Schema
A table schema contains information about the names and types of the columns of a table.
HDFS schema contains information about the names and types of the fields in an HDFS Avro or Parquet file.
Displaying Hive, Sqoop, and Impala Table Schema
- Perform a metadata search for an entities of source type Hive and type Table.
- In the list of results, click a result entry.
- Click the Schema tab. The table schema displays.
Displaying Pig Table Schema
- Perform a metadata search for entities of source type Pig. Do one of the following:
- In the list of results, click a result entry of type Table.
-
- In the list of results, click a result entry of type Operation_Execution.
- Click the Tables tab. A list of links to tables involved in the operation displays.
- Click a table link.
- Click the Schema tab. The table schema displays.
Displaying HDFS Dataset Schema
If you ingest a Kite dataset into HDFS you can view the schema of the dataset. The schema is represented as an entity of type Dataset and is implemented as an HDFS directory.
For Avro datasets, primitive types such as null, string, int, and so on, are not separate entities. For example, if you have a record type with a field A that's a record type and a field B that's a string, the subfields of A become entities themselves, but B has no children. Another example would be if you had a union of null, string, map, array, and record types; the union has 3 children - the map, array, and record subtypes.
To display an HDFS dataset schema:
- Perform a metadata search for entities of type Dataset.
- Click a result entry.
- Click the Schema tab. The dataset schema displays.
Stocks Schema
- Use the Stocks Avro schema file:
{ "type" : "record", "name" : "Stocks", "namespace" : "com.example.stocks", "doc" : "Schema generated by Kite", "fields" : [ { "name" : "Symbol", "type" : [ "null", "string" ], "doc" : "Type inferred from 'AAIT'" }, { "name" : "Date", "type" : [ "null", "string" ], "doc" : "Type inferred from '28-Oct-2014'" }, { "name" : "Open", "type" : [ "null", "double" ], "doc" : "Type inferred from '33.1'" }, { "name" : "High", "type" : [ "null", "double" ], "doc" : "Type inferred from '33.13'" }, { "name" : "Low", "type" : [ "null", "double" ], "doc" : "Type inferred from '33.1'" }, { "name" : "Close", "type" : [ "null", "double" ], "doc" : "Type inferred from '33.13'" }, { "name" : "Volume", "type" : [ "null", "long" ], "doc" : "Type inferred from '400'" } ] }and the kite-dataset command to create a Stocks dataset:kite-dataset create dataset:hdfs:/user/hdfs/Stocks -s Stocks.avsc
The following directory is created in HDFS:
- In search results, the Stocks dataset appears as follows:
- Click the Stocks link.
- Click the Schema tab. The schema displays:
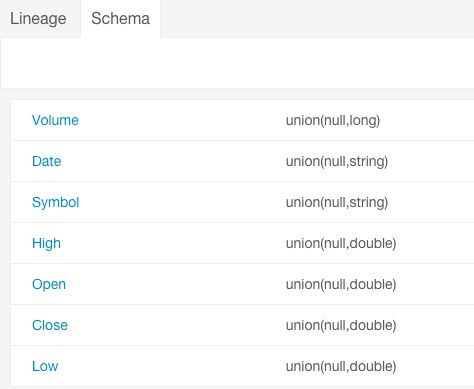
Each subfield of the Stocks record is an entity of type field.