Cloudera Data Warehouse
Manage and analyze massive amounts of data for thousands of concurrent users without compromising speed, cost, or security.

OVERVIEW
Easily transform all data, anywhere, into meaningful business insights.
A cloud-native, self-service analytic experience that outperforms other data warehouses on all sizes and types of data while scaling cost-effectively.
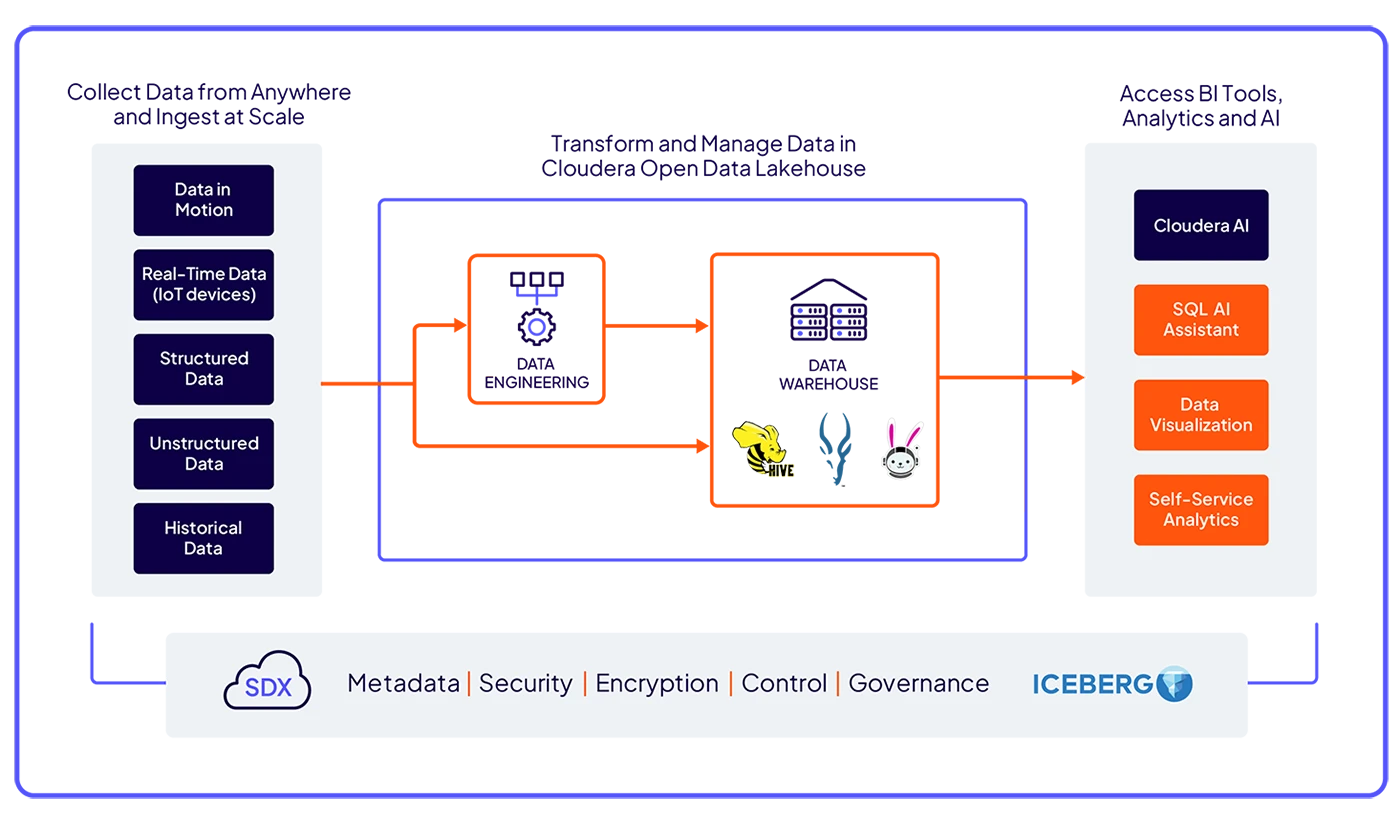
Unlock powerful insights with advanced SQL engines for high-speed querying, intelligent automations, AI-assisted SQL, and optimized workload performance.
Build analytic workflows confidently and securely on a unified platform, powered by Apache Iceberg, that ensures seamless access to data anywhere.
Deliver workload flexibility through cloud-native, open-source engines with full control over your data and no vendor lock-in.
USE CASES
Use the right engine for the right workload at a lower cost.
-
Deeper insights with federated queries and ad-hoc exploration
Analyze data from various systems with a single SQL query.
-
Enhanced decision support and business intelligence
Provide self-service access to any data, anywhere, delivering critical insights fast.
-
Improved data quality with ETL pipelines and batch processing
Access flexible and fast analytics on structured and unstructured data.
-
Multi-function analytics with Apache Iceberg
Transform and prep large volumes of structured data for downstream analysis and reporting.
-
Deeper insights with federated queries and ad-hoc exploration
Analyze data from various systems with a single SQL query.
-
Enhanced decision support and business intelligence
Provide self-service access to any data, anywhere, delivering critical insights fast.
-
Improved data quality with ETL pipelines and batch processing
Access flexible and fast analytics on structured and unstructured data.
-
Multi-function analytics with Apache Iceberg
Transform and prep large volumes of structured data for downstream analysis and reporting.

Empower data analysts and scientists to query vast analytical datasets across disparate sources.
Analyze data from diverse sources without the need for data migration or complex integration.

Empower users with self-service, low-latency access to event and time-series data.
Build interactive reports and dashboards that use real-time data at scale and enable rapid query execution.

Execute complex queries over massive datasets and high-volume scheduled jobs.
Support the transformation and preparation of large volumes of structured data for downstream analysis and reporting.

Empower users to leverage their preferred tools for data analysis.
Achieve seamless interoperability with third-party engines and unify data across your organization, fostering enhanced collaboration.
Cloudera Data Warehouse key features
Acts as a domain expert and SQL guide: Users describe data needs in natural language, and the assistant finds relevant data, then writes, optimizes, and explains the query in easy-to-understand terms.
Provides built-in AI to BI capabilities and seamless out-of-the-box visuals via Cloudera Data Visualization. Build interactive dashboards and instantly share insights across your business.
Maximizes mixed-workload execution within a single virtual warehouse. This approach delivers the best price-for-performance, ensuring your data operations run smoothly, affordably, and cost efficiently.
Supports a wide array of workloads and data types, including structured and unstructured data. This versatility extends to any workload requirement: advanced analytics, dashboard reporting, or real-time processing.
Integrates on-premises and cloud environments with built-in unified security and governance. Hybrid capabilities, data access, portability, and scalability allow engines to securely read and write data across different form factors.
Migrating to Apache® Iceberg For Dummies
Read this step-by-step blueprint for migrating your workloads to Apache Iceberg.

Customers
Customers grow and innovate with Cloudera Data Warehouse.
Investing in Cloudera has empowered Axis Bank to fully leverage its data, driving innovation, efficiency and significantly enhancing our ability to deliver exceptional customer experiences.
 healthcare
IQVIA
healthcare
IQVIA
 manufacturing and automotive
International
manufacturing and automotive
International
 transportation
GEODIS
transportation
GEODIS
Agent-ready Data to Power Your AI
Build your next AI agent, powered by your enterprise data, in a secure and controlled way.

{kind=link}
Take the next step
Want to see Cloudera Data Warehouse in action? Or get the inside-scoop on our latest product updates? It’s easy.
Explore the documentation
In-depth technical details, quick-starts, and release notes for Cloudera Data Warehouse.
Join the community
Stay connected and up-to-date by joining the Cloudera Community.
Explore more products
Make smart decisions with a flexible platform that processes any data, anywhere, for actionable analytics and trusted AI.
Bring the power of AI to your business securely and at scale, ensuring every insight is traceable, explainable, and trusted.
Securely build, orchestrate, and govern enterprise-grade data pipelines with Apache Spark on Iceberg.
Accelerate data-driven decision making from research to production with a secure, scalable, and open platform for enterprise AI.
Enable business users to quickly and easily explore governed data, collaborate, and unlock insights with AI-powered dashboards.