Apache Hive Known Issues
This topic also contains:
CREATE TABLE EXTERNAL commands run very slowly on Amazon S3
When you run a CREATE EXTERNAL TABLE command on Amazon S3 storage, the command runs extremely slowly and might not complete. This usually occurs for tables that have pre-existing, nested data. There is no known workaround.
Affected Versions: CDH 5.15.0
Cloudera Bug: CDH-68833
Workaround: None
Addressed in release/refresh/patch: CDH 5.15.1 and later
Apache Hive vulnerabilities CVE-2018-1282 and CVE-2018-1284
This security bulletin covers two vulnerabilities discovered in Hive.
CVE-2018-1282: JDBC driver is susceptible to SQL injection attack if the input parameters are not properly cleaned
This vulnerability allows carefully crafted arguments to be used to bypass the argument-escaping and clean-up that the Apache Hive JDBC driver does with PreparedStatement objects.
If you use Hive in CDH, you have the option of using the Apache Hive JDBC driver or the Cloudera Hive JDBC driver, which is distributed by Cloudera for use with your JDBC applications. Cloudera strongly recommends that you use the Cloudera Hive JDBC driver and offers only limited support for the Apache Hive JDBC driver. If you use the Cloudera Hive JDBC driver you are not affected by this vulnerability.
Mitigation: Upgrade to use the Cloudera Hive JDBC driver, or perform the following actions in your Apache Hive JDBC client code or application when dealing with user provided input in PreparedStatement objects:
- Avoid passing user input with the PreparedStatement.setBinaryStream method, and
- Sanitize user input for the PreparedStatement.setString method by replacing all occurrences of \' (backslash, single quotation mark) to ' (single quotation mark).
Detected by: CVE-2018-1282 was detected by Bear Giles of Snaplogic
CVE-2018-1284: Hive UDF series UDFXPathXXXX allows users to pass carefully crafted XML to access arbitrary files
If Hive impersonation is disabled and / or Apache Sentry is used, a malicious user might use any of the Hive xpath UDFs to expose the contents of a file on the node that is running HiveServer2 which is owned by the HiveServer2 user (usually hive).
Mitigation: Upgrade to a release where this is fixed. If xpath functions are not currently used, disable them with Cloudera Manager by setting the hive.server2.builtin.udf.blacklist property to xpath,xpath_short,xpath_int,xpath_long,xpath_float,xpath_double,xpath_number,xpath_string in the HiveServer2 Advanced Configuration Snippet (Safety Valve) for hive-site.xml. For more information about setting this property to blacklist Hive UDFs, see the Cloudera Documentation.
Products affected: Hive
Releases affected:
- CDH 5.12 and earlier
- CDH 5.13.0, 5.13.1, 5.13.2, 5.13.3
- CDH 5.14.0, 5.14.1, 5.14.2
Users affected: All
Severity (Low/Medium/High): High
Impact: SQL injection, compromise of the hive user account
CVE: CVE-2018-1282, CVE-2018-1284
Immediate action required: Upgrade to a CDH release with the fix or perform the above mitigations.
- CDH 5.14.4 and higher
- CDH 5.15.0 and higher
For the latest update on these issues, see the corresponding Knowledge article:
TSB 2018-299: Hive Vulnerabilities CVE-2018-1282 and CVE-2018-1284
Missing results in Hive, Spark, Pig, Custom MapReduce jobs, and other Java applications when filtering Parquet data written by Impala
Apache Hive and Apache Spark rely on Apache Parquet's parquet-mr Java library to perform filtering of Parquet data stored in row groups. Those row groups contain statistics that make the filtering efficient without having to examine every value within the row group.
Recent versions of the parquet-mr library contain a bug described in PARQUET-1217. This bug causes filtering to behave incorrectly if only some of the statistics for a row group are written. Starting in CDH 5.13, Apache Impala populates statistics in this way for Parquet files. As a result, Hive and Spark may incorrectly filter Parquet data that is written by Impala.
In CDH 5.13, Impala started writing Parquet's null_count metadata field without writing the min and max fields. This is valid, but it triggers the PARQUET-1217 bug in the predicate push-down code of the Parquet Java library (parquet-mr). If the null_count field is set to a non-zero value, parquet-mr assumes that min and max are also set and reads them without checking whether they are actually there. If those fields are not set, parquet-mr reads their default value instead.
For integer SQL types, the default value is 0, so parquet-mr incorrectly assumes that the min and max values are both 0. This causes the problem when filtering data. Unless the value 0 itself matches the search condition, all row groups are discarded due to the incorrect min/max values, which leads to missing results.
- Hive
- Spark
- Pig
- Custom MapReduce jobs
- CDH 5.13.0, 5.13.1, 5.13.2, and 5.14.0
- CDS 2.2 Release 2 Powered by Apache Spark and earlier releases on CDH 5.13.0 and later
Who Is Affected: Anyone writing Parquet files with Impala and reading them back with Hive, Spark, or other Java-based components that use the parquet-mr libraries for reading Parquet files.
Severity (Low/Medium/High): High
Impact: Parquet files containing null values for integer fields written by Impala produce missing results in Hive, Spark, and other Java applications when filtering by the integer field.
-
Upgrade
You should upgrade to one of the fixed maintenance releases mentioned below.
-
Workaround
This issue can be avoided at the price of performance by disabling predicate push-down optimizations:-
In Hive, use the following SET command:
SET hive.optimize.ppd = false;
-
In Spark, disable the following configuration setting:
--conf spark.sql.parquet.filterPushdown=false
-
- CDH 5.13.3 and higher
- CDH 5.14.2 and higher
- CDH 5.15.0 and higher
- CDS 2.3 Release 2 and higher
For the latest update on this issue, see the corresponding Knowledge Base article:
Hive Replications Can Fail Intermittently
Hive replication jobs can fail intermittently during the first step of replication while exporting Hive metadata. When this happens, the following message displays in Cloudera Manager: The remote command failed with error message: Hive Replication Export Step failed. The likelihood that this error can occur increases with the length of time it takes to export Hive metadata. If you have a very large Hive deployment (those containing many tables and partitions), and/or environments in which the Hive metastore server is under-resourced, you are more likely to see this issue. However, having many tables and partitions or having an under-resourced Hive metastore server do not cause this issue. The problem is caused by a bug and the only solution is to upgrade to a later release. Cloudera strongly recommends upgrading to anyone running Hive Replication and using Cloudera Manager 5.13.0 or 5.13.1 versions.
Affected Products: Cloudera Manager
Affected Versions: Cloudera Manager 5.13.0, 5.13.1
Who is Affected: Anyone using Hive Replication
Severity (Low/Medium/High): High
Cause and Impact: A file is created during the Hive Export Phase, and is used by later phases, such as the Transfer/Import phases. Because of a bug, sometimes the file is overwritten by another process. Hive Replication can thus fail intermittently because of FileNotFoundExceptions. A retry may or may not resolve the issue. This issue can potentially affect some or all Hive replication schedules.
Workaround: Upgrade to Cloudera Manager 5.13.2, 5.14.1, or higher versions
Addressed in release/refresh/patch: Cloudera Manager 5.13.2, 5.14.1, or higher versions.
For the latest updates on this issue, see the following corresponding Knowledge Base article:
TSB 2018-276: Hive Replications can fail intermittently in Cloudera Manager 5.13.0, 5.13.1 versions
Slow or stalled queries under highly concurrent write workloads when Sentry + Hive are used, caused by a Hive metastore deadlock
In the affected releases, some workloads can cause a deadlock in the Hive metastore. There are internal automated mechanisms to recover from such deadlocks. However, in highly concurrent write-heavy workloads, recovery from the deadlock is slower than the buildup of pending queries or operations. Therefore, the Hive metastore spends a lot of time in the deadlocked state, leading to slow performance or hangs. This in turn impacts performance of HiveServer2 and query performance.
After upgrading to an affected release, if performance of your workloads has worsened dramatically or workloads have stalled, you might be encountering this issue. If MySQL or MariaDB are configured as the Hive metastore database, the following error message appears in the Hive metastore log file, which confirms this issue as the cause:
com.mysql.jdbc.exceptions.jdbc4.MySQLTransactionRollbackException: Lock wait
timeout exceeded; try restarting transaction
Affected Versions: CDH 5.13.0, 5.13.1, 5.13.2, 5.14.0, and 5.14.1
Affected Components: When Hive and Sentry are running together
- If you are using an affected version of CDH and using Hive and Sentry, refer to the "Workaround" section below.
- If you are using an affected version, but are not using Hive and Sentry, no action is required.
- If you are not using an affected version and you are using Hive and Sentry, do not upgrade to an affected version of CDH.
Severity (Low/Medium/High): High
Impact: Slow performance of the Hive metastore or Hive queries and eventually the metastore hangs.
- In Cloudera Manager, go to your cluster > Hive service > Configuration, and search for Hive Metastore Server Advanced Configuration Snippet (Safety Valve) for hive-site.xml.
- Click the plus sign (+) twice, and add the following values:
- Set hive.metastore.transactional.event.listeners to an empty value.
- Set hive.metastore.event.listeners to org.apache.hive.hcatalog.listener.DbNotificationListener
-
Restart the Hive metastore instances so the configuration changes can be applied.
The following figure shows the configuration details:
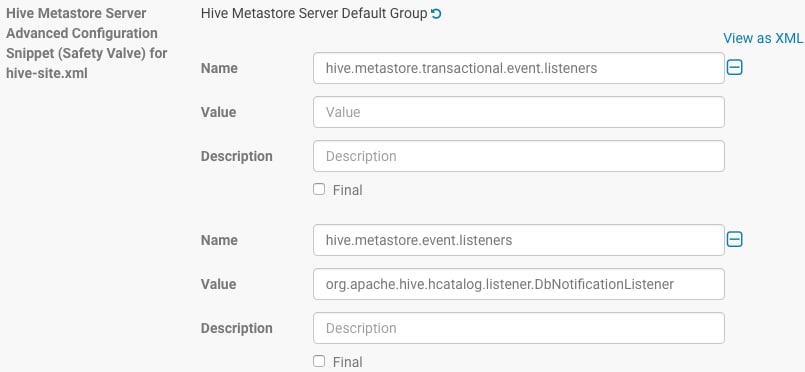
Applying this workaround may cause some DDL queries, such as queries where a table is dropped and a new table is created with the same name, to fail with unexpected No valid privileges errors. Re-run such queries to resolve this error.
Addressed in release/refresh/patch: CDH 5.13.3, CDH 5.14.2
Beeline fails with "Error: Unrecognized column type: UNIONTYPE"
When the following conditions are met, Beeline fails and returns the error Error: Unrecognized column type: UNIONTYPE:
- Submit a query with Beeline that returns data in the result set from columns that are set to the UNIONTYPE data type.
- Beeline option --incremental= is set to true. By default, this option is set to false in CDH.
Affected Version: CDH 5.14 and higher
Cloudera Bug: CDH-63768
Workaround: Set the Beeline option --incremental= to false on the command line. See the Beeline documentation for information about setting this option.
DirectSQL with PostgreSQL
Hive doesn't support Hive direct SQL queries with PostgreSQL database. It only supports this feature with MySQL, MariaDB, and Oracle. With PostgresSQL, direct SQL is disabled as a precaution because there have been issues reported upstream. For example, it has been reported that it is not possible to fall back on DataNucleus in case of some failures, plus some other non-standard behaviors. For more information, see Hive Configuration Properties.
Affected Versions: CDH 5.13.0 and higher
Bug: None
Cloudera Bug: CDH-63059
Increase width of columns used for general configuration in the metastore
HIVE-12274 was only partially backported to CDH. The HMS backend database changes are not included in CDH, as it would be a backward compatibility breaking change. The HMS schema won't be changed automatically during the update. It needs to be changed manually.
Affected Versions: CDH 5.13.0 and higher
Bug: HIVE-12274
Workaround: Change the HMS schema manually.
Hive SSL vulnerability bug disclosure
If you use Cloudera Hive JDBC drivers to connect your applications with HiveServer2, you are not affected if:
- SSL is not turned on, or
- SSL is turned on but only non-self-signed certificates are used.
If neither of the above statements describe your deployment, please read Security Bulletin Apache Hive SSL Vulnerability Bug Disclosure for further details.
Leak of threads from getInputPaths and getInputSummary thread pool can degrade HiveServer2 performance
The optimization made to Utilities.getInputPaths() method with HIVE-15546 introduced a thread pool that is not shut down when its threads complete their work. This leads to a thread leak for each query that runs in HiveServer2 and the leaked threads are not removed automatically. When queries span multiple partitions, the number of threads spawned increases, but they are never reduced. After 10,000 threads are reached, HiveServer2 performance slows.
Affected Versions: CDH 5.11.0, 5.11.1, 5.11.2, 5.12.0, 5.12.1
Fixed in Versions: 5.12.2, 5.13.0 and higher
Bug: HIVE-16949
Cloudera Bug: CDH-57789
Resolution: Upgrade to a fixed version of CDH or use the workaround.
Workaround: Upgrading to a fixed version of CDH is the preferred resolution for this issue, but if that is not immediately possible, you can set the property to 1 in Cloudera Manager for managed clusters. If your cluster is not managed, set hive.exec.input.listing.max.threads=1 in the hive-site.xml file.
Hive metastore canary fails
The Hive metastore canary can fail in environments where the Hive-Sentry metastore plugin is deployed and where there are over one million Hive tables and partitions. In this situation, Sentry times out while waiting to receive a full snapshot from the Hive metastore.
Affected Versions: CDH 5.9.2, CDH 5.10.1, CDH 5.10.2, and CDH 5.11.1., 5.11.2, and CDH 5.12
Cloudera Bug: CDH-55255
Resolution: Use workaround.
Workaround: If your environment contains over one million Hive tables and partitions, before you upgrade to one of the affected versions, increase the Sentry timeout property for the metastore plugin to at least 10 to 20 minutes (600,000 to 1,200,000 ms). In Cloudera Manager, set the Hive Service Advanced Configuration Snippet (Safety Valve) for sentry-site.xml as follows:
- Name: sentry.hdfs.service.client.server.rpc-connection-timeout
- Value: 600000
After setting this safety valve, monitor your environment. If the Hive metastore canary continues to fail, increase the value by four-minute increments until Sentry can receive the full snapshot from the metastore. For example, if you set the safety valve to 600,000 ms and the canary fails, increase it to 840,000 ms. If it still fails, increase the value to 1,080,000 ms, and so on.
Hive Local Mode is not supported in production environments
Cloudera does not currently support the use of Hive Local Mode in production environments. This mode is set with the hive.exec.mode.local.auto property. Use this mode for testing purposes only.
Affected Versions: Not applicable.
Bug: None.
Workaround: None.
INSERT INTO overwrites EXTERNAL tables on the local filesystem
When EXTERNAL tables are located on the local filesystem (URIs beginning with file://), the INSERT INTO statement overwrites the table data. Defining EXTERNAL tables on the local filesystem is not a well-documented practice so its behavior is not well defined and is subject to change.
Affected Versions: CDH 5.10
Fixed in Version: CDH 5.10.1
Cloudera Bug: CDH-47856
Workaround: Change the table location from the local filesystem to an HDFS location.
Built-in version() function is not supported
Cloudera does not currently support the built-in version() function.
Affected Versions: Not applicable.
Cloudera Bug: CDH-40979
Workaround: None.
EXPORT and IMPORT commands fail for tables or partitions with data residing on Amazon S3
The EXPORT and IMPORT commands fail when the data resides on the Amazon S3 filesystem because the default Hive configuration restricts which file systems can be used for these statements.
Bug: None.
Resolution: Use workaround.
Workaround: Add S3 to the list of supported filesystems for EXPORT and IMPORT by setting the following property in the HiveServer2 Advanced Configuration Snippet (Safety Valve) for hive-site.xml in Cloudera Manager (select Hive service > Configuration > HiveServer2):
<property> <name>hive.exim.uri.scheme.whitelist</name> <value>hdfs,pfile,s3a</value> </property>
Hive queries on MapReduce 1 cannot use Amazon S3 when the Cloudera Manager External Account feature is used
Hive queries that read or write data to Amazon S3 and use the Cloudera Manager External Account feature for S3 credential management do not work with MapReduce 1 (MRv1) because it is deprecated on CDH.
Cloudera Bug: CDH-45201
Resolution: Use workaround.
Workaround: Migrate your cluster from MRv1 to MRv2. See Migrating from MapReduce (MRv1) to MapReduce (MRv2).
ALTER PARTITION does not work on Amazon S3 or between S3 and HDFS
Cloudera recommends that you do not use ALTER PARTITION on S3 or between S3 and HDFS.
Cloudera Bug: CDH-42420
Hive cannot drop encrypted databases in cascade if trash is enabled
Affected Versions: CDH 5.7.0, 5.7.1, 5.7.2, 5.7.3, 5.7.4, 5.7.5, 5.7.6, 5.8.0, 5.8.1, 5.8.2, 5.8.3, 5.8.4, 5.8.5, 5.9.0, 5.9.1, 5.9.2, 5.10.0, 5.10.1, 5.11.0, 5.11.1
Fixed in Versions: CDH 5.7.7, 5.8.6, 5.9.3, 5.10.2, 5.11.2, 5.12.0
Bug: HIVE-11418
Cloudera Bug: CDH-29913
Workaround: Remove each table using the PURGE keyword (DROP TABLE table PURGE). After all tables are removed, remove the empty database (DROP DATABASE database).
Potential failure of "alter table <schema>.<table> rename to <schema>.<new_table_name>"
When Hive renames a managed table, it always creates the new renamed table directory under its database directory in order to preserve the database/table hierarchy. The renamed table directory is created under the default database.
Considering that the encryption of a filesystem is part of the evolution hardening of a system (where the system and the data contained in it already exist) and a database can be already created without the location set (because it is not strictly required) and the default database is outside the same encryption zone (or in a no-encryption zone) the alter table rename operation fails.
Affected Version: CDH 5.5 only
Cloudera Bug: CDH-63062
Resolution: Use workaround.
Workaround: Use the following statements:
CREATE DATABASE database_encrypted_zone LOCATION '/hdfs/encrypted_path/database_encrypted_zone'; USE database_encrypted_zone;
CREATE TABLE rename_test_table LOCATION 'hdfs/encrypted_path/database_encrypted_zone/rename_test'; ALTER TABLE rename_test_table RENAME TO test_rename_table;
The renamed table is created under the default database.
Hive upgrade from CDH 5.0.5 fails on Debian 7.0 if a Sentry 5.0.x release is installed
: error processing
/var/cache/apt/archives/hive_0.13.1+cdh5.2.0+221-1.cdh5.2.0.p0.32~precise-cdh5.2.0_all.deb
(--unpack): trying to overwrite '/usr/lib/hive/lib/commons-lang-2.6.jar', which is also
in package sentry 1.2.0+cdh5.0.5
This is because of a conflict involving commons-lang-2.6.jar.Cloudera Bug: CDH-25450
Workaround: Upgrade Sentry first and then upgrade Hive. Upgrading Sentry deletes all the JAR files that Sentry has installed under /usr/lib/hive/lib and installs them under /usr/lib/sentry/lib instead.
Hive creates an invalid table if you specify more than one partition with alter table
Hive (in all known versions from 0.7) allows you to configure multiple partitions with a single alter table command, but the configuration it creates is invalid for both Hive and Impala.
Bug: None
Resolution: Use workaround.
Workaround:
ALTER TABLE page_view ADD PARTITION (dt='2008-08-08', country='us') location '/path/to/us/part080808' PARTITION (dt='2008-08-09', country='us') location '/path/to/us/part080809';should be replaced with:
ALTER TABLE page_view ADD PARTITION (dt='2008-08-08', country='us') location '/path/to/us/part080808'; ALTER TABLE page_view ADD PARTITION (dt='2008-08-09', country='us') location '/path/to/us/part080809';
Commands run against an Oracle backed metastore may fail
javax.jdo.JDODataStoreException Incompatible data type for column TBLS.VIEW_EXPANDED_TEXT : was CLOB (datastore), but type expected was LONGVARCHAR (metadata). Please check that the type in the datastore and the type specified in the MetaData are consistent.
This error may occur if the metastore is run on top of an Oracle database with the configuration property datanucleus.validateColumns set to true.
Bug: None
Workaround: Set datanucleus.validateColumns=false in the hive-site.xml configuration file.
Hive Web Interface is not supported
Cloudera no longer supports the Hive Web Interface because of inconsistent upstream maintenance of this project.
Bug: DISTRO-77
Resolution: Use workaround
Workaround: Use Hue and Beeswax instead of the Hive Web Interface.
Hive might need additional configuration to make it work in a federated HDFS cluster
Failed with exception Renames across Mount points not supported
Cloudera Bug: CDH-9430
Resolution: No software fix planned; use the workaround.
<property>
<name>hive.exec.scratchdir</name>
<value>/user/${user.name}/tmp</value>
</property> Cannot create archive partitions with external HAR (Hadoop Archive) tables
ALTER TABLE ... ARCHIVE PARTITION is not supported on external tables.
Cloudera Bug: CDH-9638
Workaround: None
Setting hive.optimize.skewjoin to true causes long running queries to fail
Bug: None
Workaround: None
Object types Server and URI are not supported in "SHOW GRANT ROLE roleName on OBJECT objectName"
Cloudera Bug: CDH-19430
Workaround: Use SHOW GRANT ROLE roleNameto list all privileges granted to the role.
Kerberized HS2 with LDAP authentication fails in a multi-domain LDAP case
In CDH 5.7, Hive introduced a feature to support HS2 with Kerberos plus LDAP authentication; but it broke compatibility with multi-domain LDAP cases on CDH 5.7.x and C5.8.x versions.
Affected Versions: CDH 5.7.1, CDH 5.8.0, and CDH 5.8.1
Fixed in Versions: CDH 5.7.2 and higher, CDH 5.8.2 and higher
Bug: HIVE-13590.
Workaround: None.
With encrypted HDFS, 'drop database if exists <db_name> cascade' fails
Hive cannot drop encrypted databases in cascade if trash is enabled.
Affected Versions: CDH 5.7.0 - 5.7.6, CDH 5.8.0 - 5.8.5, CDH 5.9.0 - 5.9.2, CDH 5.10.0 - 5.10.1, CDH 5.11.0 - 5.11.1
Fixed in Versions: CDH 5.7.7, 5.8.6, 5.9.3, 5.10.2, 5.11.2, 5.12.0
Bug: HIVE-11418
Cloudera Bug: CDH-29913
Workaround: Remove each table, using the PURGE keyword (DROP TABLE table PURGE). After all tables are removed, remove the empty database (DROP DATABASE database).
HCatalog Known Issues
WebHCatalog does not work in a Kerberos-secured federated cluster
Cloudera Bug: CDH-12416
Resolution: None planned.
Workaround:None
Hive-on-Spark (HoS) Known Issues
Hive on Spark queries are failing with "Timed out waiting for client to connect" for an unknown reason
If this exception is preceded by logs of the form "client.RpcRetryingCaller: Call exception...". Then this failure is due to an unavailable HBase service. On a secure cluster, spark-submit will try to obtain delegation tokens from HBase, even though HoS doesn't necessarily need them. So if HBase is unavailable, then spark-submit throws an exception.
Cloudera Bug: CDH-59591
Affected Versions: CDH 5.7.0 and higher
Workaround: Fix the HBase service, or set spark.yarn.security.tokens.hbase.enabled to false.
Intermittent inconsistent results for Hive-on-Spark with DECIMAL-type columns
SQL queries executed using Hive-on-Spark (HoS) can produce inconsistent results intermittently if they use a GROUP BY clause (user-defined aggregate functions, or UDAFs) on DECIMAL data type columns.
Hive queries are affected if all of the following conditions are met:
- Spark is used as the execution engine (hive.execution.engine=spark) in the Affected Versions listed below.
- The property spark.executor.cores is set to a value greater than 1.
-
The query uses a UDAF that requires a GROUP BY clause on a DECIMAL data type column.
For example:COUNT(DISTINCT<decimal_column_name>), SELECT SUM(<column>) GROUP BY<decimal_column>You can use the EXPLAIN command to view the query execution plan to check for the presence of the GROUP BY clause on a DECIMAL data type column.
Bug: HIVE-16257, HIVE-12768
Severity: High
- CDH 5.4.0, 5.4.1, 5.4.2, 5.4.3, 5.4.4, 5.4.5, 5.4.7, 5.4.8, 5.4.9, 5.4.10, 5.4.11
- CDH 5.5.0, 5.5.1, 5.5.2, 5.5.3, 5.5.4, 5.5.5, 5.5.6
- CDH 5.6.0, 5.6.1
- CDH 5.7.0, 5.7.1, 5.7.3, 5.7.4, 5.7.5, 5.7.6
- CDH 5.8.0, 5.8.1, 5.8.2, 5.8.3, 5.8.4
- CDH 5.9.0, 5.9.1
- CDH 5.10.0, 5.10.1
- CDH 5.8.5 and higher
- CDH 5.9.2 and higher
- CDH 5.11.0 and higher
Workaround: To fix this issue, set spark.executor.cores=1 for sessions that run queries that use the GROUP BY clause on DECIMAL data type columns. This might cause performance degradation for some queries. Cloudera recommends that you run performance validations before setting this property.
- In the Cloudera Manager Admin console, go to the Hive service, and select .
- In the Search text box, type spark.executor.cores and press Enter.
- Set Spark Executor Cores to 1.
- Click Save Changes.
Hive-on-Spark throws exception for a multi-insert with a join query
A multi-insert combined with a join query with Hive on Spark (Hos) sometimes throws an exception. It occurs only when multiple parts of the resultant operator tree are executed on the same executor by Spark.
Affected Versions: CDH 5.7.0
Fixed in Versions: CDH 5.7.1
Bug: HIVE-13300
Cloudera Bug: CDH-38458
Workaround: Run inserts one at a time.
NullPointerException thrown when a Spark session is reused to run a mapjoin
Some Hive-on-Spark (HoS) queries might fail with a NullPointerException if a Spark dependency is not set.
Affected Version: CDH 5.7.0
Bug: HIVE-12616
Cloudera Bug: CDH-38514
Workaround: Configure Hive to depend on the Spark (on YARN) service in Cloudera Manager.
Large Hive-on-Spark queries might fail in Spark tasks with ExecutorLostFailure
The root cause is java.lang.OutOfMemoryError: Unable to acquire XX bytes of memory, got 0. Spark executors can OOM because of a failure to correctly spill shuffle data from memory to disk.
Cloudera Bug: CDH-38642
Workaround: Run this query using MapReduce.
Hive-on-Spark2 is not Supported
Hive-on-Spark is a CDH component that has a dependency on Spark 1.6. Because CDH components do not have any dependencies on Spark 2, Hive-on-Spark does not work with the Cloudera Distribution of Apache Spark 2.