
Previously in Part 4, we described the most commonly used FairScheduler properties in Apache Hadoop. In Part 5, we’ll provide some examples to show how properties can be used, individually and in combination, to achieve commonly desired behavior such as application prioritization and organizing queues.
Example: Best Effort Queue
Summary: Create a “best effort” queue that runs applications when the cluster is underutilized.
Implementation: In FairScheduler, a queue with weight 0.0 will only run applications if there is spare capacity in the cluster. In other words, all the jobs in the priority_jobs queue will get allocated first, and then FairScheduler will allocate any such spare capacity to the best_effort_jobs queue.
<queue name=”priority_jobs”>
</queue>
<queue name=”best_effort_jobs”>
<weight>0.0</weight>
</queue>
Notes:
- Jobs in cluster may take a long time to finish if the cluster is fully utilized with running jobs in other queues.
Caveat: There is a bug in early versions of CDH where the value 0.0 won’t quite work properly, but really tiny values (e.g. 0.01) work just fine. YARN-5077 fixes the issue and is in releases CDH 5.7.3, CDH 5.8.2, CDH 5.9.0 and later.
Example: Using maxResources to Guarantee Resources for Low Latency Applications
Summary: Have a special queue which runs applications with special low latency requirements.
Implementation: Assume we have a cluster with the following resources: <memory: 20000 gb, vcores: 10000>. By setting the maxResources property on the other_jobs queue, FairScheduler leaves <memory: 4000 gb, vcores: 2000> for the low_latency queue.
<queue name=”root”>
<queue name=”low_latency” />
<queue name=”other_jobs”>
<maxResources>16000 gb,8000 vcores</maxResources>
</queue>
</queue>
Notes:
- All the applications in the other_jobs queue total utilization cannot exceed 80% of the cluster.
- By leaving roughly 20% of the cluster for the low_latency queue, applications there can get started as quickly as possible.
- This case is provided purely as an example. In many cases, it will be preferable to use the “Queues for Low Latency Applications using Preemption” below.
Example: Using Preemption to Guarantee Resources to Low Latency Applications without Compromising on Utilization
Summary: Have a special queue which runs applications with special low latency requirements.
Implementation: Assume we have a cluster with the following resources: <memory: 20000 gb, vcores: 10000>. This configuration turns on preemption on the low_latency queue.
<queue name=”root”>
<queue name=”low_latency”>
<fairSharePreemptionThreshold>1.0</fairSharePreemptionThreshold>
<fairSharePreemptionTimeout>1</fairSharePreemptionTimeout>
</queue>
<queue name=”other_jobs”>
</queue>
</queue>
Notes:
- Unlike the maxResources version (see previous example), the full cluster is available to the other_jobs queue, but applications in the other_jobs can be preempted in order for the low_latency queue to start applications running.
- If you still wish to limit the total cluster usage of the low_latency queue, maxResources could be applied.
- There are two more examples of priority queues later that show how preemption can be used in a more sophisticated fashion.
- Reminder: To enable preemption in FairScheduler, this property must be set in yarn-site.xml:
<property>
<name>yarn.scheduler.fair.preemption</name>
<value>true</value>
</property>
Example: Limiting the Size of Ad-Hoc Queues
Summary: Allow child ad-hoc queues to have a maxResources setting
Implementation: Normally, it is impossible to set properties on ad-hoc queues, since they are not defined in the fair-scheduler.xml file. By setting the maxChildResources property on the some_parent queue, any children of that queue (e.g. ad-hoc user queues or ad-hoc group queues) will have the equivalent of <maxResources>8192 mb,8 vcores</maxResources> set.
<queue name=”some_parent”>
<maxChildResources>8192 mb,8 vcores</maxChildResources>
</queue>
Notes:
- This feature was introduced in and is new to CDH 5.9.0.
Example: Organizational Queues
Summary: Give each organization a queue for their applications.
Implementation: Provide a queue for each organization, in this case sales, marketing, finance, and data science. Each group is given an equal share of Steady FairShare.
<queue name=”root”>
<queue name=”sales” />
<queue name=”marketing” />
<queue name=”data_science” />
</queue>
Hierarchical Implementation: The sales organization has northamerica and europe subqueues. The marketing organization has reports and website queues. The data_science organization has priority and best_effort queues.
<queue name=”root”>
<queue name=”sales”>
<queue name=”northamerica” />
<queue name=”europe” />
<queue name=”asia” />
</queue>
<queue name=”marketing”>
<queue name=”reports” />
<queue name=”website” />
</queue>
<queue name=”data_science”>
<queue name=”priority”>
<weight>100.0</weight>
</queue>
<queue name=”best_effort”>
<weight>0.0</weight>
</queue>
</queue>
</queue>
Example: Strict Priority Queuing
Summary: This is an alternative approach to priority queues.
Implementation: In the previous example, FairScheduler is using preemption to enforce a container allocation of 100/10/1. In this version the root.other and root.other.other queues are given a weight of 0. This has the following consequences:
- Any jobs in the priority1 queue will be fully allocated first, then any spare resources are given to jobs in the priority2 queue. Finally, any spare resources after that will be given to the priority3 queue.
- If each of the priority queues have jobs beyond the capacity of the cluster, then jobs in the priority2 queue will only begin after the total resource requirements of all jobs in priority1 fall below the capacity of the cluster. The same goes for jobs in the priority2 queue getting allocated ahead of jobs in the priority3 queue.
- If jobs are added to the priority1 queue, then containers will be allocated to those new jobs as tasks finish from the queues priority2 and priority3. Similarly, if new jobs are added to the priority2 queue (and assuming priority1 jobs stay fully allocated), then those jobs will get containers as tasks finish in the priority3 queue.
<queue name=”root”>
<queue name=”priority1”>
</queue>
<queue name=”other”>
<weight>0</weight>
<queue name=”priority2”>
</queue>
<queue name=”other”>
<weight>0</weight>
<queue name=”priority3”>
</queue>
</queue>
</queue>
</queue>
Notes:
- If preemption is enabled on all queues, then any jobs added to the priority1 queue will immediately preempt from jobs in priority2 and priority3. Similarly, any added jobs in the priority2 queue will preempt from jobs in the priority3 queue.
- As many levels of hierarchy can be added as needed in order to suit your needs.
- As mentioned in the “Best Effort Queue” example earlier, there is a bug in early versions of CDH where the value 0.0 won’t quite work properly, but really tiny values (e.g. 0.01) work just fine.
Example: Implementing Priority Using Preemption
Summary: Given the following situation: (a) a cluster running at capacity, and (b) a “high priority” queue whose allocation is below its FairShare. Turning on preemption guarantees that resources will be made available within the timeout value provided.
Implementation: Preemption must be enabled in FairScheduler by setting this property in yarn-site.xml:
<property>
<name>yarn.scheduler.fair.preemption</name>
<value>true</value>
</property>
Below is an example for a queue in fair-scheduler.xml. If the queue does not receive 80% of its FairShare within 60 seconds, FairScheduler will begin preempting applications from some_other_queue and giving resources to priority_queue.
<queue name=”priority_queue”>
<weight>75.0</weight>
<fairSharePreemptionThreshold>0.8</fairSharePreemptionThreshold>
<fairSharePreemptionTimeout>60</fairSharePreemptionTimeout>
</queue>
<queue name=”some_other_queue”>
<weight>25.0</weight>
</queue>
Example: Implementing More Levels of Priority Using Preemption
Summary: When two levels of priorities isn’t sufficient for separating job priority needs, you can have three levels of priorities with preemption.
Implementation: The high_priority and medium_priority queues have preemption enabled. The low_priority queue will not have preemption enabled. In order to prevent the medium_priority queue from preempting containers from the high_priority queue, we will also set the allowPreemptionFrom property on high_priority.
<queue name=”root”>
<queue name=”high_priority”>
<weight>100.0</weight>
<fairSharePreemptionThreshold>0.9</fairSharePreemptionThreshold>
<fairSharePreemptionTimeout>120</fairSharePreemptionTimeout>
<allowPreemptionFrom>false</allowPreemptionFrom>
</queue>
<queue name=”medium_priority”>
<weight>10.0</weight>
<fairSharePreemptionThreshold>0.5</fairSharePreemptionThreshold>
<fairSharePreemptionTimeout>600</fairSharePreemptionTimeout>
</queue>
<queue name=”low_priority”>
<weight>1.0</weight>
</queue>
</queue>
Notes: Notice this uses the new allowPreemptionFrom property, introduced in CDH 5.7.0.
Gotcha: Setting up a separate queue for Oozie launcher jobs
Summary: When Oozie starts an action, the launcher job requires using one MapReduce Application Master with one Task to actually launch the job. In cases where Oozie launches many actions simultaneously, the queue and/or cluster could hit maxAMShare with Oozie Launcher MapReduce AMs, which will cause deadlock since any subsequent YARN applications cannot launch an AM.
The solution is to put the Oozie launcher jobs into a separate queue and restrict the queue as needed.
Example:
- In your Oozie Workflows, set the property oozie.launcher.mapred.job.queue.name to point to the Oozie launcher queue:
<property>
<name>oozie.launcher.mapred.job.queue.name</name>
<value>launcher</value>
</property>
- And in FairScheduler, you should create the queue for the launcher jobs
<queue name=”launcher”>
<maxRunningApps>10</maxRunningApps>
</queue>
Notes:
- This is not a FairScheduler specific issue. However, this interaction between Oozie and YARN is a sufficiently common issue that it is documented here. This issue is especially common on small clusters.
- Putting a restriction like maxResources or maxRunningApps on the launcher queue will help prevent the Oozie launcher jobs from deadlocking the cluster.
Gotcha: Setting hard limits on root or a parent queue
Summary: In FairScheduler, hard limits like maxRunningApps or maxResources propagate top-down. Similarly, setting such a property on the root queue will affect all queues.
Example: root.parent1 has maxRunningApps set to 1. As a result, despite the settings to maxRunningApps to a value greater than 1 in the childA and childB queues, only one application can be running in total.
<allocations>
<queue name="root">
<queue name="parent1">
<maxRunningApps>1</maxRunningApps>
<queue name="childA">
<maxRunningApps>3</maxRunningApps>
</queue>
<queue name="childB">
<maxRunningApps>3</maxRunningApps>
</queue>
</queue>
</queue>
</allocations>
Gotcha: Deleting Queues
Summary: There isn’t a direct way to delete queues by command line or UI. However, if you update your fair-scheduler.xml configuration file and remove a queue that was in the file, then upon the next scheduler configuration refresh, the queue will be removed.
Solution: Make sure all applications in the queue have status FINISHED before actually changing the configuration. In the case of MR applications, also make sure they are saved in the JobHistoryServer.
Gotcha: FairScheduler Preemption is Global
Summary: Preemption in FairScheduler is global. The scheduler looks at all queues which are above their FairShare, takes those resources, and allocates them to queues which are below their FairShare. There currently is no form of restricting preemption to a subset of queues or to only allow preemption from queueA to queueB.
Solution: The allowPreemptionFrom property allows some limited version of preemption control. Future versions of FairScheduler may allow other forms of control or grouping.
Gotcha: Small Clusters and/or lots of Really Large Jobs
Summary: It is not uncommon for users to run small clusters, where number of active queues (with jobs) is comparable to the amount of resources (vcores or GBs) in the cluster. This can happen in testing/staging clusters. A similar situation ensues when too many large jobs are submitted to the same queue. In these cases, the cluster might get into a livelock or the jobs may be really slow.
Solution: Consider limiting the number of queues on a small cluster. Also, consider limiting the number of running jobs in a queue by setting the maxRunningApps property. For example:
<queue name=”big_jobs”>
<maxRunningApps>5</maxRunningApps>
</queue>
Extra Reading
To get more information about Fair Scheduler, take a look at the online documentation (Apache Hadoop and Cloudera CDH 5.9.x versions are available).
Thanks
Thanks to Andre Araujo, Paul Battaglia, Stephanie Bodoff, Haibo Chen, Spandan Dutta, Yufei Gu, Jonathan Hsieh, Patrick Hunt, Adrian Kalaszi, Karthik Kambatla, Robert Kanter, Justin Kestelyn, Vijay Kalluru, Cris Morris, Sandy Ryza, Grant Sohn, Wilfred Spiegelenburg, Juan Yu, and Yongjun Zhang for their reviews and comments on this multi-part blog post.
Ray Chiang is a Software Engineer at Cloudera.
Dennis Dawson is a Senior Technical Writer at Cloudera.
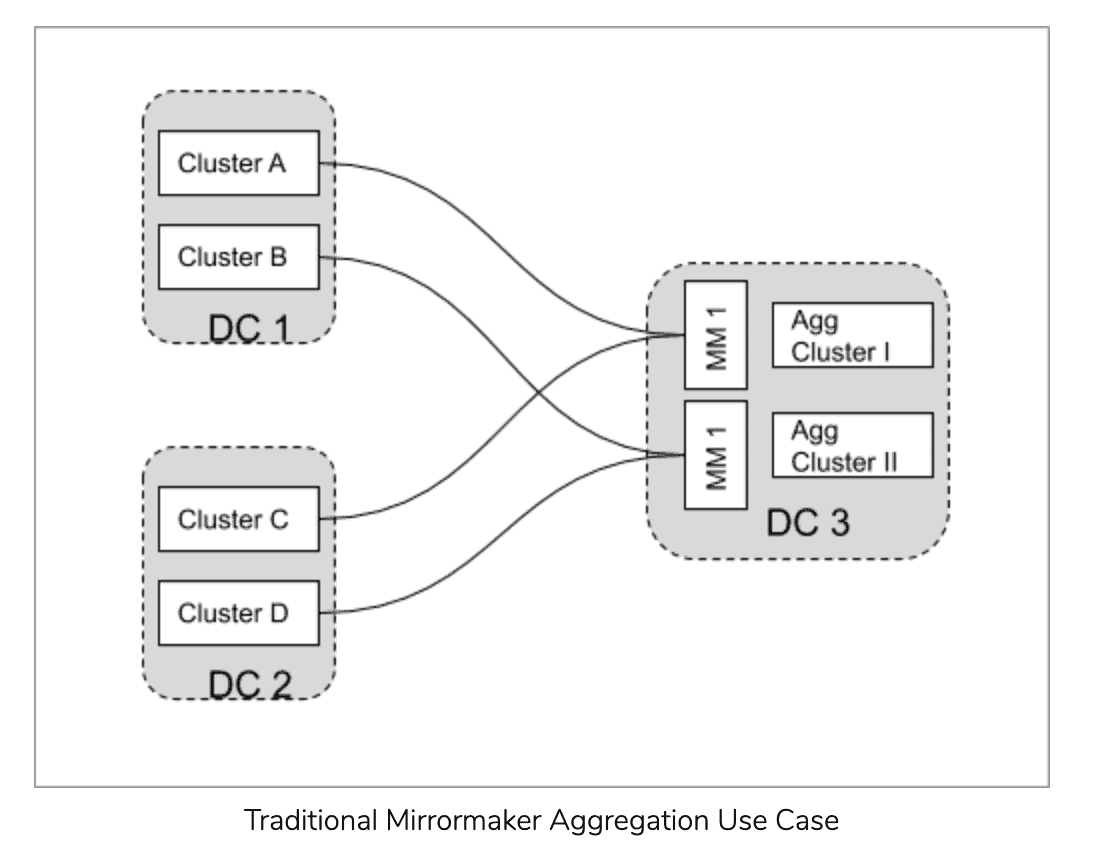
Typical MirrorMaker Use Cases
There are many uses cases why data in one Kafka cluster needs to be replicated to another cluster. Some of the common ones are:
Aggregation for Analytics
A common use case is to aggregate data from multiple streaming pipelines possibly across multiple data centers to run batch analytics jobs that provide a holistic view across the enterprise, for example, a completeness check that all customer requests had been processed..
Data Deployment after Analytics
This is the opposite of the aggregation use case in which the data generated by the analytics application in one cluster (say the aggregate cluster) is broadcast to multiple clusters possibly across data centers for end user consumption.
Isolation
Sometimes access to data in a production environment is restricted for performance or security reasons and data is replicated between different environments to isolate access. In many deployments the ingestion cluster is isolated from the consumption clusters.
Disaster Recovery
One of the most common enterprise use cases for cross-cluster replication is for guaranteeing business continuity in the presence of cluster or data center-wide outages. This would require application and the producers and consumers of the Kafka cluster to failover to the replica cluster.
Geo Proximity
In geographically distributed access patterns where low latency is required, replication is used to move data closer to the access location.
Cloud Migration
As more enterprises have an on prem and cloud presence Kafka replication can be used to migrate data to the public or private cloud and back.
Legal and Compliance
Much like the isolation uses case, a policy driven replication is used to limit what data is accessible in a cluster to meet legal and compliance requirements.
Limitations of MirrorMaker v1
MirrorMaker is widely deployed in production but has serious limitations for enterprises looking for a flexible, high performing and resilient mirroring pipeline. Here are some of the concerns:
Static Whitelists and Blacklists
To control what topics get replicated between the source and destination cluster MirrorMaker uses whitelists and blacklists with regular expressions or explicit topic listings. But these are statically configured. Mostly when new topics are created that match the whitelist the new topic gets created at the destination and the replication happens automatically. However, when the whitelist itself has to be updated, it requires MirrorMaker instances to be bounced. Restarting MirrorMaker each time the list changes creates backlogs in the replication pipeline causing operational pain points.
No Syncing of Topic Properties
Using MMv1, a new or existing topic at the source cluster is automatically created at the destination cluster either directly by the Kafka broker, if auto.create.topics is enabled, or by MirrorMaker enhancements directly using the Kafka admin client API. The problem happens with the configuration of the topic at the destination. MMv1 does not promise the topic properties from the source will be maintained as it relies on the cluster defaults at the destination. Say a topic A had a partition count of 10 on the source cluster and the destination cluster default was 8, the topic A will get created on the destination with 8 partitions. If an application was relying on message ordering within a partition to be carried over after replication then all hell breaks loose. Similarly, the replication factor could be different on the destination cluster changing the availability guarantees of the replicated data. Even if the initial topic configuration was duplicated by an admin, any dynamic changes to the topic properties are not going to be automatically reflected. These differences become an operational nightmare very quickly.
Manual Topic Naming to avoid Cycles
By default, MirrorMaker creates a topic on the destination cluster with the same name as that on the source cluster. This works fine if the replication was a simple unidirectional pipeline between a source and destination cluster. A bidirectional active-active setup where all topics in cluster A are replicated to cluster B and vice versa would create an infinite loop which MirrorMaker cannot prevent without explicit naming conventions to break the cycle. Typically the cluster name is added in each topic name as a prefix with a blacklist to not replicate topics that had the same prefix as the destination cluster. In large enterprises with multiple clusters in multiple data centers it is easy to create a loop in the pipeline if care is not taken to set the naming conventions correctly.
Scalability and Throughput Limitations due to Rebalances
Internally, MirrorMaker uses the high-level consumer to fetch data from the source cluster where the partitions are assigned to the consumers within a consumer group via a group coordinator (or earlier via Zookeeper). Each time there is a change in topics, say when a new topic is created or an old topic is deleted, or a partition count is changed, or when MirrorMaker itself is bounced for a software upgrade, it triggers a consumer rebalance which stalls the mirroring process and creates a backlog in the pipeline and increases the end to end latency observed by the downstream application. Such constant hiccups violate any latency driven SLAs that a service dependent on mirrored pipeline needs to offer.
Lack of Monitoring and Operational Support
MirrorMaker provides minimal monitoring and management functions to configure, launch and monitor the state of the pipeline and has no ability to trigger alerts when there is a problem. Most enterprises require more than just the basic scripts to start and stop a replication pipeline.
No Disaster Recovery Support
A common enterprise requirement is to maintain service availability in the event of a catastrophic failure such as the loss of the entire cluster or an entire data center. Ideally in such an event, the consumers and producers reading and writing to a cluster should seamlessly failover to the destination cluster and failback when the source cluster comes back up. MirrorMaker doesn’t support this seamless switch due to a fundamental limitation in offset management. The offsets of a topic in the source cluster and the offset of the replica topic can be completely different based on the point in the topic lifetime the replication began. Thus the committed offsets in the consumer offsets topic are tracking a completely different location at the source than at the destination. If the consumers make a switch to the destination cluster they cannot simply use the value of the last committed offset at the source to continue. One approach to deal with this offset mismatch is to rely on timestamps (assuming time is relatively in sync across clusters). But timestamps get messy too and we will discuss that at length in the next blog in the series, “A look inside MirrorMaker 2.
Lack of Exactly Once Guarantees
MirrorMaker is not setup to utilize the support for exactly once processing semantics in Kafka and follows the default at least once semantics provided by Kafka. Thus duplicate messages can show up in the replicated topic especially after failures, as the produce to the replicated topic at the destination cluster and the update to the __consumer_offsets topic at the source cluster are not executed together in one transaction to get exactly once replication. Mostly it is a problem left to the downstream application to handle duplicates correctly.
Too many MirrorMaker Clusters
Traditionally a MirrorMaker cluster is paired with the destination cluster. Thus there is a mirroring cluster for each destination cluster following a remote-consume and local-produce pattern. For example, for 2 data centers with 8 clusters each and 8 bidirectional replication pairs there are 16 MirrorMaker clusters. For large data centers this can significantly increase the operational cost. Ideally there should be one MirrorMaker cluster per destination data center. Thus in the above example there would be 2 MirrorMaker clusters, one in each data center.
What is coming in MirrorMaker 2
MirrorMaker 2 was designed to address the limitations of MirrorMaker 1 listed above. MM2 is based on the Kafka Connect framework and has the ability to dynamically change configurations, keep the topic properties in sync across clusters and improve performance significantly by reducing rebalances to a minimum. Moreover, handling active-active clusters and disaster recovery are use cases that MM2 supports out of the box. MM2 (KIP-382) is accepted as part of Apache Kafka. If you’re interested in learning more, take a look at Ryanne Dolan’s talk at Kafka Summit, and standby for the next blog in this series for “A Look inside MirrorMaker 2”.