Cloudera Navigator and S3
As cloud storage becomes increasingly prevalent, many clusters use Amazon Simple Storage Service (S3) for long-running, persistent storage.
Starting with Cloudera Navigator release 2.9.0, you can use Navigator to view technical metadata, assign business metadata, and view lineage for S3 objects on your cluster. This topic provides an overview of S3 metadata entities in Navigator, describes how to configure Navigator to use S3 data, and describes unique aspects and limitations of working with S3 data in Navigator.
S3 Metadata Entities in Navigator
Amazon S3 has a flat structure, without the hierarchy found in typical filesystems. S3 entities include buckets and objects. The bucket is the container for the object.
- S3 Bucket
- Directory - Although S3 entities are limited to buckets and objects in those buckets, S3 supports the concept of a folder that can be used to organize objects. Folders in S3 are extracted as directories in Navigator.
- File
Implicit Folders
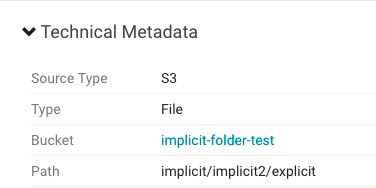
The directory/file combination is labeled as a Path.
You work with S3 entities in Navigator much as you would with entities for HDFS. For information on S3 entity properties, see S3 Properties.
For more information about Amazon S3, see the Amazon S3 documentation.
Enabling Cloudera Navigator Access to Amazon S3
To configure Navigator for S3, you must configure AWS credentials for Cloudera Manager and enable Cloudera Navigator to access data written to S3 buckets.
You configure AWS Credentials to specify the Access Key Authentication type.
Minimum Required Role: User Administrator (also provided by Full Administrator)
- Open the Cloudera Manager Admin Console.
- Click
- Click Add and select Access Key Authentication. This authentication mechanism
requires you to obtain AWS credentials from Amazon.
- Enter a Name for this account. The name can contain alphanumeric characters, hyphens, underscores, and spaces.
- Enter the AWS Access Key ID.
- Enter the AWS Secret Key.
- Click Add. The Connect to Amazon Web Services screen displays.
- Click the Enable for Cloudera Navigator link.
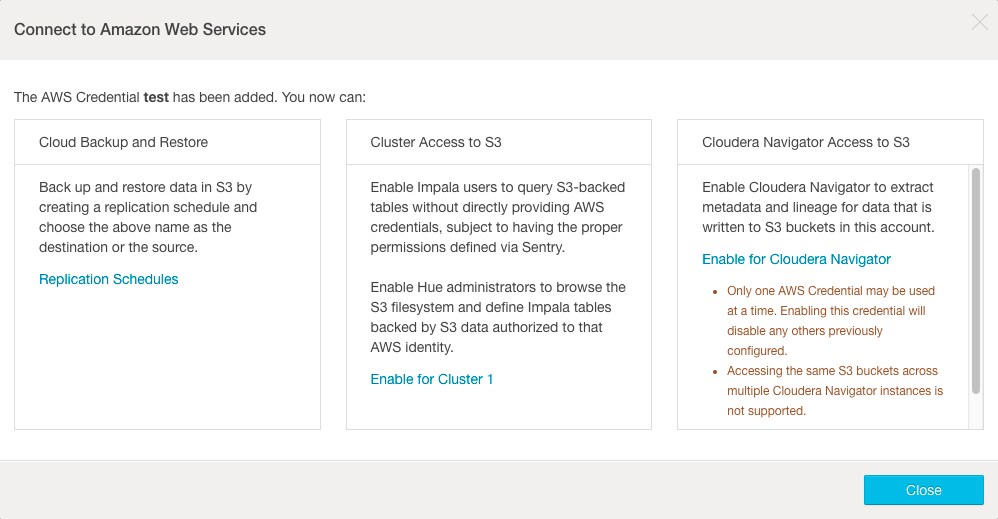
- Restart the Cloudera Navigator Metadata server to enable access.
Extracted S3 information should now be available in Cloudera Navigator.
Eventual Consistency
Amazon S3 uses an eventual consistency model. To provide high availability, consistency is informally guaranteed: Eventually, an item returns the last updated value to all accesses of that item, assuming no new updates for a period of time.
Because S3 uses eventual consistency, it might take some time for the S3 object to appear in Navigator. In addition, you might notice discrepancies between the object in Navigator and the object in S3. In Navigator, if you do not immediately see an S3 object that you created or do not see modifications that you made, that does not mean the object does not exist or was not successfully edited. In most cases, the lag time associated with eventual consistency is causing the object to not appear in Navigator or to not match the most recent version in S3.
S3 Event Notification
In Amazon S3, you enable a bucket to send notification messages whenever certain events occur. Cloudera Navigator uses Amazon Simple Queue Service (Amazon SQS) to extract S3 information.
Amazon SQS is a distributed, highly scalable hosted queue for storing messages. Navigator pulls data from the SQS queue. For more information about Amazon SQS, see Getting Started with Amazon SQS.
By default, Navigator sets up these queues and configures S3 event notification for each bucket for you. Navigator does not overwrite existing S3 event notifications. However, if any buckets have existing S3 event notifications, you must use "bring your own queue" and use an Amazon SNS "fanout". In a "fanout" scenario, an Amazon SNS message is sent to a topic and then replicated and pushed to multiple Amazon SQS queues, HTTP endpoints, or email addresses.
For more information about configuring Navigator data extraction, including "bring your own queue", see S3 Data Extraction for Navigator.
Setting API Limits
You can set an API limit for Amazon S3 API and SQS API. You are billed on a monthly basis, depending on your usage; the billing cycle resets each month. By setting these API limits, you can manage the monthly cost of using the APIs.
nav.aws.api.limit=any_int
Once your API limit is reached, Navigator suspends extraction until the next 30-day interval begins. Then at that point, Navigator extracts any data that was not extracted during the time activity was suspended.
Cloudera Navigator does not indicate if your use of the API exceeds the monthly limit; monitor your monthly use of the APIs to manage your costs.
Limitations of Navigator for S3
- Only one instance of Navigator can be configured per S3 account, and Navigator can use only one AWS credential.
- IAM role-based authentication is not supported.
- Extraction limitations:
- Navigator extracts only user-defined metadata in S3. System-defined metadata types are not extracted.
- Navigator does not extract tags for S3 buckets and objects.
- Navigator extracts only the latest versions in S3; it does not extract historical versions.
- AWS supports unnamed directories, but Navigator does not extract them.
- Auditing is not available for S3.
- Lineage is supported for Hive, Impala, and MapReduce on S3. Other types are not supported.
- MapReduce glob paths are not supported.
- S3 object removal with Object Lifecycle Management is not
supported.
For example, if you set a lifecycle rule to automatically remove any objects older than 10 days, that delete event is not be tracked by SQS and therefore not tracked by Navigator.
To use lifecycle rules with Navigator extraction, you must use only bulk extraction and not incremental extraction.