
This blog is part two of two
I recently joined Cloudera to lead Developer Relations (DevRel), and I’m excited to build out this team and connect with the worldwide developer community.
In this blog post, I’ll share what I’ve seen in my first month on the job and what excites me most about what we’re building here. My goal is to enable practitioners to learn, explore, and build with technologies that matter—whether that’s open data architectures with Apache Iceberg; streaming systems with Apache Flink, Kafka, and NiFi; or generative AI (GenAI) applications. So, importantly, I’ll discuss how Cloudera’s platform and data services can support running and delivering these technologies, securely, at scale, anywhere (clouds, data centers, and at the edge) with the openness and trust that developers expect.
In part one, I cover what Developer Relations means for Cloudera. While the DevRel function can look different from one organization to another, our focus will be on educating, engaging, and building a two-way relationship with developers.
My First 30 Days: What I’ve Seen
What struck me right away at Cloudera is how much emphasis is placed on openness and the flexibility it creates for those building on the platform. True to its open-source foundations, Cloudera still values and prioritizes openness, which is evident in its approach to open standards and frameworks. That’s why so much investment is going into technologies that carry that vision forward.
Prioritizing Openness
Take Apache Iceberg, as an example. Cloudera has been an early proponent of Iceberg as the foundation for an open data architecture because it reflects that same vision of openness and interoperability.
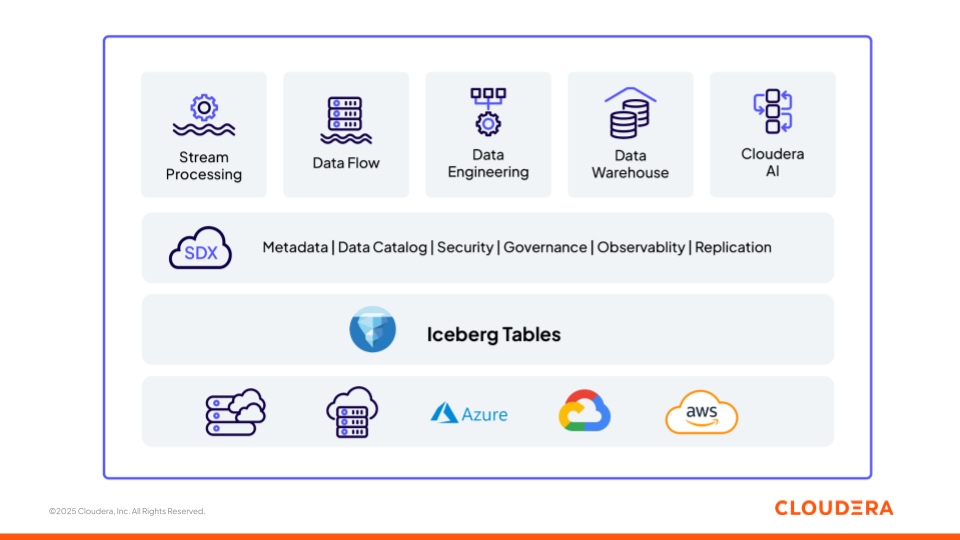
Figure 1: Apache Iceberg as the foundation for open data architecture with Cloudera
Iceberg gives developers an open table format that isn’t tied to one engine or one vendor. You can write data with Spark, stream updates with Flink, query with Trino or Hive—all against the same table. That level of interoperability has traditionally been limited, if not absent, in other data architectures such as cloud data warehouses, but it’s exactly what modern data and AI platforms need. For customers, this becomes a real advantage. By building their data architecture on Iceberg, they make themselves future-proof, and any new compute engine can be plugged into the same tables without costly migrations or lock-in.
Building on that, the Iceberg REST Catalog takes openness a step further. While open table formats like Iceberg have broadened access to data, the catalog is another critical component in the lakehouse architecture that needs to be interoperable.
Today, there are many different catalog implementations—both open-source and proprietary. The challenge is that managing Iceberg tables across different catalogs has historically required custom integrations, making true interoperability difficult. On top of that, many vendor platforms only provide full support if developers use their own built-in catalog. That dependency limits what can be shared with other engines and tools, creating a new form of lock-in.

Figure 2: Comparative representation of catalogs with different implementations and catalogs that speak ‘REST’
This is exactly the problem the Iceberg REST Catalog was designed to solve. The REST Catalog API provides a universal standard for server–client communication, ensuring that Iceberg clients can interact with any compliant catalog, regardless of the server implementation’s underlying technology or programming language. Users can create tables, branch versions, or list snapshots through the same API—no matter which catalog sits underneath.
For developers, this removes the need for one-off connectors and reduces friction when adopting new engines. For organizations, it helps avoid locking Iceberg tables into a single platform’s catalog, while still keeping governance and security consistent. In short, everyone speaks the same “language.”
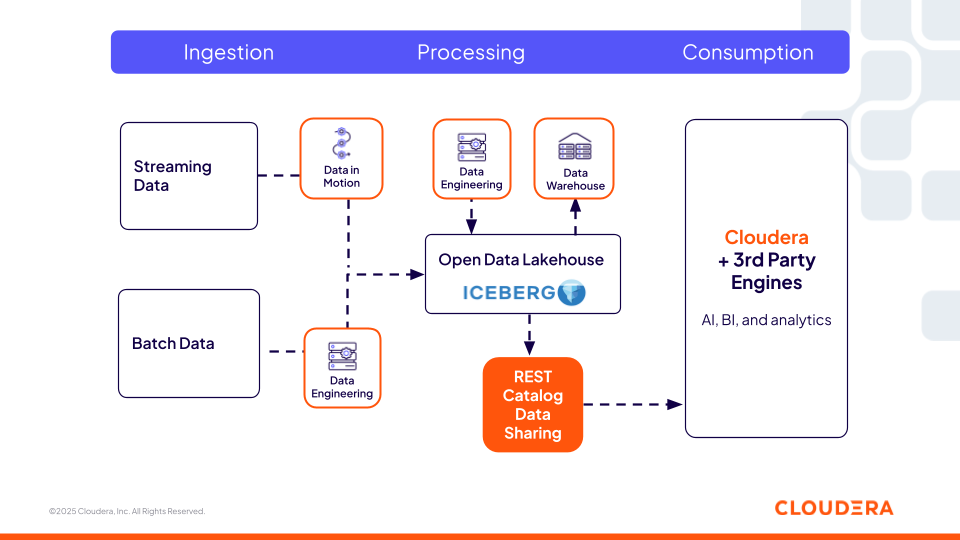
Figure 3: Cloudera Iceberg REST Catalog and how it offers interoperability with 3rd party engines.
Launching New Technologies
That’s why it was exciting to see the launch of the Cloudera Iceberg REST Catalog at NYC EVOLVE. With this release, developers can use third-party engines to access Cloudera-managed data directly—without copying or moving it around. Just as important, the same security and governance policies follow the data everywhere, ensuring consistency no matter where it’s accessed.
Alongside the REST Catalog, we also announced the Lakehouse Optimizer. For engineers (particularly with Iceberg), this matters because it takes care of the tedious, behind-the-scenes work that usually comes with managing Iceberg tables. Instead of manually handling tasks like compacting small files, rewriting manifests, or cleaning up position deletes, the optimizer does this automatically.
What that translates to is simple: faster queries and lower storage costs, without developers needing to constantly tune or babysit their tables. And since it’s built as an open service, the same optimizations apply no matter which Iceberg-compatible engine you’re running.
The same mindset of openness shows up in how Cloudera approaches GenAI workloads. Instead of betting on just closed-source models (which have their own advantages and challenges), Cloudera AI embraces flexibility: support for open-source large language models (LLMs) like LLaMA, Mistral, and Hugging Face, plus the ability to fine-tune them on enterprise-specific data. That matters because developers want choice. They want to train, fine-tune, and deploy models in their own infrastructure with the same security and governance as the rest of their stack.
Creating Two-Way Feedback Loops
And, finally, there’s the momentum. At NYC EVOLVE, I saw firsthand how engineers and decision-makers are leaning in and asking questions about deploying GenAI use cases, integrating Iceberg into their architecture, and making their data architectures more open, future-proof, and cost friendly. That kind of curiosity is what excites me. It reinforces why building a stronger developer community is so important here.
Our goal within Developer Relations is to turn those conversations into something actionable. This means showing how developers can build open architectures with Iceberg, how they can run multi-compute pipelines seamlessly with interoperability guarantees, and how they can build AI agents on top of their lakehouse data, among other groundbreaking innovations.
Figure 4: Cloudera’s Enterprise Intelligent Center at NYC EVOLVE
My Next 30 Days: What I’m Looking Forward To Most
I love how Cloudera focuses on developers. Teams here talk constantly about how to make things easier to use, how to remove friction, and how to listen to feedback from practitioners in the field. That mindset of putting developer productivity and real-world needs first is exactly where Developer Advocacy can add value.
We’re building a home for the developer community—a place where engineers can learn, try out things, and build without friction. Our focus is on helping developers move from “this looks hard” to “I can build this” with the right patterns, explanations, and tools.
To materialize that vision of a true home for developers, keep an eye out for a Cloudera Developer Hub—a central place where the community can find all of this content, access labs, ask questions, and exchange ideas with other practitioners.
More to come on that soon! In the meantime, stay up to date with our latest practitioner news by subscribing to the Cloudera Community.
