Data Durability
This page contains the following topics:
Overview
Data durability describes how resilient data is to loss. When data is stored in HDFS, CDH provides two options for data durability. You can use replication, which HDFS was originally built on, or Erasure Coding (EC). The comparisons between EC and replication on this page use a replication factor of 3 (three copies of data are maintained) since that is the default.
- Replication
- HDFS creates two copies of data, resulting in three total instances of data. These copies are stored on separate DataNodes to guard against data loss when a node is unreachable. When
the data stored on a node is lost or inaccessible, it is replicated from one of the other nodes to a new node so that there are always multiple copies. The number of replications is configurable, but
the default is three. Cloudera recommends keeping the replication factor to at least three when you have three or more DataNodes. A lower replication factor leads to a situation where the data is
more vulnerable to DataNode failures since there are fewer copies of data spread out across fewer DataNodes..
When data is written to an HDFS cluster that uses replication, additional copies of the data are automatically created. No additional steps are required.
Replication supports all data processing engines that CDH supports.
- Erasure Coding (EC)
- EC is an alternative to replication. When an HDFS cluster uses EC, no additional direct copies of the data are generated. Instead, data is striped into blocks and encoded to generate
parity blocks. If there are any missing or corrupt blocks, HDFS uses the remaining data and parity blocks to reconstruct the missing pieces in the background. This process provides a similar level of
data durability to 3x replication but at a lower storage cost.
Additionally, EC is applied when data is written. This means that to use EC, you must first create a directory and configure it for EC. Then, you can either replicate existing data or write new data into this directory.
EC supports the following data processing engines:- Hive
- MapReduce
- Spark
With both data durability schemes, replication and EC, recovery happens in the background and requires no direct input from a user.
Replication or EC can be the only data durability scheme on a cluster. Alternatively, you can create a hybrid deployment where replication and EC are both used. This decision should be based on the temperature of the data (how often the data is accessed) stored in HDFS. Hot data, data that is accessed frequently, should use replication. Cold data, data that is accessed less frequently, can take advantage of EC's storage savings. See Comparing Replication and Erasure Coding for more information.
For information about how to enable EC, see Enabling Erasure Coding.
Understanding Erasure Coding Policies
The EC policy determines how data is encoded and decoded. An EC policy is made up of the following parts: codec-number of data blocks-number of parity blocks-cell size.
- Codec: The erasure codec that the policy uses. CDH currently supports Reed-Solomon (RS).
- Number of Data Blocks: The number of data blocks per stripe. The higher this number, the more nodes that need to be read when accessing data because HDFS attempts to distribute the blocks evenly across DataNodes.
- Number of Parity Blocks: The number of parity blocks per stripe. Even if a file does not use up all the data blocks available to it, the number of parity blocks will always be the total number listed in the policy.
- Cell Size: The size of one basic unit of striped data.
For example, a RS-6-3-1024k policy has the following attributes:
- Codec: Reed-Solomon
- Number of Data Blocks: 6
- Number of Parity Blocks: 3
- Cell Size: 1024k
The sum of the number of data blocks and parity blocks is the data-stripe width. When you make hardware plans for your cluster, the number of racks should at least equal the stripe width in order for the data to be resistant to rack failures.
The following image compares the data durability and storage efficiency of different RS codecs and replication:
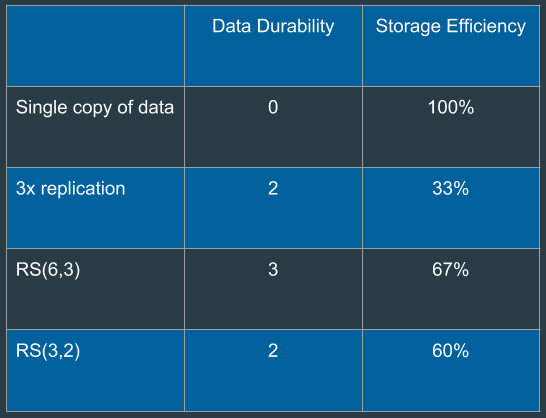
Storage efficiency is the ratio of data blocks to total blocks as represented by the following formula: data blocks / (data blocks + parity blocks)
Comparing Replication and Erasure Coding
Consider the following factors when you examine which data protection scheme to use:
- Data Temperature
- Data temperature refers to how often data is accessed. EC works best with cold data that is accessed and modified infrequently. There is no data locality, and all reads are remote. Replication is more suitable for hot data, data that is accessed and modified frequently because data locality is a part of replication.
- I/O Cost
- EC has higher I/O costs than replication for the following reasons:
- EC spreads data across nodes and racks, which means reading and writing data comes at a higher network cost.
- A parity block is generated when data is written, thus impacting write speed. This can be slower than writing to a file when the replication factor is one but is faster than writing two or more replicas.
- If data is missing or corrupt, a DataNode reads the remaining data and parity blocks in order to reconstruct the data. This process requires CPU and network resources.
Cloudera recommends at least a 10 GB network connection if you want to use EC.
- Storage Cost
- EC has a lower storage overhead than replication because multiple copies of data are not maintained. Instead, a number of parity blocks are generated based on the EC policy. For the same amount of data, EC will store fewer blocks than 3x replication in most cases. For example with a Reed-Solomon (6,3), HDFS stores three parity blocks for each set of 6 data blocks. With replication, HDFS stores 12 replica blocks for every six data blocks, the original block and three replicas. The case where 3x replication requires fewer blocks is when data is stored in small files.
- File Size
- Erasure coding works best with larger files. The total number of blocks is determined by data blocks + parity blocks, which is the data-stripe width discussed earlier.
128 MB is the default block size. With RS (6,3), each block group can hold up to (128 MB * 6) = 768 MB of data. Inside each block group, there will be 9 total blocks, 6 data blocks, each holding up to 128 MB, and 3 parity blocks. This is why EC works best with larger files. For a chunk of data less than the block size, replication writes one data block to three DataNodes; EC, on the other hand, still needs to stripe the data to data blocks and calculate parity blocks. This leads to a situation where erasure coded files will generate more blocks than replication because of the parity blocks required.
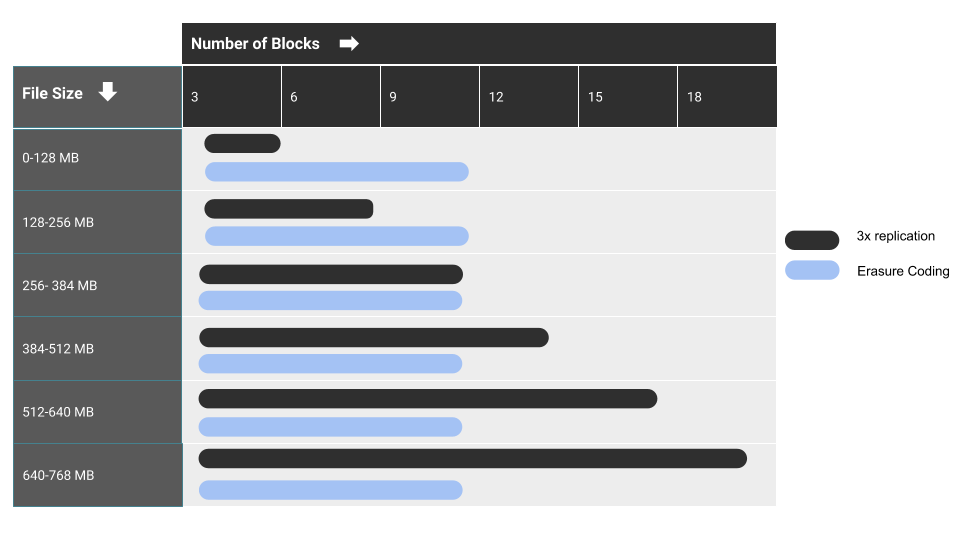
The figure below shows how replication (with a replication factor of 3) compares to EC based on the number of blocks relative to file size. For example, a 128 MB file only requires three blocks because each file fills one block, and three total blocks are needed because of the two additional copies of data that replication maintains. As the file size goes up though, the number of blocks required for data durability with replication goes up.
The number of blocks required for EC remains static up to the 768 MB threshold for RS (6,3).
Comparing 3x Replication and EC Using RS(6,3)
- Supported Engines
-
Replication supports all data processing engines that CDH supports.
EC supports the following data processing engines: Hive, MapReduce, and Spark.
- Unsupported Features
- The XOR codec for EC is not supported. Additionally, certain HDFS functions are not supported with EC: hflush, hsync, concat, setReplication, truncate and append. For more information, see Erasure Coding Limitations. and HDFS Erasure Coding Limitations.
Best Practices for Rack and Node Setup for EC
When setting up a cluster to take advantage of EC, consider the number of racks and nodes in your setup.
Ideally, the number of racks exceed the data-stripe width to account for downtime and outages. If there are fewer racks than the data-stripe width, HDFS spreads data blocks across multiple nodes to maintain fault tolerance at the node level. When distributing blocks to racks, HDFS attempts to distribute the blocks evenly across all racks. Because of this behavior, Cloudera recommends setting up each rack with a similar number of DataNodes. Otherwise, racks with fewer DataNodes may be filled up faster than racks with more DataNodes.
To achieve node-level fault tolerance, the number of nodes needs to equal the data-stripe width. For example, in order for a RS-6-3-1024k policy to be node failure tolerant, you need at least nine nodes. Note that the write will fail if the number of DataNodes is less than the policy's number of data blocks. The write will succeed but show a warning message if the number of DataNodes is less than the policy's number of data blocks + parity blocks. For example, with RS(6,3), if there are six to eight DataNodes, the write will succeed but show a warning message. If there are less than six DataNodes, the write fails.
For rack-level fault tolerance, there must be enough number of racks such that each rack contains at most the same number of blocks as the erasure coding parity blocks. The number of racks is calculated as (data stripe width) / (number of parity blocks). For example, with RS(6,3), the minimum number of racks must be (6+3)/3 = 3. Cloudera recommends at least nine racks, which leads to one data or parity block on each rack. Ideally, the number of racks exceeds the sum of the number of data and parity blocks.
- Rack 1 with three nodes: Three blocks
- Rack 2 with three nodes: Three blocks
- Rack 3 with three nodes: Three blocks
A policy with a wide data-stripe width like RS-6-3-1024k comes with a tradeoff though. Data must be read from six blocks, increasing the overall network load. Choose your EC policy based on your network settings and expected storage efficiency. Note, the larger the cluster and colder the data, the more appropriate it is to use EC policies with large data-stripe widths. Larger data-stripe widths have the benefit of a better storage efficiency.