HBase Replication
If your data is already in an HBase cluster, replication is useful for getting the data into additional HBase clusters. In HBase, cluster replication refers to keeping one cluster state synchronized with that of another cluster, using the write-ahead log (WAL) of the source cluster to propagate the changes. Replication is enabled at column family granularity. Before enabling replication for a column family, create the table and all column families to be replicated, on the destination cluster.
Cluster replication uses an active-push methodology. An HBase cluster can be a source (also called active, meaning that it writes new data), a destination (also called passive, meaning that it receives data using replication), or can fulfill both roles at once. Replication is asynchronous, and the goal of replication is consistency.
When data is replicated from one cluster to another, the original source of the data is tracked with a cluster ID, which is part of the metadata. In CDH 5, all clusters that have already consumed the data are also tracked. This prevents replication loops.
Continue reading:
- Common Replication Topologies
- Points to Note about Replication
- Requirements
- Deploying HBase Replication
- Disabling Replication at the Peer Level
- Stopping Replication in an Emergency
- Creating the Empty Table On the Destination Cluster
- Initiating Replication When Data Already Exists
- Understanding How WAL Rolling Affects Replication
- Configuring Secure HBase Replication
- Restoring Data From A Replica
- Replication Caveats
Common Replication Topologies
- A central source cluster might propagate changes to multiple destination clusters, for failover or due to geographic distribution.
- A source cluster might push changes to a destination cluster, which might also push its own changes back to the original cluster.
- Many different low-latency clusters might push changes to one centralized cluster for backup or resource-intensive data-analytics jobs. The processed data might then be replicated back to the low-latency clusters.
- Multiple levels of replication can be chained together to suit your needs. The following diagram shows a hypothetical scenario. Use the arrows to follow the data paths.
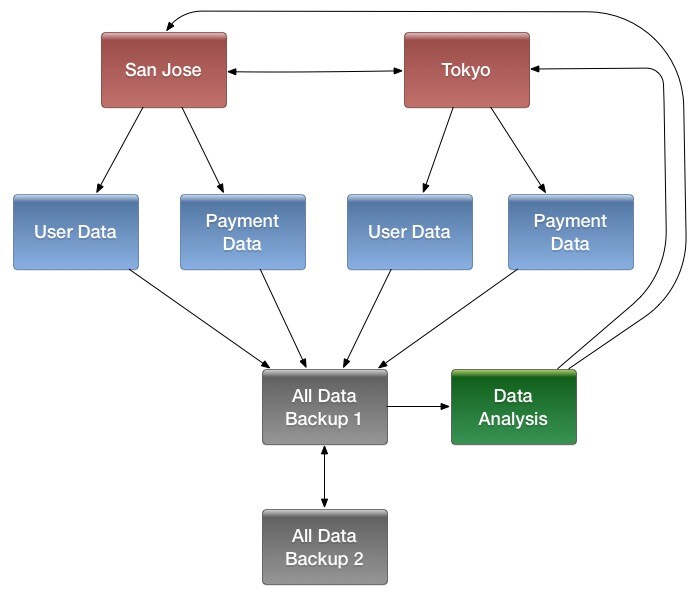
At the top of the diagram, the San Jose and Tokyo clusters, shown in red, replicate changes to each other, and each also replicates changes to a User Data and a Payment Data cluster.
Each cluster in the second row, shown in blue, replicates its changes to the All Data Backup 1 cluster, shown in grey. The All Data Backup 1 cluster replicates changes to the All Data Backup 2 cluster (also shown in grey), as well as the Data Analysis cluster (shown in green). All Data Backup 2 also propagates any of its own changes back to All Data Backup 1.
The Data Analysis cluster runs MapReduce jobs on its data, and then pushes the processed data back to the San Jose and Tokyo clusters.
Points to Note about Replication
- The timestamps of the replicated HLog entries are kept intact. In case of a collision (two entries identical as to row key, column family, column qualifier, and timestamp) only the entry arriving later write will be read.
- Increment Column Values (ICVs) are treated as simple puts when they are replicated. In the case where each side of replication is active (new data originates from both sources, which then replicate each other), this may be undesirable, creating identical counters that overwrite one another. (See https://issues.apache.org/jira/browse/HBase-2804.)
- Make sure the source and destination clusters are time-synchronized with each other. Cloudera recommends you use Network Time Protocol (NTP).
-
Some changes are not replicated and must be propagated through other means, such as Snapshots or CopyTable.
-
Data that existed in the active cluster before replication was enabled.
-
Operations that bypass the WAL, such as when using BulkLoad or API calls such as writeToWal(false).
-
Table schema modifications.
-
Requirements
Before configuring replication, make sure your environment meets the following requirements:
- You must manage ZooKeeper yourself. It must not be managed by HBase, and must be available throughout the deployment.
- Each host in both clusters must be able to reach every other host, including those in the ZooKeeper cluster.
- Both clusters must be running the same major version of CDH; for example CDH 4 or CDH 5.
- Every table that contains families that are scoped for replication must exist on each cluster and have exactly the same name. If your tables do not yet exist on the destination cluster, see Creating the Empty Table On the Destination Cluster.
- HBase version 0.92 or greater is required for complex replication topologies, such as active-active.
Deploying HBase Replication
- Configure and start the source and destination clusters.
- Create tables with the same names and column families on both the source and destination clusters, so that the destination cluster knows where to store data it receives. All hosts in the source and destination clusters should be reachable to each other. See Creating the Empty Table On the Destination Cluster.
- On the source cluster, enable replication in Cloudera Manager, or by setting hbase.replication to true in hbase-site.xml.
- Obtain Kerberos credentials as the HBase principal. Substitute your fully.qualified.domain.name and realm in the following command:
$ kinit -k -t /etc/hbase/conf/hbase.keytab hbase/fully.qualified.domain.name@YOUR-REALM.COM
- On the source cluster, in HBase Shell, add the destination cluster as a peer, using the add_peer command. The syntax is as follows:
add_peer 'ID', 'CLUSTER_KEY'
The ID must be a short integer. To compose the CLUSTER_KEY, use the following template:hbase.zookeeper.quorum:hbase.zookeeper.property.clientPort:zookeeper.znode.parent
If both clusters use the same ZooKeeper cluster, you must use a different zookeeper.znode.parent, because they cannot write in the same folder.
- On the source cluster, configure each column family to be replicated by setting its REPLICATION_SCOPE to 1, using commands such as the following in HBase
Shell.
hbase> disable 'example_table' hbase> alter 'example_table', {NAME => 'example_family', REPLICATION_SCOPE => '1'} hbase> enable 'example_table' - Verify that replication is occurring by examining the logs on the source cluster for messages such as the following.
Considering 1 rs, with ratio 0.1 Getting 1 rs from peer cluster # 0 Choosing peer 10.10.1.49:62020
- To verify the validity of replicated data, use the included VerifyReplication MapReduce job on the source cluster,
providing it with the ID of the replication peer and table name to verify. Other options are available, such as a time range or specific families to verify.
The command has the following form:
hbase org.apache.hadoop.hbase.mapreduce.replication.VerifyReplication [--starttime=timestamp1] [--stoptime=timestamp] [--families=comma separated list of families] <peerId> <tablename>
The VerifyReplication command prints GOODROWS and BADROWS counters to indicate rows that did and did not replicate correctly.
Guidelines for Replication across Three or More Clusters
- On the source cluster:
create 't1',{NAME=>'f1', REPLICATION_SCOPE=>1} - On the destination cluster:
create 't1',{NAME=>'f1', KEEP_DELETED_CELLS=>'true'}
Disabling Replication at the Peer Level
To re-enable the peer, use the command enable_peer(<"peerID">). Replication resumes where it was stopped.
Examples:
- To disable peer 1:
disable_peer("1")
- To re-enable peer 1:
enable_peer("1")Stopping Replication in an Emergency
If replication is causing serious problems, you can stop it while the clusters are running.
Open the shell on the source cluster and use the stop_replication command. For example:
hbase(main):001:0> stop_replication
Already queued edits will be replicated after you use the disable_table_replication command, but new entries will not. See Understanding How WAL Rolling Affects Replication.
To start replication again, use the enable_peer command.
Creating the Empty Table On the Destination Cluster
If the table to be replicated does not yet exist on the destination cluster, you must create it. The easiest way to do this is to extract the schema using HBase Shell.
- On the source cluster, describe the table using HBase Shell. The output below has been reformatted for readability.
hbase> describe acme_users Table acme_users is ENABLED acme_users COLUMN FAMILIES DESCRIPTION {NAME => 'user', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'NONE', REPLICATION_SCOPE => '0', VERSIONS => '3', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'false'} - Copy the output and make the following changes:
- For the TTL, change FOREVER to org.apache.hadoop.hbase.HConstants::FOREVER.
- Add the word CREATE before the table name.
- Remove the line COLUMN FAMILIES DESCRIPTION and everything above the table name.
CREATE cme_users {NAME => 'user', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'NONE', REPLICATION_SCOPE => '0', VERSIONS => '3', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => 'org.apache.hadoop.hbase.HConstants::FOREVER', KEEP_DELETED_CELLS => 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'false'} - On the destination cluster, paste the command from the previous step into HBase Shell to create the table.
Initiating Replication When Data Already Exists
You may need to start replication from some point in the past. For example, suppose you have a primary HBase cluster in one location and are setting up a disaster-recovery (DR) cluster in another. To initialize the DR cluster, you need to copy over the existing data from the primary to the DR cluster, so that when you need to switch to the DR cluster you have a full copy of the data generated by the primary cluster. Once that is done, replication of new data can proceed as normal.
One way to do this is to take advantage of the write accumulation that happens when a replication peer is disabled.
- Start replication.
- Add the destination cluster as a peer and immediately disable it using disable_peer.
- On the source cluster, take a snapshot of the table and export it. The snapshot command flushes the table from memory for you.
- On the destination cluster, import and restore the snapshot.
- Run enable_peer to re-enable the destination cluster.
Replicating Pre-existing Data in an Active-Active Deployment
In the case of active-active replication, run the copyTable job before starting the replication. (If you start the job after enabling replication, the second cluster will re-send the data to the first cluster, because copyTable does not edit the clusterId in the mutation objects. The following is one way to accomplish this:
- Run the copyTable job and note the start timestamp of the job.
- Start replication.
- Run the copyTable job again with a start time equal to the start time you noted in step 1.
This results in some data being pushed back and forth between the two clusters; but it minimizes the amount of data.
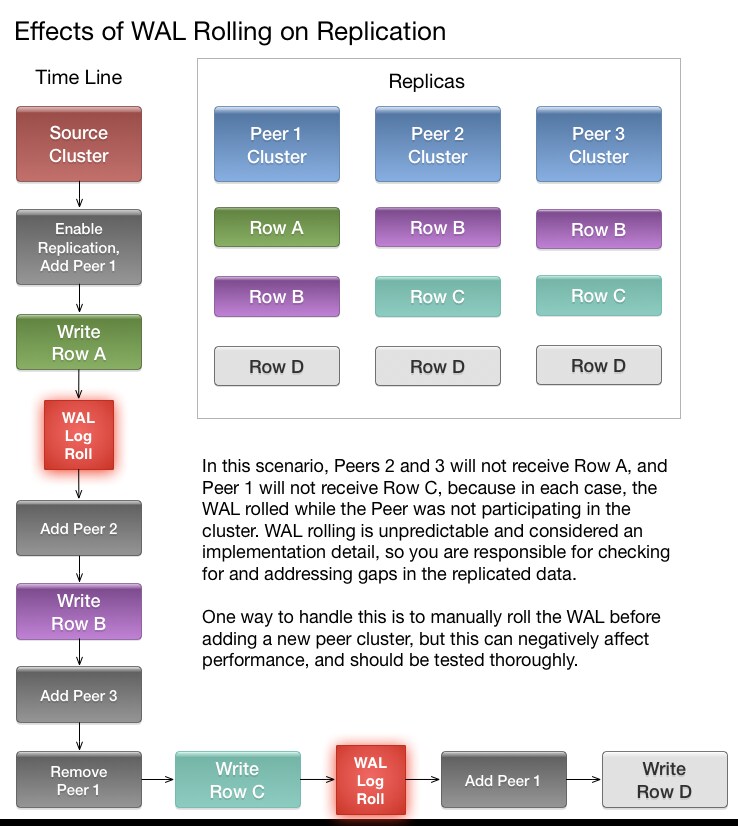
Understanding How WAL Rolling Affects Replication
When you add a new peer cluster, it only receives new writes from the source cluster since the last time the WAL was rolled.
The following diagram shows the consequences of adding and removing peer clusters with unpredictable WAL rolling occurring. Follow the time line and notice which peer clusters receive
which writes. Writes that occurred before the WAL is rolled are not retroactively replicated to new peers that were not participating in the cluster before the WAL was
rolled.
Configuring Secure HBase Replication
If you want to make HBase Replication secure, follow the instructions under HBase Authentication.
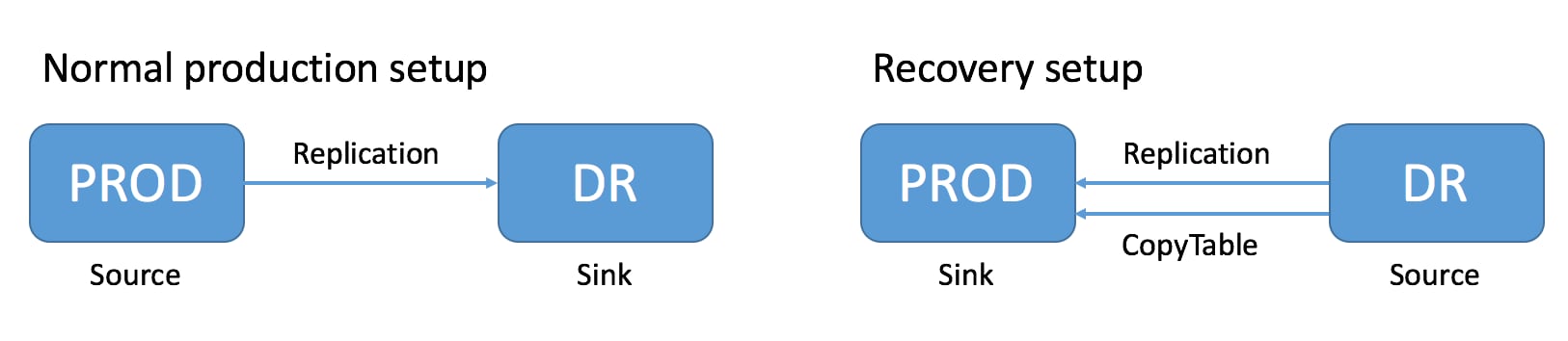
Restoring Data From A Replica
One of the main reasons for replications is to be able to restore data, whether during disaster recovery or for other reasons. During restoration, the source and sink roles are reversed. The source is the replica cluster, and the sink is the cluster that needs restoration. This can be confusing, especially if you are in the middle of a disaster recovery scenario. The following image illustrates the role reversal between normal production and disaster recovery.
- Change the value of the column family property REPLICATION_SCOPE on the sink to 0 for each column to be restored, so that its data will not be replicated during the restore operation.
- Change the value of the column family property REPLICATION_SCOPE on the source to 1 for each column to be restored, so that its data will be replicated.
- Use the CopyTable or distcp commands to import the data from the backup to the sink cluster, as outlined in Initiating Replication When Data Already Exists.
- Add the sink as a replication peer to the source, using the add_peer command as discussed in Deploying HBase Replication. If you used distcp in the previous step, restart or rolling restart both clusters, so that the RegionServers will pick up the new files. If you used CopyTable, you do not need to restart the clusters. New data will be replicated as it is written.
- When restoration is complete, change the REPLICATION_SCOPE values back to their values before initiating the restoration.
Replication Caveats
- Two variables govern replication: hbase.replication as described above under Deploying HBase Replication, and a replication znode. Stopping replication (using stop_replication as above) sets the
znode to false. Two problems can result:
- If you add a new RegionServer to the active cluster while replication is stopped, its current log will not be added to the replication queue, because the replication znode is still set to false. If you restart replication at this point (using enable_peer), entries in the log will not be replicated.
- Similarly, if a log rolls on an existing RegionServer on the active cluster while replication is stopped, the new log will not be replicated, because the replication znode was set to false when the new log was created.
- In the case of a long-running, write-intensive workload, the destination cluster may become unresponsive if its meta-handlers are blocked while performing the replication. CDH 5
provides three properties to deal with this problem:
- hbase.regionserver.replication.handler.count - the number of replication handlers in the destination cluster (default is 3). Replication is now handled by separate handlers in the destination cluster to avoid the above-mentioned sluggishness. Increase it to a high value if the ratio of active to passive RegionServers is high.
- replication.sink.client.retries.number - the number of times the HBase replication client at the sink cluster should retry writing the WAL entries (default is 1).
- replication.sink.client.ops.timeout - the timeout for the HBase replication client at the sink cluster (default is 20 seconds).
- For namespaces, tables, column families, or cells with associated ACLs, the ACLs themselves are not replicated. The ACLs need to be re-created manually on the target table. This behavior opens up the possibility for the ACLs could be different in the source and destination cluster.