Configuring Resource Pools and Admission Control
Impala includes features that balance and maximize resources in your CDH cluster. This topic describes how you can improve efficiency of your a CDH cluster using those features.
A typical deployment uses the following:
Creating Static Service Pools
To manage and prioritize workloads on clusters, use the static service pools to allocate dedicated resources for Impala for predictable resource availability. When static service pools are used, Cloudera Manager creates a cgroup in which Impala runs. This cgroup limits memory, CPU and Disk I/O according to the static partitioning policy.
The following is a sample configuration for Static Service Pools shown in Cloudera Manager.
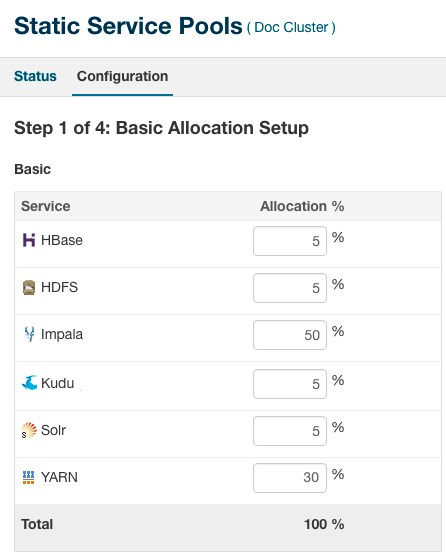
-
HDFS always needs to have a minimum of 5-10% of the resources.
- Generally, YARN and Impala split the rest of the resources.
-
For mostly batch workloads, you might allocate YARN 60%, Impala 30%, and HDFS 10%.
-
For mostly ad-hoc query workloads, you might allocate Impala 60%, YARN 30%, and HDFS 10%.
-
Using Admission Control
Within the constraints of the static service pool, using dynamic resource pools and the admission control, you can further subdivide Impala's resource usage among dynamic resource pools in multitenant use cases.
Allocating resources judiciously allows your most important queries to run faster and more reliably.
Enabling or Disabling Impala Admission Control in Cloudera Manager
We recommend enabling admission control on all production clusters to alleviate possible capacity issues. The capacity issues could be because of a high volume of concurrent queries, because of heavy-duty join and aggregation queries that require large amounts of memory, or because Impala is being used alongside other Hadoop data management components and the resource usage of Impala must be constrained to work well in a multitenant deployment.
- Go to the Impala service.
- In the Configuration tab, select .
- Select or clear both the Enable Impala Admission Control checkbox and the Enable Dynamic Resource Pools checkbox.
- Enter a Reason for change, and then click Save Changes to commit the changes.
- Restart the Impala service.
After completing this task, for further configuration settings, customize the configuration settings for the dynamic resource pools, as described in below.
Creating an Impala Dynamic Resource Pool
There is always a resource pool designated as root.default. By default, all Impala queries run in this pool when the dynamic resource pool feature is enabled for Impala. You create additional pools when your workload includes identifiable groups of queries (such as from a particular application, or a particular group within your organization) that have their own requirements for concurrency, memory use, or service level agreement (SLA). Each pool has its own settings related to memory, number of queries, and timeout interval.
- Select . If the cluster has an Impala service, the tab displays under the Impala Admission Control tab.
- Click the Impala Admission Control tab.
- Click Create Resource Pool.
- Specify a name and resource limits for the pool:
- In the Resource Pool Name field, type a unique name containing only alphanumeric characters.
- Optionally, click the Submission Access Control tab to specify which users and groups can submit queries. By default, anyone can submit queries. To restrict this permission, select the Allow these users and groups option and provide a comma-delimited list of users and groups in the Users and Groups fields respectively.
- Click Create.
- Click Refresh Dynamic Resource Pools.
Configuration Settings for Impala Dynamic Resource Pool
Impala dynamic resource pools support the following settings.- Max Memory
- Maximum amount of aggregate memory available across the cluster to all queries executing in this pool. This should be a portion of the aggregate configured memory for Impala daemons,
which will be shown in the settings dialog next to this option for convenience. Setting this to a non-zero value enables memory based admission control.
Impala determines the expected maximum memory used by all queries in the pool and holds back any further queries that would result in Max Memory being exceeded.
If you specify Max Memory, you should specify the amount of memory to allocate to each query in this pool. You can do this in two ways:
- By setting Maximum Query Memory Limit and Minimum Query Memory Limit. This is preferred in CDH 6.1 and higher and gives Impala flexibility to set aside more memory to queries that are expected to be memory-hungry.
- By setting Default Query Memory Limit to the exact amount of memory that Impala should set aside for queries in that pool.
Note that if you do not set any of the above options, or set Default Query Memory Limit to 0, Impala will rely entirely on memory estimates to determine how much memory to set aside for each query. This is not recommended because it can result in queries not running or being starved for memory if the estimates are inaccurate.
For example, consider the following scenario:- The cluster is running impalad daemons on five hosts.
- A dynamic resource pool has Max Memory set to 100 GB.
- The Maximum Query Memory Limit for the pool is 10 GB and Minimum Query Memory Limit is 2 GB. Therefore, any query running in this pool could use up to 50 GB of memory (Maximum Query Memory Limit * number of Impala nodes).
- Impala will execute varying numbers of queries concurrently because queries may be given memory limits anywhere between 2 GB and 10 GB, depending on the estimated memory requirements. For example, Impala may execute up to 10 small queries with 2 GB memory limits or two large queries with 10 GB memory limits because that is what will fit in the 100 GB cluster-wide limit when executing on five hosts.
- The executing queries may use less memory than the per-host memory limit or the Max Memory cluster-wide limit if they do not need that much memory. In general this is not a problem so long as you are able to execute enough queries concurrently to meet your needs.
- Minimum Query Memory Limit and Maximum Query Memory Limit
- These two options determine the minimum and maximum per-host memory limit that will be chosen by Impala Admission control for queries in this resource pool. If set, Impala admission
control will choose a memory limit between the minimum and maximum value based on the per-host memory estimate for the query. The memory limit chosen determines the amount of memory that Impala
admission control will set aside for this query on each host that the query is running on. The aggregate memory across all of the hosts that the query is running on is counted against the pool’s
Max Memory.
Minimum Query Memory Limit must be less than or equal to Maximum Query Memory Limit and Max Memory.
You can override Impala’s choice of memory limit by setting the MEM_LIMIT query option. If the Clamp MEM_LIMIT Query Option is selected and the user sets MEM_LIMIT to a value that is outside of the range specified by these two options, then the effective memory limit will be either the minimum or maximum, depending on whether MEM_LIMIT is lower than or higher than the range. - Default Query Memory Limit
- The default memory limit applied to queries executing in this pool when no explicit MEM_LIMIT query option is set. The memory limit chosen determines the
amount of memory that Impala Admission control will set aside for this query on each host that the query is running on. The aggregate memory across all of the hosts that the query is running on is
counted against the pool’s Max Memory.
This option is deprecated from CDH 6.1 and higher and is replaced by Maximum Query Memory Limit and Minimum Query Memory Limit. Do not set this field if either Maximum Query Memory Limit or Minimum Query Memory Limit is set.
- Max Running Queries
-
Maximum number of concurrently running queries in this pool. The default value is unlimited for CDH 5.7 or higher. (optional)
The maximum number of queries that can run concurrently in this pool. The default value is unlimited. Any queries for this pool that exceed Max Running Queries are added to the admission control queue until other queries finish. You can use Max Running Queries in the early stages of resource management, when you do not have extensive data about query memory usage, to determine if the cluster performs better overall if throttling is applied to Impala queries.For a workload with many small queries, you typically specify a high value for this setting, or leave the default setting of "unlimited". For a workload with expensive queries, where some number of concurrent queries saturate the memory, I/O, CPU, or network capacity of the cluster, set the value low enough that the cluster resources are not overcommitted for Impala.
Once you have enabled memory-based admission control using other pool settings, you can still use Max Running Queries as a safeguard. If queries exceed either the total estimated memory or the maximum number of concurrent queries, they are added to the queue.
- Max Queued Queries
- Maximum number of queries that can be queued in this pool. The default value is 200 for CDH 5.3 or higher and 50 for previous versions of Impala. (optional)
- Queue Timeout
- The amount of time, in milliseconds, that a query waits in the admission control queue for this pool before being canceled. The default value is 60,000 milliseconds.
It the following cases, Queue Timeout is not significant, and you can specify a high value to avoid canceling queries unexpectedly:
- In a low-concurrency workload where few or no queries are queued
- In an environment without a strict SLA, where it does not matter if queries occasionally take longer than usual because they are held in admission control
In a high-concurrency workload, especially for queries with a tight SLA, long wait times in admission control can cause a serious problem. For example, if a query needs to run in 10 seconds, and you have tuned it so that it runs in 8 seconds, it violates its SLA if it waits in the admission control queue longer than 2 seconds. In a case like this, set a low timeout value and monitor how many queries are cancelled because of timeouts. This technique helps you to discover capacity, tuning, and scaling problems early, and helps avoid wasting resources by running expensive queries that have already missed their SLA.
If you identify some queries that can have a high timeout value, and others that benefit from a low timeout value, you can create separate pools with different values for this setting.
- Clamp MEM_LIMIT Query Option
- If this field is not selected, the MEM_LIMIT query option will not be bounded by the Maximum Query Memory Limit and the Minimum Query Memory Limit values specified for this resource pool. By default, this field is selected in CDH 6.1 and higher. The field is disabled if both Minimum Query Memory Limit and Maximum Query Memory Limit are not set.
Setting Per-query Memory Limits
Use per-query memory limits to prevent queries from consuming excessive memory resources that impact other queries. Cloudera recommends that you set the query memory limits whenever possible.
If you set the Max Memory for a resource pool, Impala attempts to throttle queries if there is not enough memory to run them within the specified resources.
Only use admission control with maximum memory resources if you can ensure there are query memory limits. Set the pool Maximum Query Memory Limit to be certain. You can override this setting with the MEM_LIMIT query option, if necessary.
Typically, you set query memory limits using the set MEM_LIMIT=Xg; query option. When you find the right value for your business case, memory-based admission control works well. The potential downside is that queries that attempt to use more memory might perform poorly or even be cancelled.
- Run the workload.
- In Cloudera Manager, go to .
- Click Select Attributes.
- Select Per Node Peak Memory Usage and click Update.
- Allow the system time to gather information, then click the Show Histogram icon to see the results.

- Use the histogram to find a value that accounts for most queries. Queries that require more resources than this limit should explicitly set the memory limit to ensure they can run to completion.
Configuring Admission Control in Command Line Interface
To configure admission control, use a combination of startup options for the Impala daemon and edit or create the configuration files fair-scheduler.xml and llama-site.xml.
For a straightforward configuration using a single resource pool named default, you can specify configuration options on the command line and skip the fair-scheduler.xml and llama-site.xml configuration files.
- Set up the fair-scheduler.xml and llama-site.xml configuration files manually.
- Provide the paths to each one using the impalad command-line options, ‑‑fair_scheduler_allocation_path and ‑‑llama_site_path respectively.
The Impala admission control feature only uses the Fair Scheduler configuration settings to determine how to map users and groups to different resource pools. For example, you might set up different resource pools with separate memory limits, and maximum number of concurrent and queued queries, for different categories of users within your organization. For details about all the Fair Scheduler configuration settings, see the Apache wiki.
The Impala admission control feature only uses a small subset of possible settings from the llama-site.xml configuration file:
llama.am.throttling.maximum.placed.reservations.queue_name
llama.am.throttling.maximum.queued.reservations.queue_name
impala.admission-control.pool-default-query-options.queue_name impala.admission-control.pool-queue-timeout-ms.queue_name
The impala.admission-control.pool-queue-timeout-ms setting specifies the timeout value for this pool, in milliseconds.
Theimpala.admission-control.pool-default-query-options settings designates the default query options for all queries that run in this pool. Its argument value is a comma-delimited string of 'key=value' pairs, for example,'key1=val1,key2=val2'. For example, this is where you might set a default memory limit for all queries in the pool, using an argument such as MEM_LIMIT=5G.
The impala.admission-control.* configuration settings are available in CDH 5.7 / Impala 2.5 and higher.
Example Admission Control Configuration Files
For clusters not managed by Cloudera Manager, here are sample fair-scheduler.xml and llama-site.xml files that define resource pools root.default, root.development, and root.production. These files define resource pools for Impala admission control and are separate from the similar fair-scheduler.xml that defines resource pools for YARN.
fair-scheduler.xml:
Although Impala does not use the vcores value, you must still specify it to satisfy YARN requirements for the file contents.
Each <aclSubmitApps> tag (other than the one for root) contains a comma-separated list of users, then a space, then a comma-separated list of groups; these are the users and groups allowed to submit Impala statements to the corresponding resource pool.
If you leave the <aclSubmitApps> element empty for a pool, nobody can submit directly to that pool; child pools can specify their own <aclSubmitApps> values to authorize users and groups to submit to those pools.
<allocations>
<queue name="root">
<aclSubmitApps> </aclSubmitApps>
<queue name="default">
<maxResources>50000 mb, 0 vcores</maxResources>
<aclSubmitApps>*</aclSubmitApps>
</queue>
<queue name="development">
<maxResources>200000 mb, 0 vcores</maxResources>
<aclSubmitApps>user1,user2 dev,ops,admin</aclSubmitApps>
</queue>
<queue name="production">
<maxResources>1000000 mb, 0 vcores</maxResources>
<aclSubmitApps> ops,admin</aclSubmitApps>
</queue>
</queue>
<queuePlacementPolicy>
<rule name="specified" create="false"/>
<rule name="default" />
</queuePlacementPolicy>
</allocations>
llama-site.xml:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>llama.am.throttling.maximum.placed.reservations.root.default</name>
<value>10</value>
</property>
<property>
<name>llama.am.throttling.maximum.queued.reservations.root.default</name>
<value>50</value>
</property>
<property>
<name>impala.admission-control.pool-default-query-options.root.default</name>
<value>mem_limit=128m,query_timeout_s=20,max_io_buffers=10</value>
</property>
<property>
<name>impala.admission-control.pool-queue-timeout-ms.root.default</name>
<value>30000</value>
</property>
<property>
<name>impala.admission-control.max-query-mem-limit.root.default.regularPool</name>
<value>1610612736</value><!--1.5GB-->
</property>
<property>
<name>impala.admission-control.min-query-mem-limit.root.default.regularPool</name>
<value>52428800</value><!--50MB-->
</property>
<property>
<name>impala.admission-control.clamp-mem-limit-query-option.root.default.regularPool</name>
<value>true</value>
</property>
Configuring Cluster-wide Admission Control
The following Impala configuration options let you adjust the settings of the admission control feature. When supplying the options on the impalad command line, prepend the option name with --.
- queue_wait_timeout_ms
- Purpose: Maximum amount of time (in milliseconds) that a request waits to be admitted before timing out.
Type: int64
Default: 60000
- default_pool_max_requests
- Purpose: Maximum number of concurrent outstanding requests allowed to run before incoming requests are queued. Because this limit applies cluster-wide,
but each Impala node makes independent decisions to run queries immediately or queue them, it is a soft limit; the overall number of concurrent queries might be slightly higher during times of heavy
load. A negative value indicates no limit. Ignored if fair_scheduler_config_path and llama_site_path are set.
Type: int64
Default: -1, meaning unlimited (prior to CDH 5.7 / Impala 2.5 the default was 200)
- default_pool_max_queued
- Purpose: Maximum number of requests allowed to be queued before rejecting requests. Because this limit applies cluster-wide, but each Impala node makes
independent decisions to run queries immediately or queue them, it is a soft limit; the overall number of queued queries might be slightly higher during times of heavy load. A negative value or 0
indicates requests are always rejected once the maximum concurrent requests are executing. Ignored if fair_scheduler_config_path and llama_site_path are set.
Type: int64
Default: unlimited
- default_pool_mem_limit
- Purpose: Maximum amount of memory (across the entire cluster) that all outstanding requests in this pool can use before new requests to this pool are
queued. Specified in bytes, megabytes, or gigabytes by a number followed by the suffix b (optional), m, or g, either uppercase or lowercase. You can specify floating-point values for megabytes and gigabytes, to represent fractional numbers such as 1.5. You
can also specify it as a percentage of the physical memory by specifying the suffix %. 0 or no setting indicates no limit. Defaults to bytes if no unit is given.
Because this limit applies cluster-wide, but each Impala node makes independent decisions to run queries immediately or queue them, it is a soft limit; the overall memory used by concurrent queries
might be slightly higher during times of heavy load. Ignored if fair_scheduler_config_path and llama_site_path are set.
Type: string
Default: "" (empty string, meaning unlimited)
- disable_pool_max_requests
- Purpose: Disables all per-pool limits on the maximum number of running requests.
Type: Boolean
Default: false
- disable_pool_mem_limits
- Purpose: Disables all per-pool mem limits.
Type: Boolean
Default: false
- fair_scheduler_allocation_path
- Purpose: Path to the fair scheduler allocation file (fair-scheduler.xml).
Type: string
Default: "" (empty string)
Usage notes: Admission control only uses a small subset of the settings that can go in this file, as described below. For details about all the Fair Scheduler configuration settings, see the Apache wiki.
- llama_site_path
- Purpose: Path to the configuration file used by admission control (llama-site.xml). If set, fair_scheduler_allocation_path must also be set.
Type: string
Default: "" (empty string)
Usage notes: Admission control only uses a few of the settings that can go in this file, as described below.