Generating Lineage Diagrams
Navigator Metadata Server uses the metadata it collects to generate lineage graphs. These graphs tell you what data and processes were used to generate a given data asset.
This documentation describes
- Where the lineage information comes from
- How the lineage varies based on the source of the metadata
- Life cycle of lineage info as assets change on the cluster
Lineage Generation Architecture
Navigator Metadata Server collects metadata from CDH services, creates records in Solr for each of the data assets and operations, then uses the operation metadata to build relations among the data assets. You see the relations among data assets in the Navigator Console as a lineage graph. Here's the process in a little more detail:
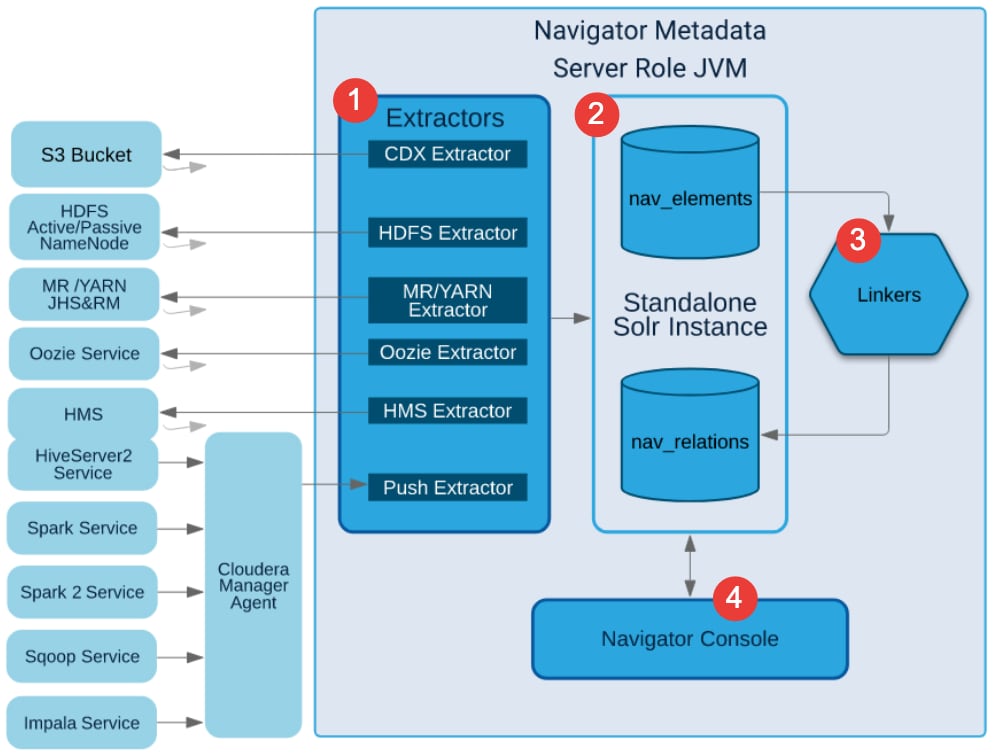
- Extractors collect metadata from services in the cluster.
The extractors are components within Navigator that communicate with each service that Navigator supports. For example, for Navigator Metadata Server to collect HDFS metadata, the Navigator HDFS extractor talks to the namenode to request file system information.
There are two types of extractors:
- Pull extractors (CDX, HDFS, YARN, Oozie, HMS). The extractor requests metadata from the service about every 10 minutes, assuming there is not already an extraction in progress. The CDX extractor pulls metadata from S3.
- Push extractors (Spark, Impala, Hive Server 2, Sqoop). The service saves metadata to the local file system for every operation; the Cloudera Manager agent running on the same host passes the metadata to Navigator Metadata Server about every five seconds.
For more information about how the timing of push and pull extractors affects when lineage appears in the Navigator console, see Metadata Extraction Timing.
- Navigator indexes each data asset and operation.
For each new data asset and operation it finds in the extracted metadata, Navigator Metadata Server creates an entry in its Solr index. These entries appear in nav_elements core. The most recently extracted metadata is always used to update any existing entity entry. In addition, Navigator Metadata Server creates a nav_relation entry in the Solr index to store relationship information, such as between a directory and a file or subdirectory or between a table and the directory backing it. Navigator saves a variety of relationship information:
- Parent - child: Directory and subdirectory, directory and file, parent Oozie job and child Hive Server 2 query.
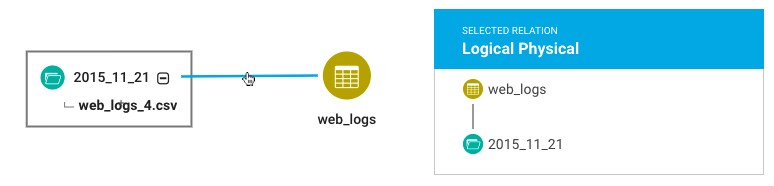
- Logical - physical: Hive table and the HDFS directory that contains the data.
- Instance of: Operation and operation execution.
- Data flow: Query operation that refers to input or output tables.
- Control flow: Column level details in an operation that refers to specific column or field details in a table, view, or file.
If Navigator doesn't have all the information it needs to fill in both ends of a relationship, it creates an "unlinked" relation. For example, when an HMS table is extracted, but the corresponding HDFS directory is not already in the index, Navigator will create an unlinked relation for the table that will be filled in later with the directory metadata.
- Linker fills in missing relation endpoints.
After it receives metadata from an extraction, Navigator Metadata Server runs a process ("linker") that uses the new metadata to fill in unlinked relations.
- Navigator console displays the relations as a lineage diagram.
The Navigator console reads nav_relation to show entity relationships in a directed graph, where the graph flows from input to output, left to right. You can choose how much detail you want to see in the graph, including showing the operations that give details on how data was transformed.
The entities shown in a lineage picture are determined by the service where the metadata came from. The lineage for data assets includes other data assets and the operations that relate them; lineage for query and compute operations include existing data assets used as inputs or outputs.
For more about how to use the lineage view to show more information, see Exploring Lineage Diagrams.
Lineage Life-cycle
The contents of a lineage diagram are determined by what metadata is extracted from services. If an object doesn't exist when the extraction occurs, it will not be reflected in the lineage diagram.
Metadata extraction timing
For pull extractors, Navigator triggers metadata extraction for each type of extractor every 10 minutes. Push extractors work differently: instead of waiting for Navigator to ask for the metadata, the services write out metadata when an event occurs; the Cloudera Manager agent on the host polls every 5 seconds and forwards whatever metadata it finds to Navigator Metadata Server. The extractor operations run until the extractor processes all the metadata provided by the service; an extraction could be running for minutes or hours depending on the volume of metadata being extracted.
Navigator runs the linking process after each extractor completes processing an extraction. The linking process can also take minutes or hours, depending on the volume of data being processed.
Deleted data assets
Each metadata extraction from a service is a snapshot of the objects managed by that service at a given time. If one extraction includes a reference to a specific table and the following extraction does not, Navigator Metadata Server flags the entity for that table as deleted. These relations are hidden in lineage diagrams. You can show them again by enabling the Deleted Entities in the lineage view options. The deleted entities are indicated with a line through their name.

Metadata Purge and Lineage
- "Instance of" relations between operation and operation executions are removed when the operation execution was executed earlier than the threshold date for purge.
- Data flow relations for operations are removed when:
- The operation doesn't have an output entity; that is, the operation does not produce a table or view or other entities produced by Sqoop jobs or associated with Pig tables.
- The associated operation executions are older than the purge threshold date.
- Parent child relations between HDFS files and their parent directory are only removed when the directory has been flagged as deleted longer than the purge threshold date.
- Hive tables and the operations that produce them are never removed, even if the tables were deleted before the purge threshold date.
- Logical-physical relations between Hive tables and HDFS directories are not removed, even if the tables were deleted before the purge threshold date.
Temporary data assets
Sometimes operations include data assets that are created and then deleted as part of the operation (or as part of a series of operations that occur close together in time). These temporary objects may or may not be captured as part of a Navigator pull extraction. The operation that produced the object is likely be extracted through a push extractor. When temporary objects are not captured, Navigator Metadata Server produces an unlinked relation based on the operation metadata. The technical metadata for the operation, such as query text, includes a reference to the temporary object; the object itself will not be listed in the Navigator console and will not appear in lineage diagrams.
For example, consider a Hive pipeline that writes data to a table, transforms the data and writes it to a second table, then removes the first table. The lineage content is different depending on whether or not metadata extraction captured the temporary table before it was dropped.
If the Navigator-HMS extractor runs when the first table was present, Navigator will create a metadata entity for the first table. When Navigator links the details of the operation with known entities, it will translate the operation details into a lineage diagram including the first and second tables. After the table is deleted and when the next extraction runs, Navigator Metadata Server flags the entity for the first table as deleted. The lineage diagram for the second table shows the first table as deleted (you may have to enable Deleted Entities in the lineage view options). The operation and operation executions still show in the lineage diagram.
If the first table is created and deleted between Navigator-HMS extractions, no metadata entity is created for the table, and the operation details don't link up to an existing entity as an operation input (unlinked relation). If you look at the lineage diagram for the second table and turn on the option to show operations, you'll see the operation that created the second table, but you won't see the first table. In the lineage view, you can see the query run by the operation. That query text shows the first table in the FROM clause.
Example of lineage across temporary tables
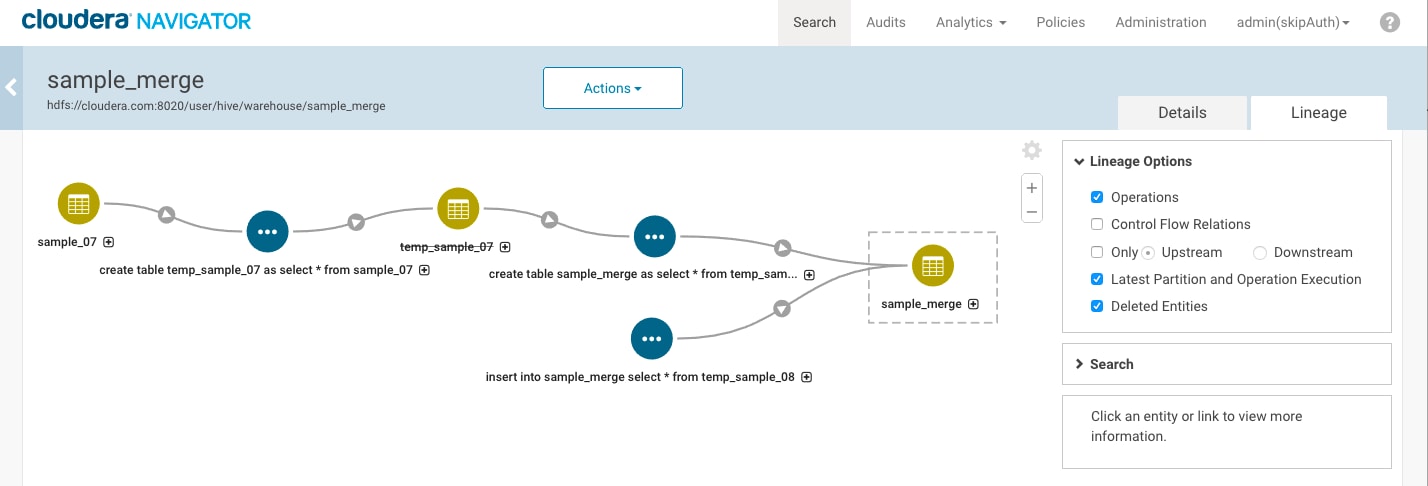
This example shows how the lineage diagram changes depending on whether a temporary table was included in a metadata extraction. The following Impala queries were run in Hue to create temporary tables (temp_sample_07 and temp_sample_08, then use those tables to load data into a third table (sample_merge):

Assume that the temp_sample_08 table was created and dropped between two metadata extractions and that the temp_sample_07 DROP TABLE command is run only after metadata extraction occurred.
After extractions are run and linking occurs, the lineage picture for the sample_merge table shows an "upstream" relationship with sample_07.
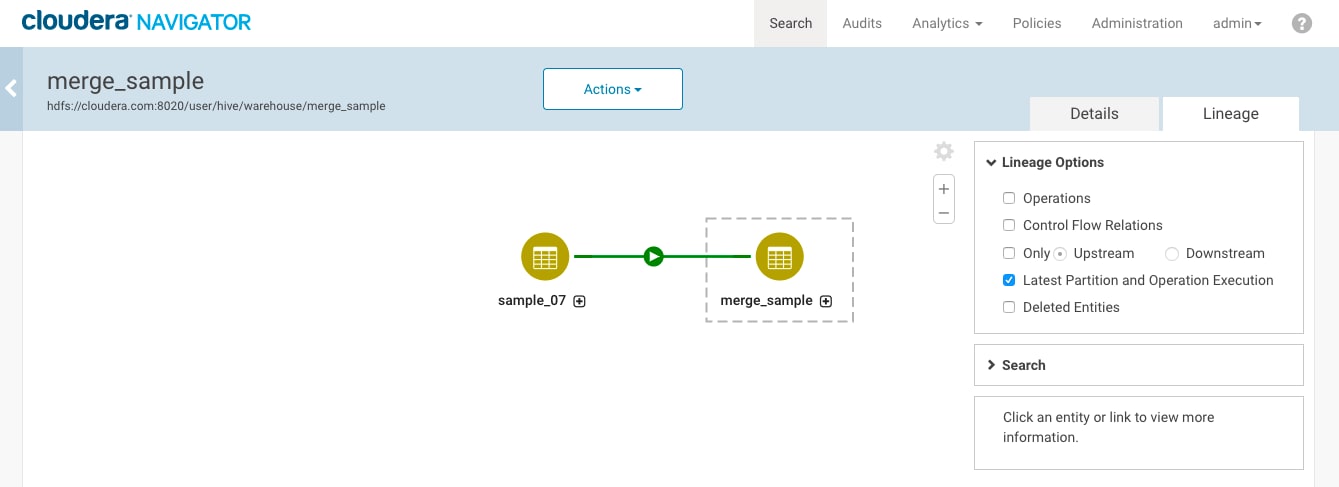
After turning on the option for Deleted Entities, the temporary table temp_sample_07 appears. It exists in the system because it was captured by the first metadata extraction and then it was deleted by the second extraction.
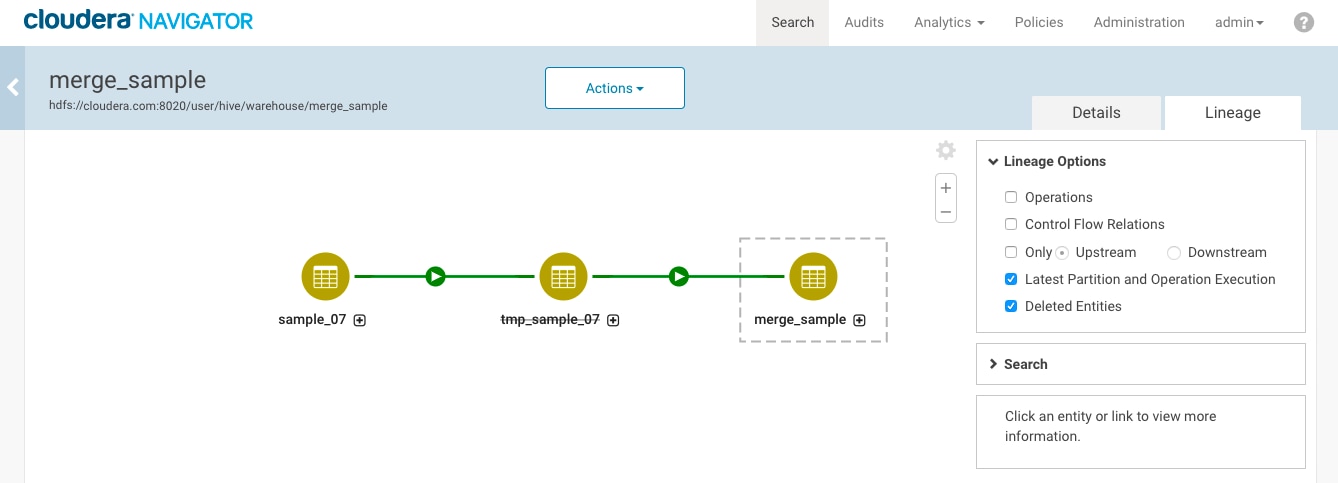
Turning on the option for Operations shows the queries that created and inserted rows into the sample_merge table. Note in particular that the operation shows for inserting data into the sample_merge table from the temporary table temp_sample_08 even though the table was not captured by a metadata extraction.
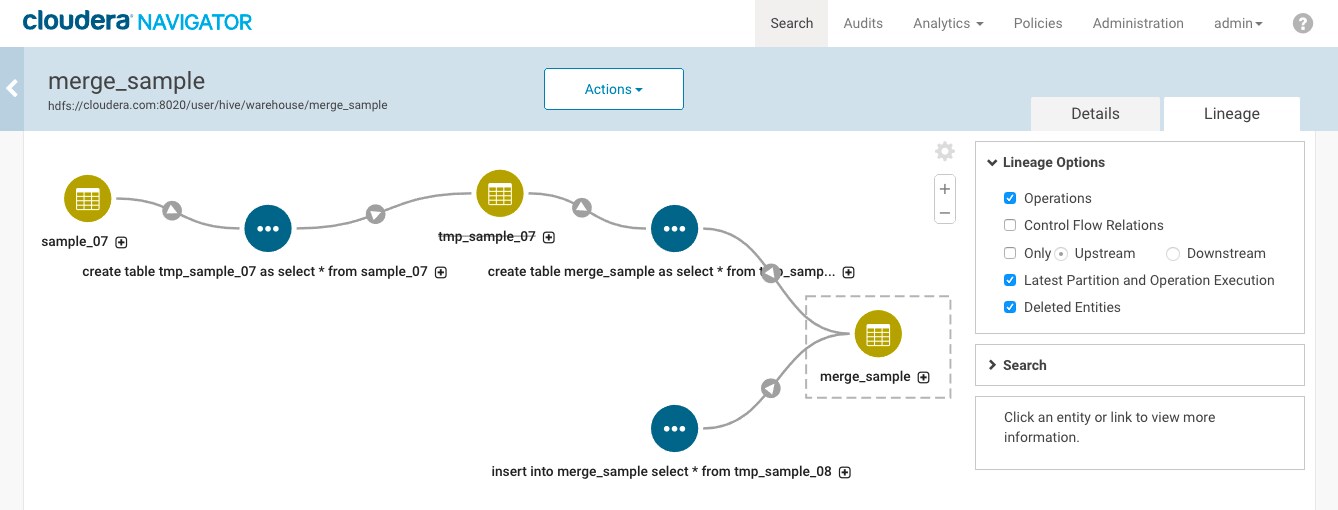
If you select the insert operation, you can see the query details to identify the operation input.
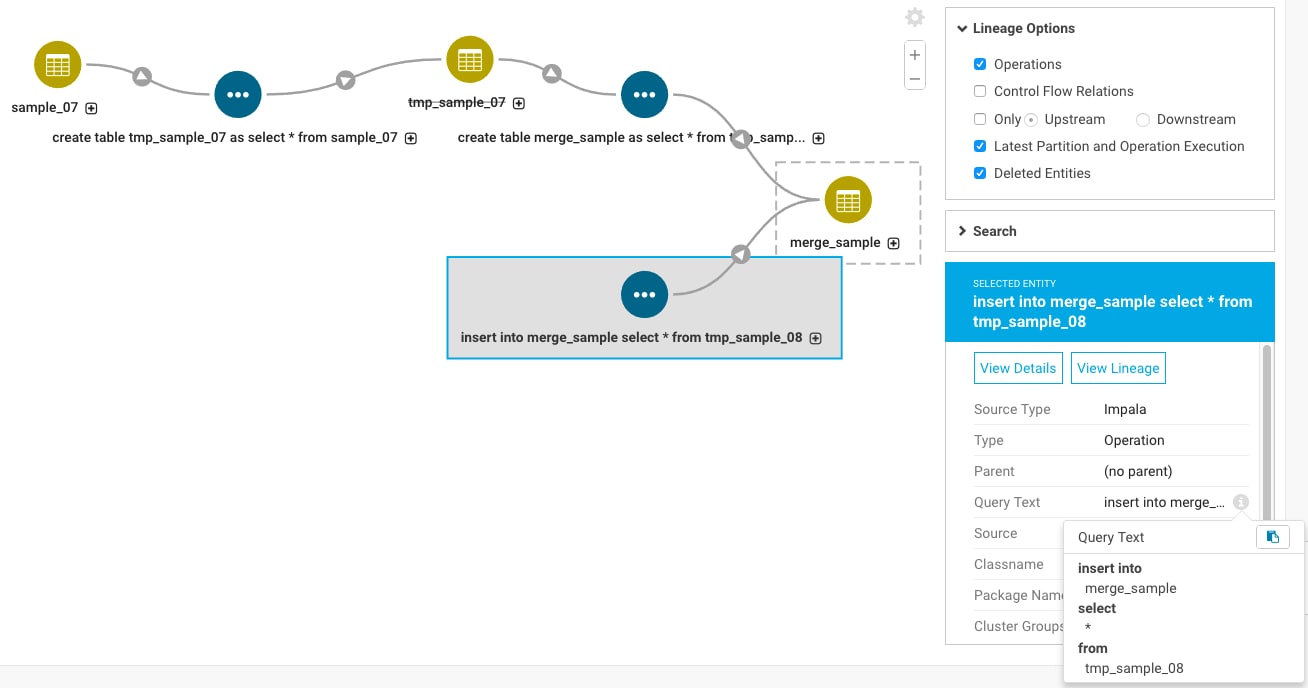
If you wanted to further trace the origin of the temporary table, you can use the table name to search for operations that affected the temporary table by searching on the query text:
queryText:*temp_sample_08*
Lineage Behavior by Service
Lineage graphs follow some rules based on the kinds of metadata provided by services. This section describes how the metadata is formed into relations; the conventions for how the relations are displayed on the lineage diagram as listed in Lineage Diagram Icons. For a list of the specific operations that produce entities in Navigator, see Service Metadata Entity Types.
Hive, Impala
Lineage is generated for (most) operations against the Hive Metastore that create data assets or modify data, including operations from HiveServer2, Impala, and Impala queries on Kudu tables. Lineage is not produced for operations performed using the Hive Server 1 CLI. For a list of the specific operations captured by Navigator extractors, see Hive Operations and Cloudera Navigator Support Matrix.
For each query operation, a relation is created for each data asset referenced as an input or output (or both) in the query. The lineage diagrams include tables, views, and operations. The metadata indicates whether the data asset is an input or output.
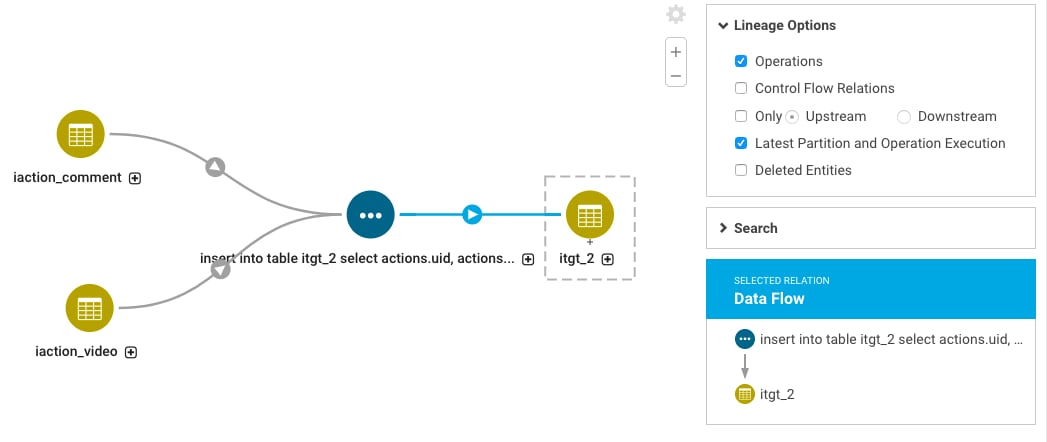
The query information provided by Hive Metastore (HMS) includes query information that allows Navigator to show data assets referenced in joins or lookups. You can see these tables when you turn on Control Flow Relations.
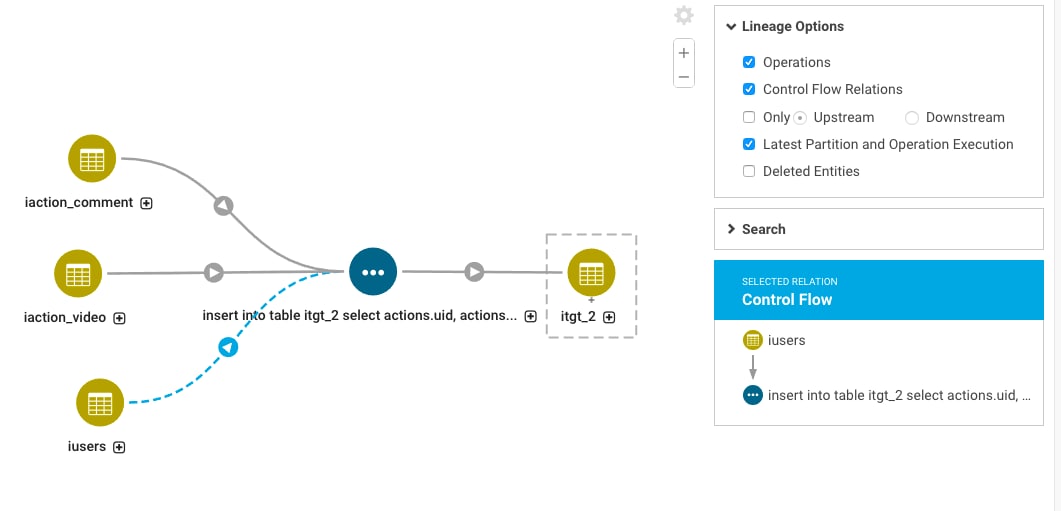
When Navigator has column level information, the lineage diagram shows a + next to the name of the object. Opening the column level information shows you how columns in source tables contribute to columns in the destination tables. Columns referenced in joins or lookups are indicated with dashed lineage relations and appear when the view includes control flow information. (Move the cursor over a column to highlight only that column's lineage through all the objects.) Because the information is generated by HMS, column-level tracing is available regardless of the underlying compute engine.

Only database-layer objects appear in the lineage for query services: Navigator doesn't show the logical-to-physical relationships such as the backing HDFS directory for each Hive table. If you want to know the location of the underlying HDFS files for a table, you can see this information in the Path property of the technical metadata for the table. Note that lineage shown for an HDFS file or directory, you will see the logical-to-physical relationship to Hive tables or views.
Only operations that include output appear in lineage for tables and views. To see a lineage diagram for operations such as SELECT that do not produce a data asset, view lineage for the operation. To see all such activity run against a specific table, you may find it useful to go the Audits tab in the Navigator console and filter on the table name.
Lineage for query services does not expose the compute engine used to perform the query; Hive operations appear the same whether they are run on MapReduce or Spark. This information is available in the technical metadata for the operation execution. Note that queries run directly in Spark are different because Spark provides different metadata than HMS.
HDFS, S3
Navigator collects metadata for file system entities. It does not collect metadata for file-system level operations, such as moves or copies. Lineage metadata appears when applications perform operations against file-system entities. For example, when a Spark job copies an HDFS directory, the lineage diagrams show the relationship between the source directory and the copied directory as connected by the Spark operation.
MapReduce, Spark, Sqoop
Navigator shows lineage diagrams for operations performed by compute engines such as MapReduce v1, YARN (MRV2), or Spark (all Spark 1 versions and Spark 2 starting with version 2.3). Lineage reflects data processed using Spark SQL, including the Datasets/Dataframe APIs. Other services such as Apache Sqoop contribute metadata that Navigator can use to create lineage diagrams as well.
For compute operations, a relation is created for each data asset referenced as an input or output (or both) in the operation. As in this image, the input and output relations are shown with arrows.
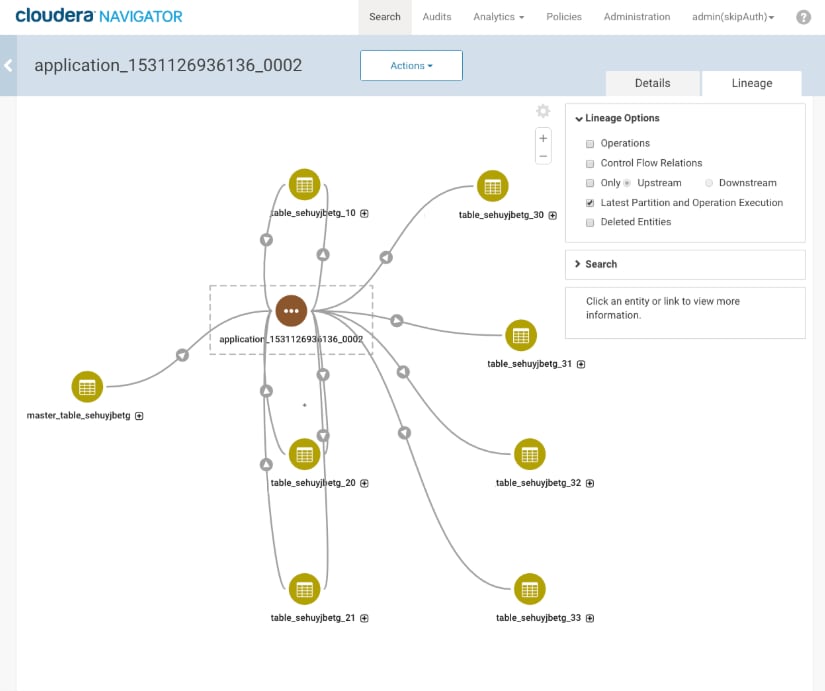
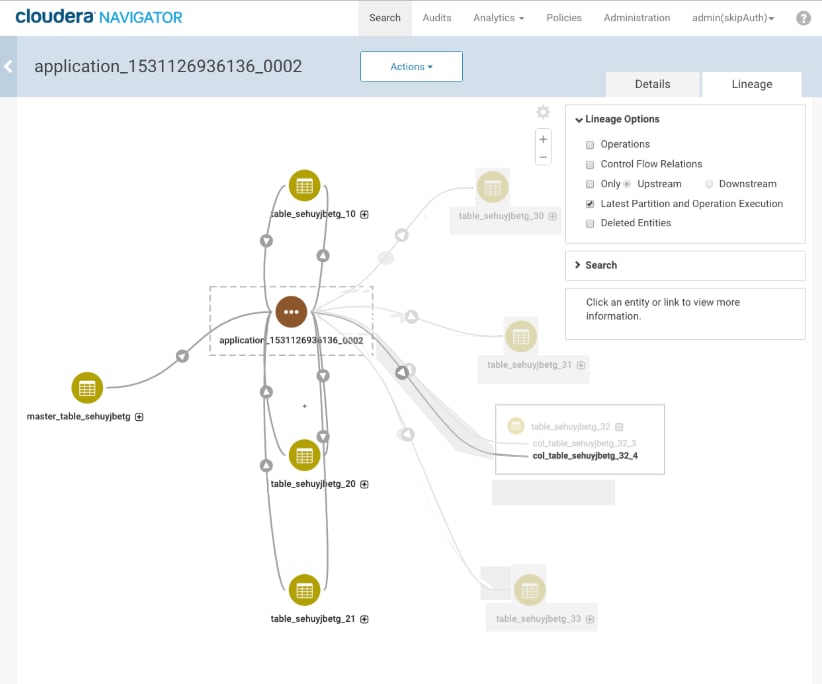
Data assets that are used for both output from and input to stages of the operation appear with two lineage lines, one with an arrow pointing into the entity; another pointing out. In the Navigator lineage diagram, entities that are both input and output to the same operation may be shown parallel to the operation rather than on the left or right.
The Navigator extractors for MapReduce and Spark services trace data lineage at the application level only. The result is that when you show the lineage diagram for a single column in a table that is affected by a Spark operation, the diagram shows other data assets that contribute to the column, but how the specific columns inside those assets contribute to the selected column is not shown.
Navigator shows all the lineage information available for Spark operations, but does not include SQL statements executed in Spark. This limitation is because Spark does not keep the SQL statement: the Spark parser creates the plan from the SQL statement and, from that point on, the SQL statement provided by the client is not retained as part of the metadata associated with the Spark job. For many Spark operations, SQL isn't part of the original request. For example: spark.read.parquet("/input").write.parquet("/output") generates lineage, but there is no SQL statement used at all.
Lineage diagrams differ slightly between Spark 1 and Spark 2 operations. In Spark 1, table creation commands are not captured as a lineage relation: when a table is created and then used by another command, the table appears only as an input to the operation. In Spark 2, table creation commands are captured: the table shows as an output (creation) and an input to the operation.
YARN, Oozie
Lineage for resource management operations, such as YARN and Oozie, include lineage relations to other operations; the metadata for YARN and Oozie entities does not reveal specific data assets touched by the processing.
Navigator shows lineage diagrams for operations performed by resource management tools such as Oozie and YARN. Relations are created for each operation controlled by job managers. These lineage diagrams show processing stages, but do not show the individual data assets affected by the operations.
When a YARN job runs a Hive query, the Navigator lineage diagram exposes the logical-to-physical relationships between Hive tables and the backing HDFS directories. The resource management through YARN appears in parallel to the data flow for Hive.
As described for compute services, jobs that run MapReduce or Spark operations report different metadata to Navigator, so the lineage diagrams look different from query processing.
Troubleshooting Lineage
When you don't see the lineage relations you expect, look for the following possible issues:
- Give time for extractors to run
- Pull extractors run every ten minutes assuming the previous run completed. For large data sets, the extractor process may require more time to run. In addition, if there are connectivity issues or if the corresponding service is busy or not available, the extraction time can lengthen. For HMS in particular, the actual time required to extract all the metadata required to draw new lineage relations can be as much as an hour if the multiple extractors involved run offset from each other.
- View lineage from the appropriate entity
- If you want to see a logical-physical relation between an HDFS directory and a Hive table, you need to access lineage from the HDFS directory.
If you want to see all the times a query is run against a Hive table you may not see it in the Hive table lineage; if the operation doesn't produce output, access the lineage from the operation, not the Hive table.
- Are extractors running successfully?
- Navigator won't show lineage information if it's not receiving it. Check to make sure that the extractor is running properly:
- Check the Navigator Metadata Server log for errors that would indicate that an extractor isn't running.
You can access Navigator Metadata Server logs from Cloudera Manager or from the command line on the host where the service is running. See Accessing Navigator Data Management Logs.
Extractor status messages include the word "extractor", such as com.cloudera.nav.hive.extractor.HiveOperationExtractor. - Check Cloudera Manager agent log to find out more detail about an error.
If you find an error in the Navigator Metadata Server log that indicates a problem with one of the push extractors, go to the Cloudera Manager agent log for the host indicated by the log error.
- Check the Navigator Metadata Server log for errors that would indicate that an extractor isn't running.