Known Issues and Workarounds in Cloudera Navigator Data Management
The sections below provide information about current known issues in Cloudera Navigator data management component.
Continue reading:
- Access, Login, or Cloudera Navigator Console Issues
- Cloudera Manager Configuration Issues
- Multi-Cluster Environments
- AWS and Amazon S3
- Microsoft Azure
- Data Stewardship Dashboard
- Search and Managed Metadata
- Hive, Hue, Impala, Pig
- Navigator Audit Server
- Navigator Metadata Server
- Purge
- Spark
- Upgrade Issues and Limitations
Access, Login, or Cloudera Navigator Console Issues
Navigator Metadata Server fails to start with InvalidClassException, local class incompatible
Navigator Metadata Server fails to start (red status in Cloudera Manager) and the Metadata Server log includes the following exception:
2018-09-06 10:38:20,786 WARN jndi [main]: java.io.InvalidClassException: com.mchange.v2.c3p0.WrapperConnectionPoolDataSource; local class incompatible: stream classdesc serialVersionUID = 7806429541739165290, local class serialVersionUID = -7086951306718003710
Even if Navigator Metadata Server starts once, it may encounter this problem at a later time, depending on which JAR file is loaded.
Workaround: See Knowledge Base Article Navigator Metadata Server fails to start with "local class incompatible" error
Affects version: Cloudera Manager version 5.15.1 (Navigator 2.14.1)
Fixed version: Cloudera Manager version 5.15.2 (Navigator 2.14.2)
Cloudera Issue: NAV-6724, TSB-342
SAML authentication fails with "Cloudera Manager Only" setting
With the following combination of Cloudera Manager configuration properties set, authentication to Navigator fails:
- Authentication Backend Order: Cloudera Manager Only
- External Authentication Type: SAML
To configure Navigator for SAML authentication, use an Authentication Backend Order other than "Cloudera Manager Only".
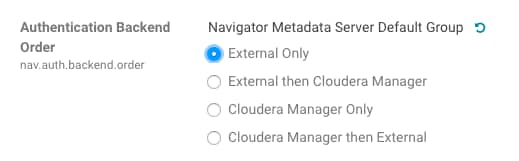
Cloudera Issue: NAV-6211
Cloudera Navigator console page display blocked
The Roboto font used in some of the Cloudera Navigator console text is transparently loaded by the console from Google CDN (content delivery network) https://fonts.googleapis.com/ and https://fonts.gstatic.com. If the network environment prevents access to and from these paths, the Cloudera Navigator console cannot load the font, the page hangs, and the console becomes unusable.
- For environments that limit access to and from the public internet, modify the firewall configuration to allow traffic from https://fonts.googleapis.com/ and https://fonts.gstatic.com.
- For environments that restrict access and do not want to allow traffic from the font CDN, modify the firewall configuration to reject access attempts immediately.
- For environments with no DNS access to the public internet, the only workarounds are to obtain the Roboto font and install locally, or hosting your own internal font CDN with fonts from https://fonts.googleapis.com/ and https://fonts.gstatic.com obtained from another network.
Affects version: Cloudera Manager 5.11.1, 5.10.2, 5.10.1, 5.10.0 (Navigator 2.10.1, 2.9.2, 2.9.1, 2.9.0)
Fixed in version: Cloudera Manager 5.12.0, 5.11.2 (Navigator 2.11.0, 2.10.2)
Cloudera Issues: NAV-4871, NAV-4866
Unlimited description through API only
As of Cloudera Manager version 5.15.0 and 5.14.2, name values can be as long as 500 characters and description values are unlimited. However, the Navigator console limits manual entry of the name to 40 characters and descriptions to 500 characters. When you edit the existing metadata for an entity, if the text is longer than the console limits, you won't be able to save changes to the text.
Fixed in version: Cloudera Manager 5.15.0, 5.14.2, 5.13.3 (Navigator 2.14.0, 2.13.2, 2.12.3)
Cloudera Issue: NAV-6228
Internet Explorer 11 document mode issue
When using Microsoft Internet Explorer 11 to access the Cloudera Navigator console, the login page does not display properly due to an issue with that browser's Compatibility View and certain document modes (see the Microsoft Technet article for details). As of Cloudera Navigator 2.10.1, a warning prompt now displays if the Internet Explorer's document mode is set to IE7 or lower, to alert you to the issue, but prior releases display a blank page rather than the login page.
Workaround: Open the Compatibility View Settings (under the Internet Explorer options menu) and remove the setting for the domain or website. Or use another browser to access the Cloudera Navigator console. Supported browsers include Mozilla Firefox, Google Chrome, or Microsoft Edge.
Affects version: Cloudera Manager 5.11.0, 5.10.x (Navigator 2.10.0, 2.9.x)
Fixed in version: Cloudera Manager 5.11.1 (Navigator 2.10.1)
Cloudera Issues: NAV-3743, NAV-4381
Error message ("not authorized") when logging in
The Cloudera Navigator console saves the state of the last URL accessed when you log out, and opens the same page at your next login. If two different users log in to Navigator using the same browser tab, the state of the first user applies to the second. If the second user does not have permissions to that section of the page, that user receives an error message.
Workaround: Close the browser tab and log in on a new tab. The state is cleared, and the access error message does not appear.
Affects version: Cloudera Manager 5.8.x, 5.7.x (Navigator 2.9.x, 2.8.x)
Fixed in version: Cloudera Manager 5.11 (Navigator 2.10)
Cloudera Issue: NAV-3425
Cloudera Manager Configuration Issues
Adding a blank audit filter removes filter configuration property
In Cloudera Manager, when adding an empty rule to a service's Audit Event Filter and then saving the change, all existing audit event filters are lost. The filter configuration property is removed from Cloudera Manager's list of configuration properties. Reverting the change in the History and Rollback does not restore the previous filters nor reproduce the filter property.
Affected versions: All Cloudera Navigator versions
Fixed in version: N/A
Cloudera Issue: NAV-6096
Overriding safety valve settings disables audit and lineage features
Customers or third party applications such as Unravel may require that hive.exec.post.hooks is configured in a HiveServer2 safety valve. Cloudera Manager will comment out the hive.exec.post.hooks value that is configured if audit or lineage is enabled for Hive. The safety valve content shows the commented code:
<!--'hive.exec.post.hooks', originally set to 'com.cloudera.navigator.audit.hive.HiveExecHookContext,org.apache.hadoop.hive.ql.hooks.LineageLogger' (non-final), is overridden below by a safety valve-->
This automated change disables Navigator's auditing and lineage features without notification.
Workaround: To fix this problem, manually merge the original HiveServer2 safety valve content for hive.exec.post.hooks with the new value. For example, in the case of Unravel, the new safety valve would look like the following:
<property> <name>hive.exec.post.hooks</name> <value>com.unraveldata.dataflow.hive.hook.HivePostHook,com.cloudera.navigator.audit.hive.HiveExecHookContext,org.apache.hadoop.hive.ql.hooks.LineageLogger</value> <description>for Unravel, from unraveldata.com</description> </property>
Cloudera Issue: NAV-5331
Cloudera Manager audit events case-sensitive when using PostgreSQL
When Cloudera Manager and Navigator Audit Server are installed using PostgreSQL databases, the behavior of queries run from the Navigator console is different between the two databases. The result is that Cloudera Manager events are returned only if the query values match the case of the event values as they are stored in the Cloudera Manager database.
For example, use "HiveReplicationCommand" instead of HIVEREPLICATIONCOMMAND as it appears in the Audit log.
Cloudera Issue: NAV-6141
Multi-Cluster Environments
Extractors not working in multi-cluster environment
When Navigator Metadata Server is started with a fresh storage directory on versions 5.12.0 or later, extractors are not working when a single Cloudera Manager is managing multiple clusters.
Affects version: Cloudera Manager 5.15.0, 5.14.3, 5.14.2, 5.14.1, 5.14.0, 5.13.1, 5.13.0, 5.12.1, 5.12.0 (Navigator 2.14.0, 2.13.3, 2.13.2, 2.13.1, 2.13.0, 2.12.1, 2.12.0, 2.11.1, 2.11.0)
Fixed in version: Cloudera Manager 5.16.1, 5.15.1, 5.14.4 (Navigator 2.15.1, 2.14.1, 2.13.4)
Cloudera Issue: NAV-6145
Table-to-HDFS links not established when Navigator supports multiple, high-availability clusters
When Navigator extracts metadata for multiple clusters and when the clusters are configured for high availability operation, Navigator does not correctly link tables to their HDFS backing data. The result is that lineage between Hive tables and their physical data are not created. In addition, some Hive table metadata that is derived from the backing files is not available.
You may see errors in the log such as the following:
2018-02-19 09:01:32,999 ERROR com.cloudera.nav.persist.impl.CompositeLinker [CDHExecutor-0-CDHUrlClassLoader@01010d7e]: Internal error while linking.java.lang.IllegalArgumentException: expected one element but was: <com.cloudera.nav.core.model.Source@b22e68ba, com.cloudera.nav.core.model.Source@5b1bac2c>
Affects version: Cloudera Manager 5.13.x, 5.12.x (Navigator 2.12.x, 2.11.x)
Fixed in version: Cloudera Manager 5.14.0 (Navigator 2.13.0)
Cloudera Issue: NAV-5749
AWS and Amazon S3
Update AWS Credentials from the same AWS account
After configuring Cloudera Navigator with a specific set of AWS Credentials for Amazon S3, any future changes to the credentials (for example, if you rotate credentials on a regular basis) must be for the same AWS account (IAM user). Changing the AWS Credentials to those of a different IAM user results in errors from the Amazon Simple Queue Service (used transparently by Cloudera Navigator).
Workaround: If a new key is provided to Cloudera Navigator, the key must belong to the same AWS account as the prior key.
Affects version: Cloudera Manager 5.10 and later (Navigator 2.9)
Cloudera Issues: NAV-3990
Unnamed folders on Amazon S3 not extracted
Unnamed folders on Amazon S3 are not extracted by Navigator, but the content of the folders is extracted. For example, a top-level folder the top level folder in the bucket has no name (for example, /bucket//folder/file), it is extracted as /bucket/folder/file.
Affects version: Cloudera Manager 5.10 and later (Navigator 2.9)
Cloudera Issue: NAV-3981
Implicit folders are not marked as deleted
If an implicit folder is deleted in Amazon S3, it does not appear as deleted in Cloudera Navigator console.
Workaround: To prevent folders deleted from Amazon S3 from appearing in Navigator Search results, include implicit:false in the search query.
Affects version: Cloudera Manager 5.10 and later (Navigator 2.9)
Cloudera Issue: NAV-3802
Extraction delayed while Amazon S3 inconsistent
Inconsistencies that occur in AWS (for example, due to eventual consistency) can delay Navigator extraction of metadata and lineage from Amazon S3. When Cloudera Navigator detects an inconsistency, extraction may stop until the inconsistency is resolved in AWS. Cloudera Navigator will retry at the next scheduled extraction.
Affects version: Cloudera Manager 5.10 and later (Navigator 2.9)
Cloudera Issue: NAV-4028
Microsoft Azure
Less Secure Credentials Protection Policy can expose Azure credentials in audit logs
When you use Cloudera Manager to configure the ADLS Connector service using the Less Secure option for the Credentials Protection Policy, it is possible for Hive audit logs to include Microsoft Azure credentials. If you are using Navigator Audit Server, these credentials may appear in audit reports. To mitigate this problem, make sure that access to Hive logs is appropriately controlled and that Navigator users with Auditing Viewer roles are cleared to have access to the Hive credentials.
Fixed in version: Cloudera Manager 5.16.1, 5.15.1, 5.14.2 (Navigator 2.15.1, 2.14.1, 2.13.2)
Cloudera Issues: NAV-5861, CDH-56241
Data Stewardship Dashboard
Counts displayed in Dashboard and Search may differ
Counts for databases, tables, views, and other entities displayed in Cloudera Navigator Dashboard can differ from Search values for the same objects. The Dashboard displays data from the Navigator Audit Server, which contains actual counts captured continuously. On the other hand, Search (Solr) returns data that has been periodically extracted from HMS (Hive Metadata Server). Tables, databases, views, or other objects created or destroyed between extracts are not reflected in values displayed by Search (Solr), but they are contained in the audit data displayed in the Dashboard.
Fixed in version: Cloudera Manager 5.11.0 (Navigator 2.10.0)
Cloudera Issue: NAV-4192
Tables Populated count reflects INSERT and UPDATE statements
The Tables Populated display widget in the Data Stewardship Dashboard reflects the number of times that a table has been loaded with data, such as through INSERT and UPDATE statements—not the number of unique tables loaded. For example, a single table to which data is added (through 6 INSERT statements) and that has also had 4 UPDATE statements submitted in the same period would report Tables Populated as 10.
Cloudera Issue: NAV-3886
Search and Managed Metadata
Managed metadata property values hidden
Property values are not visible when the property is defined with multivalued enabled and the type was any numeric type.
Affects version: Cloudera Manager 5.14.1, 5.14.0 (Navigator 2.13.1, 2.13.0)
Fixed in version: Cloudera Manager 5.15.0, 5.14.2 (Navigator 2.14.0, 2.13.2)
Cloudera Issue: NAV-5899
Incorrect operation of the Search filter for "Deleted Time"
The Deleted Time search filter does not produce expected results for filtering entities.
Workaround: Specify the delete time range as timestamps in UNIX epoch in milliseconds. For example, to search for entities deleted between January 1, 2017 00:01:00 UTC and January 5, 2017 23:59:00 UTC, enter the following search string in the search box:
+deleteTime:[1514764860000 TO 1515196740000]

Fixed in version: Cloudera Manager 5.14.0 and 5.13.1 (Navigator 2.13.0 and 2.12.1)
Cloudera Issue: NAV-1168
Hive, Hue, Impala, Pig
Hive lineage missing
Because of race conditions within a single JDBC session, Navigator may not show lineage when Hive queries run in parallel within the same session. Hive maintains lineage per session and it clears all lineage information from the session when a query completes. The result is that any query that does not generate lineage will clear the lineage for any other queries that are running in parallel. It can occur for any JDBC clients, such as Hue. Hue uses same session to run user queries and background refresh queries. If you are using JDBC to connect to Hive and you issue concurrent queries using a single JDBC connection, you may encounter this issue.
Affects version: Cloudera Manager 5.12.0 and later (Navigator 2.14.0)
Fixed in version: Cloudera Manager 6.0.0 (Navigator 6.0.0)
Cloudera Issue: CDH-55693
Hive Operations and Cloudera Navigator Support Matrix
The table below lists Hive DDL and DML statements and whether Cloudera Navigator supports the operation with metadata and lineage extraction.
| Hive operations | Cloudera Navigator Support | Comment |
|---|---|---|
| Abort |  |
Operation does not generate data flow. |
| Alter Table/Partition/Column |  |
Known Issue: NAV-5365. ALTER TABLE RENAME TO does not create query entity. ALTER TABLE CHANGE column name does not create query entity. |
| Create Table | |
|
| Create/Drop Macro | |
Operation does not generate data flow. |
| Create/Drop/Alter Index | |
Operation does not generate data flow. |
| Create/Drop/Alter View | |
Operation does not generate data flow. |
| Create/Drop/Alter/Use Database | |
Operation does not generate data flow. |
| Create/Drop/Grant/Revoke Roles and Privileges | |
Operation does not generate data flow. |
| Create/Drop/Reload Function | |
Operation does not generate data flow. |
| DELETE | |
Requires ACID support. Hive ACID not supported. |
| Describe | |
Operation does not generate data flow. |
| Drop/Truncate Table | |
|
| EXPORT | |
Known Issue. . External tables can be exported to HDFS but Cloudera Navigator does not create a query entity for the EXPORT. |
| IMPORT | |
Known Issue. . External tables can be imported from HDFS but Cloudera Navigator does not create a query entity for the IMPORT. |
| INSERT data into Hive Tables from queries | |
|
| INSERT data into the file system from queries | |
|
| INSERT values into tables from SQL | |
|
| LOAD | |
Known Issue. . LOADing a CSV from HDFS into an existing Hive table does not generate lineage. |
| MERGE | |
Requires ACID support. Hive ACID not supported. |
| MSCK REPAIR | |
Tables track their respective partitions. Queries to create or repair partitions using MSCK are not captured as query entities. |
| Show | |
Operation does not generate data flow. |
| UPDATE | |
Requires ACID support. Hive ACID not supported. |
Missing Impala audit events for database-level operations
Impala audit events at the database level are incorrectly recorded, making it seem like they are missing from the Navigator audit data.
Fixed in version: Cloudera Manager 5.14.2, 5.13.2, 5.12.3, and 5.11.3 (Navigator 2.13.2, 2.12.2, 2.11.3, and 2.10.3)
Cloudera Issue: NAV-5648
Impala and Hive audit events fail to be captured when one audit event includes 4-byte characters, such as an emoji
This problem applies when the Navigator Audit Server database is a MySQL database configured to use the "UTF8" character set.
When a query includes an emoji or other Unicode supplementary-plane character that is encoded as four bytes in UTF-8, Navigator Audit Server fails to process the event and any following events from the same service.
Workaround: There are work-arounds for this problem; contact Cloudera Technical Support for details.
Cloudera Issue: NAV-4845
Multi-cluster support for Hive lineage
When there were multiple Hive MetaStore (HMS) sources associated with a single Hive service, the method Navigator used to determine the source was not accurate, resulting in Impala and Spark extractors creating lineage relations that referred to the wrong sources and cross-cluster lineage relations were not generated.
Affects version: Cloudera Manager 5.14.x, 5.13.x, 5.12.x (Navigator 2.13.x, 2.12.x, 2.11.x)
Fixed in version: Cloudera Manager 5.15.0 (Navigator 2.14.0)
Cloudera Issue: NAV-5859
Hive service configuration in auditing component
For Hive services, the auditing component does not support the "Shutdown" option for the "Queue Policy" property.
Severity: Low
Workaround: None.
Cloudera Issue: OPSAPS-11537
Hue service audit log and Unknown IP address
The IP address in a Hue service audit log displays as "unknown".
Severity: Low
Workaround: None.
Cloudera Issue: OPSAPS-11986
Changing auditing configuration for Hive or Hue requires restart
Whenever a change is made to a Hive service's audit configuration, Beeswax must be restarted so that the Hue service audit log can reflect the change.
Severity: Low
Workaround: None.
Cloudera Issue: OPSAPS-12274
Viewing Navigator tags in Hue overloads Metadata Server heap
When viewing Cloudera Navigator tags through Hue, Navigator uses more memory than usual and does not release the memory after logging out of Hue. Eventually, the calls between Hue and Navigator will occupy the majority of the heap space allocated to Navigator Metadata Server.
To work around this problem you may need to restart the Navigator Metadata Server periodically to clear the heap usage.
Affects version: Cloudera Manager 5.11.x and later (Navigator 2.10.x)
Cloudera Issue: NAV-4326
Hue links are missing from Navigator console
The links to Hue from entities in the Navigator console are not generated. Each time the console attempts to show a link, the Navigator Metadata Server log includes an error similar to the following:
10:05:32.539 AM
ERROR
HueUtility
[qtp778450792-57]: Unable to get Hue link from CM.
java.lang.LinkageError: loader constraint violation: when resolving method "com.cloudera.nav.server.NavOptions.getPreferredBaseHueURLForCluster(Ljava/lang/String;)Lcom/google/common/base/Optional;" the class loader (instance of org/eclipse/jetty/webapp/WebAppClassLoader) of the current class, com/cloudera/nav/utils/HueUtility, and the class loader (instance of sun/misc/Launcher$AppClassLoader) for resolved class, com/cloudera/nav/server/NavOptions, have different Class objects for the type ter(Ljava/lang/String;)Lcom/google/common/base/Optional; used in the signature{
Affects version: Cloudera Manager 5.9.0 and later (Navigator 2.8.0)
Fixed in version: Cloudera Manager 5.13.0 and 5.12.1 (Navigator 2.12.0, 2.11.1)
Severity: Low
Workaround: None.
Cloudera Issue: NAV-4756
Lineage not generated for Pig operations on Hive tables using HCatalog loader
When accessing a Hive table using Pig, lineage is generated in Navigator when using physical file loads, such as:
A = LOAD '/user/hive/warehouse/navigator_demo.db/salesdata';
B = LIMIT A 16;
STORE B INTO '/user/hive/warehouse/navigator_demo.db/salesdata_sample_file' using PigStorage (';');
However, when accessing the Hive table using the HCatalog load, lineage for the Pig operation is not generated when browsing the source table lineage. Such as:
A = LOAD 'navigator_demo.salesdata' using org.apache.hive.hcatalog.pig.HCatLoader(); B = LIMIT A 16; STORE B INTO 'navigator_demo.salesdata_sample_hcatalog' using org.apache.hive.hcatalog.pig.HCatStorer();
Cloudera Issue: NAV-3411
HiveServer1 and Hive CLI support deprecated
Cloudera Navigator requires HiveServer2 for complete governance Hive queries. Cloudera Navigator does not capture audit events for queries that are run on HiveServer1/Hive CLI, and lineage is not captured for certain types of operations that are run on HiveServer1.
HiveServer1 and Hive CLI are deprecated in CDH 5. If you use Cloudera Navigator to capture auditing, lineage, and metadata for Hive operations, upgrade to HiveServer2 if you have not done so already.
Cloudera Issue: TSB-185
Navigator Metadata Server
Navigator Metadata Server fails to start with InvalidClassException, local class incompatible
Navigator Metadata Server fails to start (red status in Cloudera Manager) and the Metadata Server log includes the following exception:
2018-09-06 10:38:20,786 WARN jndi [main]: java.io.InvalidClassException: com.mchange.v2.c3p0.WrapperConnectionPoolDataSource; local class incompatible: stream classdesc serialVersionUID = 7806429541739165290, local class serialVersionUID = -7086951306718003710
Even if Navigator Metadata Server starts once, it may encounter this problem at a later time, depending on which JAR file is loaded.
Workaround: See Knowledge Base Article Navigator Metadata Server fails to start with "local class incompatible" error
Affects version: Cloudera Manager version 5.15.1 (Navigator 2.14.1)
Fixed version: Cloudera Manager version 5.15.2 (Navigator 2.14.2)
Cloudera Issue: NAV-6724, TSB-342
Navigator does not mark HDFS entities as deleted when in bulk extraction takes too long to complete
In large HDFS deployments, the fsimage takes a long time to index. When an HDFS checkpoint occurs, it creates a new fsimage. However if the previous fsimage is still in the process of being indexed, Navigator cannot use the incremental changes found in the inotify stream because it refers to the newly created fsimage.
When this happens, Navigator attempts to start indexing the newer fsimage, creating a loop where Navigator can never take advantage of the more efficient change processing through inotify. The immediate fallout of this delay is that no HDFS entities deleted in the cluster are marked as deleted in Navigator.
Fixed in version: Cloudera Manager 5.16.1 (2.15.1)
Cloudera Issue: NAV-6456
ClassCastException in Navigator Metadata Server log
When a Hive view is created, then dropped, and then subsequently recreated as a table with the same name as that of the original view, the Hive extraction process shows this exception in Navigator Metadata Server logs:
java.lang.ClassCastException: com.cloudera.nav.hive.model.HView cannot be cast to com.cloudera.nav.hive.model.HTable
Affects version: Cloudera Manager 5.14.0 and later (Navigator 2.13.0)
Fixed in version: Cloudera Manager 5.16.1, 5.15.2 (2.15.1, 2.14.2)
Cloudera Issue: NAV-5939
Navigator cannot use PostgreSQL 10.x
Navigator Metadata Server will not work with PostgreSQL versions 10.x. This version incompatibility will result in a message similar to this:
2018-08-06 00:00:22,899 WARN com.mchange.v2.async.ThreadPoolAsynchronousRunner [Timer-1]: com.mchange.v2.async.ThreadPoolAsynchronousRunner$DeadlockDetector@6544a122 – APPARENT DEADLOCK!!! Creating emergency threads for unassigned pending tasks!
Products affected: Cloudera Navigator using PostgreSQL as the database for Navigator Metadata Server
Releases affected: Cloudera Navigator as packaged with Cloudera Manager versions 5.15.0 and 5.15.1.
Users affected: Installations using Cloudera Navigator using PostgreSQL as the database for Navigator Audit Server and Navigator Metadata Server
Severity (Low/Medium/High): High
Impact: Navigator Metadata Server does not function with PostgreSQL database version 10 and above.
Immediate action required: Do not upgrade the Navigator Metadata Server database to PostgreSQL 10.x (allow the Navigator Metadata Server database to remain on a previous working version of PostgreSQL ) or upgrade to future Cloudera Manager release where the issue is fixed.
Affects version: Cloudera Manager 5.15.1, 5.15.0 (2.14.1, 2.14.0)
Fixed in version: Cloudera Manager 5.16.1, 5.15.2 (2.15.1, 2.14.2)
Cloudera Issue: DOCS-3686, TSB-334
Navigator Embedded Solr can reach its limit on number of documents it can store
Navigator Metadata Server extracts HDFS entities by performing a one-time bulk extraction and then switching to incremental extraction. In Cloudera Manager releases 5.10.0, 5.10.1 and 5.11.0 (Navigator releases 2.9.0, 2.9.1, and 2.10.0), a problem causes HDFS bulk extraction to be run more than one time, resulting in duplicate relations created for HDFS. Over time, embedded Solr runs out of document IDs that it can assign to new relations and fails with following error:
"Caused by: java.lang.IllegalArgumentException: Too many documents, composite IndexReaders cannot exceed 2147483519"
When this happens, Navigator stops any more extraction of data as no new documents can be added to Solr.
Affects version: Cloudera Manager 5.11.0, 5.10.1, 5.10.0 (2.10.0, 2.9.1, 2.9.0)
Fixed in version: Cloudera Manager 5.12.0, 5.11.1, 5.10.2 (Navigator 2.11.0, 2.10.1, 2.9.2)
Cloudera Issue: NAV-5600
"Lineage Diagram is limited to 3000 entities" Error
Navigator caps the number of lineage parents that could be used at one time, however this cap included relations with second level parents (columns). The Navigator Metadata Server log includes an error such as "Lineage Diagram is limited to 3000 entities".
Work-around: Set nav.capacity.max_nodes_limit=1000 in the Cloudera Manager configuration Navigator Metadata Server Advanced Configuration Snippet (Safety Valve) for cloudera-navigator.properties. Restart Navigator Metadata Server role and check the lineage. The 1000 value assumes that the lineage only touches max of 1000 tables.
Affects version: Cloudera Manager 5.10.0 and later (Navigator 2.9.0)
Fixed in version: Cloudera Manager 5.16.1, 5.15.1, 5.14.4 (Navigator 2.15.1, 2.14.1, 2.13.4)
Cloudera Issue: NAV-6371
Lineage relations are missing for some views with "Endpoint2 must not be null or empty" error
Lineage relations are missing for some views and the Navigator Metadata Server log includes errors with a stack trace that looks something like this:
2017-10-25 19:00:40,780 ERROR com.cloudera.nav.persist.impl.CompositeLinker [CDHExecutor-0-CDHUrlClassLoader@381e3]: Internal error while linking. java.lang.IllegalStateException: EndPoint2 must not be null or empty
Note that the exception is “EndPoint2 must not be null or empty”. If you see errors that don’t exactly match this exception, see one of the following similar errors:
- Log includes the error "EndPoint1 must not be null"
- Log includes the error "EndPoint2 EntityType must not be null unless unlinked"
While Navigator is determining lineage relations, it found a relation that was created with the target entity missing, hence Endpoint2 is null. This situation can occur when a Hive view is altered without changing the columns extracted from the source table, such as when the name or other table metadata on the view is changed. For example, the following operation would produce the error:
alter view customers_sales_sw set tblproperties("region"="southwest");
This problem can occur in Navigator Metadata Server versions 2.9.0, 2.9.1, 2.9.2, 2.10.0, 2.10.1, 2.10.2, 2.11.0, and 2.11.1. These versions correspond to the following Cloudera Manager versions: 5.10.0, 5.10.1, 5.10.2, 5.11.0, 5.11.1, 5.11.2, 5.12.0, and 5.12.1.
Eventually you'll want to upgrade away from an affected Navigator version. If you aren't able to upgrade right away, you can ignore this error with the consequences that your logs are noisy and fill up more quickly. See the Knowledge Base article EndPoint2 must not be null or empty for more information.
Affects version: Cloudera Manager 5.12.1, 5.11.1 (Navigator 2.11.1, 2.10.1)
Fixed in version: Cloudera Manager 5.13.x, 5.12.2, 5.11.2 (Navigator 2.12.x, 2.11.2, 2.10.2)
Cloudera Issue: NAV-5661, KB-713
Log includes the error "EndPoint1 must not be null"
The following error may appear in the Navigator Metadata Server log:
2017-10-17 13:00:23,007 ERROR com.cloudera.nav.hive.extractor.AbstractHiveExtractor [CDHExecutor-0-CDHUrlClassLoader@14784b7b]: Unable to parse hive view query *: EndPoint1 must not be null or empty java.lang.IllegalStateException: EndPoint1 must not be null or empty
This error occurs because the Hive pull extraction for creating a Hive view produces an incorrect lineage relationship for the Hive view. However, Navigator also receives information for the view creation through the push extractor, which correctly produces the lineage relation. You can safely ignore this error. Note that it is distinct from Lineage relations are missing for some views with "Endpoint2 must not be null or empty" error.
Affects version: Cloudera Manager 5.10.x and later (Navigator 2.9.x)
Cloudera Issue: NAV-4224
Log includes the error "EndPoint2 EntityType must not be null unless unlinked"
The following error may appear in the Navigator Metadata Server log:
2017-10-26 15:48:27,440 INFO com.cloudera.nav.hdfs.extractor.HdfsOperationHandler [CDHExecutor-0-CDHUrlClassLoader@3eca0c78]: Unable to process rename for path /hbase/data/default/img/f6572262455416bff42f92fd2b0e75c0/.tmp/1cc1af7b0f784572 b821980f6b4c5adc: can't find source information. 2017-10-26 15:48:27,440 ERROR com.cloudera.nav.hdfs.client.InotifyClient [CDHExecutor-0-CDHUrlClassLoader@3eca0c78]: Error handling event (txid: 2020059072): Renamed /hbase/data/default/img/f6572262455416bff42f92fd2b0e75c0/.tmp/1cc1af7b0f 784572b821980f6b4c5adc to /hbase/data/default/img/f6572262455416bff42f92fd2b0e75c0/D/1cc1af7b0f784572b821980f6b4c5adc at time 1509049550134 java.lang.IllegalStateException: EndPoint2 EntityType must not be null unless unlinked at com.google.common.base.Preconditions.checkState(Preconditions.java:149) at com.cloudera.nav.core.model.Relation.validate(Relation.java:287)
This error occurs when HDFS files are renamed and the new name is affected by an exclusion filter. The only consequence of the problem is noise in the log. Note that it is distinct from Lineage relations are missing for some views with "Endpoint2 must not be null or empty" error.
This problem prevents new lineage information from being added to existing and new Hive entities.
Affects version: Cloudera Manager 5.7.x and later (Navigator 2.6.x)
Fixed in version: Cloudera Manager 5.14.x (Navigator 2.13.x)
Cloudera Issue: NAV-4654
Table-to-HDFS links not established when Navigator supports multiple, high-availability clusters
When Navigator extracts metadata for multiple clusters and when the clusters are configured for high availability operation, Navigator does not correctly link tables to their HDFS backing data. The result is that lineage between Hive tables and their physical data are not created. In addition, some Hive table metadata that is derived from the backing files is not available.
You may see errors in the log such as the following:
2018-02-19 09:01:32,999 ERROR com.cloudera.nav.persist.impl.CompositeLinker [CDHExecutor-0-CDHUrlClassLoader@01010d7e]: Internal error while linking.java.lang.IllegalArgumentException: expected one element but was: <com.cloudera.nav.core.model.Source@b22e68ba, com.cloudera.nav.core.model.Source@5b1bac2c>
Affects version: Cloudera Manager 5.13.x, 5.12.x (Navigator 2.12.x, 2.11.x)
Fixed in version: Cloudera Manager 5.14.0 (Navigator 2.13.0)
Cloudera Issue: NAV-5749
Purging Deleted Properties shows "Bad Request" error when viewing Hive entity details
After upgrading to Navigator 2.11.0 (Cloudera Manager 5.12.0) and later versions (to Navigator 2.13.0), removing deleted managed metadata properties with the "Purge deleted Properties" command causes a mismatch between the Solr schema and the data stored for entities. ().
The result is that the Navigator console shows the error "Bad Request" when displaying details for Hive entities such as databases, tables, or fields.
When this problem occurs, the Navigator Metadata Server log will include a message such as the following:
[CDHExecutor-0-CDHUrlClassLoader@62d310e8]: Internal error while linking. java.lang.IllegalArgumentException: java.lang.ClassCastException@2f145bbc
To avoid this problem, do not purge deleted properties; allow these properties to stay in the list of properties.
Affects version: Cloudera Manager 5.12.0 and later (Navigator 2.11.0)
Fixed in version: Cloudera Manager 5.15.0, 5.14.2, 5.13.3 (Navigator 2.14.0, 2.13.2, 2.12.3)
Cloudera Issue: NAV-5982
Metadata Server log file and spurious error messages
Error: [main]: PWC6351: In TLD scanning, the supplied resource file:/usr/share/java/oracle-connector-java.jar does not exist.
Affects version: Cloudera Manager 5.9.x, 5.8.1 (Navigator 2.8.x, 2.7.1)
Fixed in version: Cloudera Manager 5.10.0 (2.9.0)
Cloudera Issue: NAV-698
Purge
Fail to Purge Hive and Impala Select Operations
In some cases, purge code makes large query requests to solr. In those cases, it can fail with the following error followed by a stack trace:
2018-09-22 23:39:55,736 ERROR com.cloudera.nav.maintenance.purge.hiveandimpala.PurgeHiveOrImpalaSelectOperations [scheduler_Worker-2]: Failed to purge operations for DELETE_HIVE_AND_IMPALA_SELECT_OPERATIONS with error
org.apache.solr.client.solrj.impl.HttpSolrServer$RemoteSolrException: Expected mime type application/octet-stream but got application/xml.
Work-around: To work around this problem, lower the batch size for Navigator commits to its Solr collection by changing the value of nav.solr.commit_batch_size to be lower.
Affects version: Cloudera Manager 5.12.0 (Navigator 2.11) and later
Cloudera Issue: NAV-6789
Purge operation leaves Kite errors in log
Navigator Metadata Server attempts to handle Kite datasets even though Kite datasets are no longer supported. This problem may affect operations such as metadata purge. If you encounter Kite dataset errors such as the following, you need to manually disable Kite dataset extraction.
2018-09-23 16:10:43,678 ERROR com.cloudera.nav.hdfs.datasets.KiteDatasetReader [hdfs-reader-1]: Dataset expected but not found at /staging/example/.temp/job_1537417909723_0201/mr/job_1537417909723_0201org.kitesdk.data.DatasetNotFoundException: Descriptor location does not exist
nav.extractor.hdfs.datasets.enabled=false
Affects version: Cloudera Manager 5.14.0 (Navigator 2.13) and later
Cloudera Issue: NAV-6965
The flag for disabling purge is ignored in the UI
The page may show scheduled purge operations even if the nav.purge.enabled property is set to false. The displayed purge operations will not run.
Affects version: Cloudera Manager 5.14.0, 5.14.1 (Navigator 2.13.1, 2.13.0)
Fixed in version: Cloudera Manager 5.14.2 (Navigator 2.13.2)
Cloudera Issue: NAV-5966
Policy specifications and cluster names affect purge
Policies cannot use cluster names in queries. Cluster name is a derived attribute and cannot be used as-is.
Workaround: When setting move actions for Cloudera Navigator, if there is only one cluster known to the Navigator instance, remove the clusterName clause.
curl '<nav-url>/api/v9/entities/?query=type%3Asource&limit=100&offset=0'Use the identity of the matching HDFS service for this cluster as the sourceId.
Cloudera Issue: NAV-3288
Spark
Spark Lineage Limitations and Requirements
Spark lineage diagrams are supported in the following releases:
- Spark 2.3 as of Cloudera Manager 5.14.0 (Navigator 2.13.0)
- Spark 1.6 as of Cloudera Manager 5.11.0 (Navigator 2.10.0)
- Lineage is produced only for data that is read/written and processed using the Dataframe and SparkSQL APIs. Lineage is not available for data that is read/written or processed using Spark's RDD APIs.
- Lineage information is not produced for calls to aggregation functions such as groupBy().
- The default lineage directory for Spark on Yarn is /var/log/spark/lineage. No process or user should write files to this directory—doing so can cause agent failures. In addition, changing the Spark on Yarn lineage directory has no effect: the default remains /var/log/spark/lineage.
Cloudera Issue: OPSAPS-39589
Navigator doesn't recognize local files in Spark jobs
Spark jobs can use files on the local filesystem as job inputs or outputs. Navigator, however, only supports HFDS, Hive, and S3 assets as job inputs or outputs. When Navigator extracts metadata from Spark and encounters a local source type, the metadata is discarded and the following error appears in the Navigator Metadata Server log:
2018-10-11 12:14:26,192 WARN com.cloudera.nav.api.ApiExceptionMapper [qtp1574898980-23815]: Unexpected exception.
java.lang.RuntimeException: Source LOCAL isn't supported for Spark Lineage
Affected Versions: Cloudera Manager 5.11 and later (Navigator 2.10)
Fixed in version: Cloudera Manager 5.16.2 (Navigator 2.15.2) Note that the fix does not provide support for extracting metadata for local files for Spark jobs; it prevents the error.
Cloudera Issue: NAV-6811
Too many open files on the Navigator Metadata Server Spark agent
You've encountered this problem if lineage isn't being created for Spark operations and the Cloudera Manager Agent logs include the error:
OSError: [Errno 24] Too many open files: '/var/log/spark/lineage'
Work-around:
To remove the bottleneck of files and continue processing:
- From a terminal, login to the host with the issue.
- Stop the Cloudera Manager agent.
If the file descriptor limit is hit, the agent is likely to fail to start anyway.
- Navigate to the Spark lineage directory, by default /var/log/spark/lineage.
The directory will contain thousands of files.
- Move enough files out of this directory to bring count of files within the file descriptor limit.
- Start the Cloudera Manager Agent.
The agent will start processing files within few minutes. After successfully processing, the agent will delete the processed files. At the end there will fewer than 10 files present in the directory.
- Move the files that were moved out back in the directory.
The next set of files will be processed.
Affects version: Cloudera Manager 5.12.1 and later (Navigator 2.11.1)
Fixed in version: Cloudera Manager 5.16.1, 5.15.1, 5.14.4 (Navigator 2.15.1, 2.14.1, 2.13.4)
Cloudera Issue: NAV-6396
Extracting Spark operation produced error message "Solr Manager can be used by only one thread"
When extracting Spark operations, the following error appears in the Navigator Metadata Server log:
2018-02-20 09:37:27,869 ERROR com.cloudera.nav.pushextractor.spark.SparkPushExtractor [qtp937744315-126]: com.cloudera.nav.pushextractor.spark.SparkPushExtractor Error extracting Spark operation.java.lang.IllegalStateException: Solr Manager can be used by only one thread.
This error does not have consequences for Navigator handling Spark operations.
Affects version: Cloudera Manager 5.14.1, 5.14.0, 5.13.1, 5.13.0, 5.12.x (Navigator 2.13.1, 2.13.0, 2.12.1, 2.12.0, 2.11.x)
Fixed in version: Cloudera Manager 5.15.0, 5.14.2. 5.13.3 (Navigator 2.14.0, 2.13.2, 2.12.3)
Cloudera Issue: NAV-4991
Spark lineage not shown in Navigator for HDFS HA
When HDFS is configured for high availability, Spark lineage doesn't show in Navigator. In these cases, the log includes index out of bounds exceptions such as the following:
com.cloudera.nav.pushextractor.spark.SparkPushExtractor Error extracting Spark operation. java.lang.ArrayIndexOutOfBoundsException
Affects version: Cloudera Manager 5.13.0, 5.12.1, 5.12.0, 5.11.x, 5.10.x, 5.9.x (Navigator 2.12.0, 2.11.1, 2.11.0, 2.10.x, 2.9.x, 2.8.x)
Fixed in version: Cloudera Manager 5.14.0, 5.13.1, 5.12.2 (Navigator 2.13.0, 2.12.1, 2.11.2)
Cloudera Issue: NAV-4874
Spark extractor enabled using safety valve deprecated
The Spark extractor included prior to CDH 5.11 and enabled by setting the safety valve, nav.spark.extraction.enable=true is being deprecated, and could be removed completely in a future release. If you are upgrading to CDH 5.11 from a deployment that had configured this safety valve, be sure to remove the setting when you upgrade.
Upgrade Issues and Limitations
Issues and limitations matrix by release
Before upgrading Cloudera Navigator, review these version-specific release notes:
| Upgrade | Limitations, requirements, preliminary tasks | |
|---|---|---|
| From... | To... | |
| 2.14 (and lower) | 2.15.1 (and higher) | The default filters set for auditing HDFS changed in Cloudera Manager 5.16.1 (Navigator 2.15.1). If you've updated your HDFS audit filters from previous defaults, the new filters are not applied. Whether or not the filters are changed in your upgrade process, we recommend that you review your HDFS audit filters to ensure you are collecting the audit events that add value in your environment. See Improvements to Audit Filters for more information. |
| 2.10 (and lower) | 2.11.0, 2.11.1, 2.12.0 |
When using Navigator in multi-cluster environments, avoid upgrading to Cloudera Manager deployments of version 5.12.0, 5.12.1, or 5.13.0 due to a known problem where Navigator does not recognize more than one cluster. Instead, upgrade to Cloudera Manager release 5.12.2, 5.13.1, or 5.14.0 (Navigator 2.11.2, 2.12.1, or 2.13.0). See Cloudera Navigator is not supported in installations in multi-cluster environments for Cloudera Manager versions 5.12.0, 5.12.1, and 5.13.0 for more details. This problem does not affect single cluster deployments or Altus clusters. |
| 2.8 (and lower) | 2.9.0, 2.9.1, 2.10.0 | Avoid upgrading to Cloudera Manager releases 5.10.0, 5.10.1 and 5.11.0 (Navigator releases 2.9.0, 2.9.1, and 2.10.0) due to the known problem causing the storage directory to fill beyond its capacity. The workaround is to upgrade to Cloudera Manager release 5.10.2, 5.11.1, or 5.12.x (Navigator 2.9.2, 2.10.1, 2.11.x) or later, where this issue is fixed. See Navigator Embedded Solr can reach its limit on number of documents it can store if you are already running one of these releases. |
| 2.10 | 2.10.1 | Upgrading Cloudera Manager 5.11.0 (Cloudera Navigator 2.10) to Cloudera Manager 5.11.1 (Cloudera Navigator 2.10.1) results in failures by Navigator Audit Server to publish to Kafka. See Publishing to Kafka fails after upgrade for details and a workaround. |
| 2.9 (and higher) | 2.10 (and higher) |
As described later in this table, upgrading across Cloudera Manager 5.10 (Cloudera Navigator 2.9) involved a significant metadata change and therefore the upgrade was very slow. Upgrades between Cloudera Manager 5.10 and later releases do not have a metadata change and the Navigator upgrade is quick. |
| 2.8 (and lower) | 2.9 (and higher) | Upgrading to Cloudera Navigator 2.9 and higher (Cloudera Manager 5.10 and higher) can take a significant amount of time, depending on the size of the datadir. Before starting to upgrade to Cloudera Manager 5.10 (which automatically starts the upgrade to Cloudera Navigator 2.9), see Upgrading Cloudera Navigator Can be Extremely Slow. Briefly, in this release Solr indexing has been optimized to improve search speed. When the upgrade process completes and Cloudera Navigator services re-start, the Solr indexing upgrade automatically begins. No other actions can be performed until Solr indexing completes (progress message display during this process). |
| 2.6 (and lower) | Any | The Cloudera Navigator Metadata Server requires an upgrade of data in the storage directory. See Upgrading Cloudera Navigator for details. |
| 2.4.0, 2.4.1 | 2.4.2 | After upgrading, requires manual modification to the HDFS extractor state file to change status of UNDELETE taskTypes from SUCCEEDED to FAILED. This manual process is required only for these specific releases listed. See Issues Fixed in Cloudera Navigator 2.4.2 for details. |
| Any | 2.4 – 2.6 | Cloudera Navigator 2.4 – 2.6 do not support JDK 1.6, so upgrade any instances of JDK 1.6 to JDK 1.7 or 1.8 before upgrading to these releases. See Step 2: Install Java Development Kit for details. |
| 2.1 | 2.2 | Cloudera Navigator 2.1 used the beta version of the Navigator Metadata Server policy engine. Policies created using that version are not retained during the upgrade. |
| 2.0 (and lower) | 2.1 (and higher) | The upgrade wizard for this upgrade path adds the Navigator Metadata Server to the Cloudera Manager cluster. The Navigator Metadata Server is new, and is not the same as the existing Navigator Audit Server database. |
| 1.2 | 2.0 | Cloudera Navigator 1.2 and Cloudera Navigator 2.0 have reached EOL (end of life) status and are no longer supported. There is no wizard for this upgrade path. Cloudera Navigator 2.0 required a clean install. The Navigator 1.2 Navigator Metadata Server was a beta release included with Cloudera Manager 5.0. The 1.2 version of the Navigator Metadata Server role must be removed before the cluster can be upgraded to Cloudera Navigator 2.0 (the roles are not compatible). |
Upgrading Cloudera Navigator Can be Extremely Slow
Upgrading a cluster running Cloudera Navigator to Cloudera Manager 5.10 (or higher) can be extremely slow due to an internal change made to the Solr schema in Cloudera Navigator 2.9. A Solr instance is embedded in Cloudera Navigator and supports its Search capabilities. The Solr schema used by Cloudera Navigator has been modified in the 2.9 release to use datatype long rather than string for an internal id field. This change makes Cloudera Navigator far more robust and scalable over the long term.
| Metadata and lineage usage | Description |
|---|---|
| None | Deployments that use Cloudera Navigator audit capability only—without metadata or lineage—do not have the issue. Backup the Navigator Metadata Server datadir and then delete it before upgrading. |
| datadir < 60 GB | Deployments with relatively small Navigator Metadata Server data directories may take 1 to 2 days for the upgrade process to complete. See the Workaround for steps to take before upgrading to Cloudera Manager 5.10 to possibly reduce the upgrade time. |
| datadir > 60 GB | Deployments with relatively large Navigator Metadata Server data directories may take several days for the upgrade process to complete. See the Workaround for steps to take before upgrading to Cloudera Manager 5.10 to possibly reduce the upgrade time. |
- Check the Navigator Metadata Server storage directory size. The path is /var/lib/cloudera-scm-navigator (default) unless configured otherwise. If you
need to check the setting:
- Log in to Cloudera Manager Admin Console.
- Select .
- Click Configuration and then click the Navigator Metadata Server Scope filter:

- Confirm that the cluster uses the default configuration, or make a note of the location specified and the node name.
- Check the size of the actual directory contents. The following example shows a freshly installed system and so it is virtually empty.
[root@node-1 ~]# cd /var/lib/cloudera-scm-navigator [root@node-1 cloudera-scm-navigator]# ls -l total 12 drwxr-x--- 2 cloudera-scm cloudera-scm 113 Jul 12 06:56 diagnosticData drwxr-x--- 2 cloudera-scm cloudera-scm 4096 Jul 12 09:16 extractorState -rw-r----- 1 cloudera-scm cloudera-scm 36 Jul 12 05:54 instance.uuid drwxr-x--- 4 cloudera-scm cloudera-scm 60 Jul 12 04:18 solr drwxr-x--- 7 cloudera-scm cloudera-scm 4096 Jul 12 07:26 temp [root@node-1 cloudera-scm-navigator]# cd solr [root@node-1 solr]# ls -l total 4 drwxr-x--- 4 cloudera-scm cloudera-scm 28 Jul 12 05:56 nav_elements drwxr-x--- 4 cloudera-scm cloudera-scm 28 Jul 12 05:56 nav_relations -rw-r----- 1 cloudera-scm cloudera-scm 450 Jul 6 16:13 solr.xml [root@node-1 solr]#
- Back up the contents of the directory. Use Cloudera Manager BDR or your preferred method.
- Schedule a purge process as described in Scheduling the Purge Process.
Set options to purge metadata for deleted HDFS entities and any operations.
- Check the storage directory size again. If needed, re-run the purge with a shorter time span to retain metadata. If the storage directory consumption cannot be reduced below 60GB, do not start the Cloudera Manager upgrade. Instead, contact Cloudera support to help you with this upgrade.
Cloudera Issue: NAV-5046