to 5. If you leave the map and reduce task defaults of 1024 MB and 1 virtual core intact, you will have at most 5 tasks running at the same time. If you want each of your tasks to use 5 GB, set their mapreduce.(map|reduce).memory.mb to 5120, which would limit you to 4 tasks running at the same time.
Scheduler Configuration
Cloudera recommends using the Fair Scheduler in MRv2. (FIFO and Capacity Scheduler are also available.) Fair Scheduler allocation files require changes in light of the new way that resources work. The minMaps, maxMaps, minReduces, and maxReduces queue properties have been replaced with a minResources property and a maxProperties. Instead of taking a number of slots, these properties take a value like “1024 MB, 3 vcores”. By default, the MRv2 Fair Scheduler will attempt to equalize memory allocations in the same way it attempted to equalize slot allocations in MRv1. The MRv2 Fair Scheduler contains a number of new features including hierarchical queues and fairness based on multiple resources.
Administration Commands
The jobtracker and tasktracker commands, which start the JobTracker and TaskTracker, are no longer supported because these services no longer exist. They are replaced with yarn resourcemanager and yarn nodemanager, which start the ResourceManager and NodeManager respectively. hadoop mradmin is no longer supported. Instead, yarn rmadmin should be used. The new admin commands mimic the functionality of the MRv1 names, allowing nodes, queues, and ACLs to be refreshed while the ResourceManager is running.
Security
The following section outlines the additional changes needed to migrate a secure cluster.
New YARN Kerberos service principals should be created for the ResourceManager and NodeManager, using the pattern used for other Hadoop services, that is, yarn@HOST. The mapred principal should still be used for the JobHistory Server. If you are using Cloudera Manager to configure security, this will be taken care of automatically.
As in MRv1, a configuration must be set to have the user that submits a job own its task processes. The equivalent of the MRv1 LinuxTaskController is the LinuxContainerExecutor. In a secure setup, NodeManager configurations should set yarn.nodemanager.container-executor.class to org.apache.hadoop.yarn.server.nodemanager.LinuxContainerExecutor. Properties set in the taskcontroller.cfg configuration file should be migrated to their analogous properties in the container-executor.cfg file.
In secure setups, configuring hadoop-policy.xml allows administrators to set up access control lists on internal protocols. The following is a table of MRv1 options and their MRv2 equivalents:
| MRv1 | MRv2 | Comment |
|---|---|---|
| security.task.umbilical.protocol.acl | security.job.task.protocol.acl | As in MRv1, this should never be set to anything other than * |
| security.inter.tracker.protocol.acl | security.resourcetracker.protocol.acl | |
| security.job.submission.protocol.acl | security.applicationclient.protocol.acl | |
| security.admin.operations.protocol.acl | security.resourcemanager-administration.protocol.acl | |
| security.applicationmaster.protocol.acl | No MRv1 equivalent | |
| security.containermanagement.protocol.acl | No MRv1 equivalent | |
| security.resourcelocalizer.protocol.acl | No MRv1 equivalent | |
| security.job.client.protocol.acl | No MRv1 equivalent |
Queue access control lists (ACLs) are now placed in the Fair Scheduler configuration file instead of the JobTracker configuration. A list of users and groups that can submit jobs to a queue can be placed in aclSubmitApps in the queue’s configuration. The queue administration ACL is no longer supported, but will be in a future release.
Ports
The following is a list of default ports used by MRv2 and YARN, as well as the configuration properties used to configure them.
| Port | Use | Property |
|---|---|---|
| 8032 | ResourceManager Client RPC | yarn.resourcemanager.address |
| 8030 | ResourceManager Scheduler RPC (for ApplicationMasters) | yarn.resourcemanager.scheduler.address |
| 8033 | ResourceManager Admin RPC | yarn.resourcemanager.admin.address |
| 8088 | ResourceManager Web UI and REST APIs | yarn.resourcemanager.webapp.address |
| 8031 | ResourceManager Resource Tracker RPC (for NodeManagers) | yarn.resourcemanager.resource-tracker.address |
| 8040 | NodeManager Localizer RPC | yarn.nodemanager.localizer.address |
| 8042 | NodeManager Web UI and REST APIs | yarn.nodemanager.webapp.address |
| 10020 | Job History RPC | mapreduce.jobhistory.address |
| 19888 | Job History Web UI and REST APIs | mapreduce.jobhistory.webapp.address |
| 13562 | Shuffle HTTP | mapreduce.shuffle.port |
High Availability
- Failover controller has been moved from a separate ZKFC daemon to be a part of the ResourceManager itself. So, there is no need to run an additional daemon.
- Clients, applications, and NodeManagers do not require configuring a proxy-provider to talk to the active ResourceManager.
| MRv1 | YARN / MRv2 | Comment |
|---|---|---|
mapred.jobtrackers.name |
yarn.resourcemanager.ha.rm-ids |
|
mapred.ha.jobtracker.id |
yarn.resourcemanager.ha.id |
Unlike in MRv1, this must be configured in YARN. |
mapred.jobtracker.rpc-address.name.id |
(See Configuring YARN (MRv2) ResourceManager High Availability Using the Command Line | YARN/ MRv2 has different RPC ports for different functionalities. Each port-related configuration must be suffixed with an id. Note that there is no name component in YARN. |
mapred.ha.jobtracker.rpc-address.name.id |
yarn.resourcemanager.ha.admin.address |
|
mapred.ha.fencing.methods |
yarn.resourcemanager.ha.fencer |
Not required to be specified |
mapred.client.failover.* |
None | Not required |
yarn.resourcemanager.ha.enabled |
Enable HA | |
mapred.jobtracker.restart.recover |
yarn.resourcemanager.recovery.enabled |
Enable recovery of jobs after failover |
yarn.resourcemanager.store.class |
org.apache.hadoop.yarn .server.resourcemanager .recovery .ZKRMStateStore |
|
mapred.ha.automatic-failover.enabled |
yarn.resourcemanager.ha.automatic-failover.enabled |
Enable automatic failover |
mapred.ha.zkfc.port |
yarn.resourcemanager.ha.automatic-failover.port |
|
mapred.job.tracker |
yarn.resourcemanager.cluster.id |
Cluster name |
Upgrading an MRv1 Installation Using Cloudera Manager
See Importing MapReduce Configurations to YARN for instructions.
Upgrading an MRv1 Installation Using the Command Line
- Uninstall the following packages: hadoop-0.20-mapreduce, hadoop-0.20-mapreduce-jobtracker, hadoop-0.20-mapreduce-tasktracker, hadoop-0.20-mapreduce-zkfc, hadoop-0.20-mapreduce-jobtrackerha.
- Install the following additional packages : hadoop-yarn, hadoop-mapreduce, hadoop-mapreduce-historyserver, hadoop-yarn-resourcemanager, hadoop-yarn-nodemanager.
- Look at all the service configurations placed in mapred-site.xml and replace them with their corresponding YARN configuration. Configurations starting with yarn should be placed inside yarn-site.xml, not mapred-site.xml. Refer to Resource Configuration for best practices on how to convert TaskTracker slot capacities (mapred.tasktracker.map.tasks.maximum and mapred.tasktracker.reduce.tasks.maximum) to NodeManager resource capacities (yarn.nodemanager.resource.memory-mb and yarn.nodemanager.resource.cpu-vcores), as well as how to convert configurations in the Fair Scheduler allocations file, fair-scheduler.xml.
- Start the ResourceManager, NodeManagers, and the JobHistoryServer.
Web UI
In MRv1, the JobTracker Web UI served detailed information about the state of the cluster and the jobs (recent and current) running on it. It also contained the job history page, which served information from disk about older jobs.
The MRv2 Web UI provides the same information structured in the same way, but has been revamped with a new look and feel. The ResourceManager’s UI, which includes information about running applications and the state of the cluster, is now located by default at <ResourceManager host>:8088. The JobHistory UI is now located by default at <JobHistoryServer host>:19888. Jobs can be searched and viewed there just as they could in MRv1.
Because the ResourceManager is meant to be agnostic to many of the concepts in MapReduce, it cannot host job information directly. Instead, it proxies to a Web UI that can. If the job is running, this proxy is the relevant MapReduce ApplicationMaster; if the job has completed, then this proxy is the JobHistoryServer. Thus, the user experience is similar to that of MRv1, but the information is now coming from different places.
Summary of Configuration Changes
The following tables summarize the changes in configuration parameters between MRv1 and MRv2.
JobTracker Properties and ResourceManager Equivalents
| MRv1 | YARN / MRv2 |
|---|---|
mapred.jobtracker.taskScheduler |
yarn.resourcemanager.scheduler.class |
mapred.jobtracker.completeuserjobs.maximum |
yarn.resourcemanager.max-completed-applications |
mapred.jobtracker.restart.recover |
yarn.resourcemanager.recovery.enabled |
mapred.job.tracker |
yarn.resourcemanager.hostnameor all of the following: yarn.resourcemanager.address yarn.resourcemanager.scheduler.address yarn.resourcemanager.resource-tracker.address yarn.resourcemanager.admin.address |
mapred.job.tracker.http.address |
yarn.resourcemanager.webapp.addressor yarn.resourcemanager.hostname |
mapred.job.tracker.handler.count |
yarn.resourcemanager.resource-tracker.client.thread-count |
mapred.hosts |
yarn.resourcemanager.nodes.include-path |
mapred.hosts.exclude |
yarn.resourcemanager.nodes.exclude-path |
mapred.cluster.max.map.memory.mb |
yarn.scheduler.maximum-allocation-mb |
mapred.cluster.max.reduce.memory.mb |
yarn.scheduler.maximum-allocation-mb |
mapred.acls.enabled |
yarn.acl.enable |
mapreduce.cluster.acls.enabled |
yarn.acl.enable |
JobTracker Properties and JobHistoryServer Equivalents
| MRv1 | YARN / MRv2 | Comment |
|---|---|---|
mapred.job.tracker.retiredjobs.cache.size |
mapreduce.jobhistory.joblist.cache.size |
|
mapred.job.tracker.jobhistory.lru.cache.size |
mapreduce.jobhistory.loadedjobs.cache.size |
|
mapred.job.tracker.history.completed.location |
mapreduce.jobhistory.done-dir |
Local FS in MR1; stored in HDFS in MR2 |
hadoop.job.history.user.location |
mapreduce.jobhistory.done-dir |
|
hadoop.job.history.location |
mapreduce.jobhistory.done-dir |
JobTracker Properties and MapReduce ApplicationMaster Equivalents
| MRv1 | YARN / MRv2 | Comment |
|---|---|---|
mapreduce.jobtracker.staging.root.dir |
yarn.app.mapreduce.am.staging-dir |
Now configurable per job |
TaskTracker Properties and NodeManager Equivalents
| MRv1 | YARN / MRv2 |
|---|---|
mapred.tasktracker.map.tasks.maximum |
yarn.nodemanager.resource.memory-mband yarn.nodemanager.resource.cpu-vcores |
mapred.tasktracker.reduce.tasks.maximum |
yarn.nodemanager.resource.memory-mband yarn.nodemanager.resource.cpu-vcores |
mapred.tasktracker.expiry.interval |
yarn.nm.liveliness-monitor.expiry-interval-ms |
mapred.tasktracker.resourcecalculatorplugin |
yarn.nodemanager.container-monitor.resource-calculator.class |
mapred.tasktracker.taskmemorymanager.monitoring-interval |
yarn.nodemanager.container-monitor.interval-ms |
mapred.tasktracker.tasks.sleeptime-before-sigkill |
yarn.nodemanager.sleep-delay-before-sigkill.ms |
mapred.task.tracker.task-controller |
yarn.nodemanager.container-executor.class |
mapred.local.dir |
yarn.nodemanager.local-dirs |
mapreduce.cluster.local.dir |
yarn.nodemanager.local-dirs |
mapred.disk.healthChecker.interval |
yarn.nodemanager.disk-health-checker.interval-ms |
mapred.healthChecker.script.path |
yarn.nodemanager.health-checker.script.path |
mapred.healthChecker.interval |
yarn.nodemanager.health-checker.interval-ms |
mapred.healthChecker.script.timeout |
yarn.nodemanager.health-checker.script.timeout-ms |
mapred.healthChecker.script.args |
yarn.nodemanager.health-checker.script.opts |
local.cache.size |
yarn.nodemanager.localizer.cache.target-size-mb |
mapreduce.tasktracker.cache.local.size |
yarn.nodemanager.localizer.cache.target-size-mb |
TaskTracker Properties and Shuffle Service Equivalents
The table that follows shows TaskTracker properties and their equivalents in the auxiliary shuffle service that runs inside NodeManagers.
| MRv1 | YARN / MRv2 |
|---|---|
tasktracker.http.threads |
mapreduce.shuffle.max.threads |
mapred.task.tracker.http.address |
mapreduce.shuffle.port |
mapred.tasktracker.indexcache.mb |
mapred.tasktracker.indexcache.mb |
Per-Job Configuration Properties
Many of these properties have new names in MRv2, but the MRv1 names will work for all properties except mapred.job.restart.recover.
| MRv1 | YARN / MRv2 | Comment |
|---|---|---|
io.sort.mb |
mapreduce.task.io.sort.mb |
MRv1 name still works |
io.sort.factor |
mapreduce.task.io.sort.factor |
MRv1 name still works |
io.sort.spill.percent |
mapreduce.task.io.sort.spill.percent |
MRv1 name still works |
mapred.map.tasks |
mapreduce.job.maps |
MRv1 name still works |
mapred.reduce.tasks |
mapreduce.job.reduces |
MRv1 name still works |
mapred.job.map.memory.mb |
mapreduce.map.memory.mb |
MRv1 name still works |
mapred.job.reduce.memory.mb |
mapreduce.reduce.memory.mb |
MRv1 name still works |
mapred.map.child.log.level |
mapreduce.map.log.level |
MRv1 name still works |
mapred.reduce.child.log.level |
mapreduce.reduce.log.level |
MRv1 name still works |
mapred.inmem.merge.threshold |
mapreduce.reduce.shuffle.merge.inmem.threshold |
MRv1 name still works |
mapred.job.shuffle.merge.percent |
mapreduce.reduce.shuffle.merge.percent |
MRv1 name still works |
mapred.job.shuffle.input.buffer.percent |
mapreduce.reduce.shuffle.input.buffer.percent |
MRv1 name still works |
mapred.job.reduce.input.buffer.percent |
mapreduce.reduce.input.buffer.percent |
MRv1 name still works |
mapred.map.tasks.speculative.execution |
mapreduce.map.speculative |
Old one still works |
mapred.reduce.tasks.speculative.execution |
mapreduce.reduce.speculative |
MRv1 name still works |
mapred.min.split.size |
mapreduce.input.fileinputformat.split.minsize |
MRv1 name still works |
keep.failed.task.files |
mapreduce.task.files.preserve.failedtasks |
MRv1 name still works |
mapred.output.compress |
mapreduce.output.fileoutputformat.compress |
MRv1 name still works |
mapred.map.output.compression.codec |
mapreduce.map.output.compress.codec |
MRv1 name still works |
mapred.compress.map.output |
mapreduce.map.output.compress |
MRv1 name still works |
mapred.output.compression.type |
mapreduce.output.fileoutputformat.compress.type |
MRv1 name still works |
mapred.userlog.limit.kb |
mapreduce.task.userlog.limit.kb |
MRv1 name still works |
jobclient.output.filter |
mapreduce.client.output.filter |
MRv1 name still works |
jobclient.completion.poll.interval |
mapreduce.client.completion.pollinterval |
MRv1 name still works |
jobclient.progress.monitor.poll.interval |
mapreduce.client.progressmonitor.pollinterval |
MRv1 name still works |
mapred.task.profile |
mapreduce.task.profile |
MRv1 name still works |
mapred.task.profile.maps |
mapreduce.task.profile.maps |
MRv1 name still works |
mapred.task.profile.reduces |
mapreduce.task.profile.reduces |
MRv1 name still works |
mapred.line.input.format.linespermap |
mapreduce.input.lineinputformat.linespermap |
MRv1 name still works |
mapred.skip.attempts.to.start.skipping |
mapreduce.task.skip.start.attempts |
MRv1 name still works |
mapred.skip.map.auto.incr.proc.count |
mapreduce.map.skip.proc.count.autoincr |
MRv1 name still works |
mapred.skip.reduce.auto.incr.proc.count |
mapreduce.reduce.skip.proc.count.autoincr |
MRv1 name still works |
mapred.skip.out.dir |
mapreduce.job.skip.outdir |
MRv1 name still works |
mapred.skip.map.max.skip.records |
mapreduce.map.skip.maxrecords |
MRv1 name still works |
mapred.skip.reduce.max.skip.groups |
mapreduce.reduce.skip.maxgroups |
MRv1 name still works |
job.end.retry.attempts |
mapreduce.job.end-notification.retry.attempts |
MRv1 name still works |
job.end.retry.interval |
mapreduce.job.end-notification.retry.interval |
MRv1 name still works |
job.end.notification.url |
mapreduce.job.end-notification.url |
MRv1 name still works |
mapred.merge.recordsBeforeProgress |
mapreduce.task.merge.progress.records |
MRv1 name still works |
mapred.job.queue.name |
mapreduce.job.queuename |
MRv1 name still works |
mapred.reduce.slowstart.completed.maps |
mapreduce.job.reduce.slowstart.completedmaps |
MRv1 name still works |
mapred.map.max.attempts |
mapreduce.map.maxattempts |
MRv1 name still works |
mapred.reduce.max.attempts |
mapreduce.reduce.maxattempts |
MRv1 name still works |
mapred.reduce.parallel.copies |
mapreduce.reduce.shuffle.parallelcopies |
MRv1 name still works |
mapred.task.timeout |
mapreduce.task.timeout |
MRv1 name still works |
mapred.max.tracker.failures |
mapreduce.job.maxtaskfailures.per.tracker |
MRv1 name still works |
mapred.job.restart.recover |
mapreduce.am.max-attempts |
|
mapred.combine.recordsBeforeProgress |
mapreduce.task.combine.progress.records |
MRv1 name should still work - see MAPREDUCE-5130 |
Miscellaneous Properties
| MRv1 | YARN / MRv2 |
|---|---|
mapred.heartbeats.in.second |
yarn.resourcemanager.nodemanagers.heartbeat-interval-ms |
mapred.userlog.retain.hours |
yarn.log-aggregation.retain-seconds |
MRv1 Properties that have no MRv2 Equivalents
| MRv1 | Comment |
|---|---|
mapreduce.tasktracker.group |
|
mapred.child.ulimit |
|
mapred.tasktracker.dns.interface |
|
mapred.tasktracker.dns.nameserver |
|
mapred.tasktracker.instrumentation |
NodeManager does not accept instrumentation |
mapred.job.reuse.jvm.num.tasks |
JVM reuse no longer supported |
mapreduce.job.jvm.numtasks |
JVM reuse no longer supported |
mapred.task.tracker.report.address |
No need for this, as containers do not use IPC with NodeManagers, and ApplicationMaster ports are chosen at runtime |
mapreduce.task.tmp.dir |
No longer configurable. Now always tmp/ (under container's local dir) |
mapred.child.tmp |
No longer configurable. Now always tmp/ (under container's local dir) |
mapred.temp.dir |
|
mapred.jobtracker.instrumentation |
ResourceManager does not accept instrumentation |
mapred.jobtracker.plugins |
ResourceManager does not accept plugins |
mapred.task.cache.level |
|
mapred.queue.names |
These go in the scheduler-specific configuration files |
mapred.system.dir |
|
mapreduce.tasktracker.cache.local.numberdirectories |
|
mapreduce.reduce.input.limit |
|
io.sort.record.percent |
Tuned automatically (MAPREDUCE-64) |
mapred.cluster.map.memory.mb |
Not necessary; MRv2 uses resources instead of slots |
mapred.cluster.reduce.memory.mb |
Not necessary; MRv2 uses resources instead of slots |
mapred.max.tracker.blacklists |
|
mapred.jobtracker.maxtasks.per.job |
Related configurations go in scheduler-specific configuration files |
mapred.jobtracker.taskScheduler.maxRunningTasksPerJob |
Related configurations go in scheduler-specific configuration files |
io.map.index.skip |
|
mapred.user.jobconf.limit |
|
mapred.local.dir.minspacestart |
|
mapred.local.dir.minspacekill |
|
hadoop.rpc.socket.factory.class.JobSubmissionProtocol |
|
mapreduce.tasktracker.outofband.heartbeat |
Always on |
mapred.jobtracker.job.history.block.size |