
Inorganic growth strategies, such as mergers and acquisitions (M&A), serve as strategic growth levers, enabling companies to realize revenue and cost synergies or to rapidly acquire emerging capabilities that will deliver long-term competitive advantage. Today, for instance, we observe major organizations acquiring smaller, innovative AI start-ups to accelerate their AI transformation efforts and gain a competitive edge.
Technology integration plays a crucial role in value capture from M&As. A Deloitte study argues that IT is a key driver of integration benefits, accounting for more than 50% of all synergies. However, due to the proliferation of data silos and varying technology architectures and environments, organizations face several post-merger data challenges in realizing technology integration benefits.
This article introduces a five-step framework to address those challenges and accelerate value capture in M&A settings. This framework will ensure your post-merger data strategy with Cloudera delivers the capabilities needed to streamline the technology integration process.
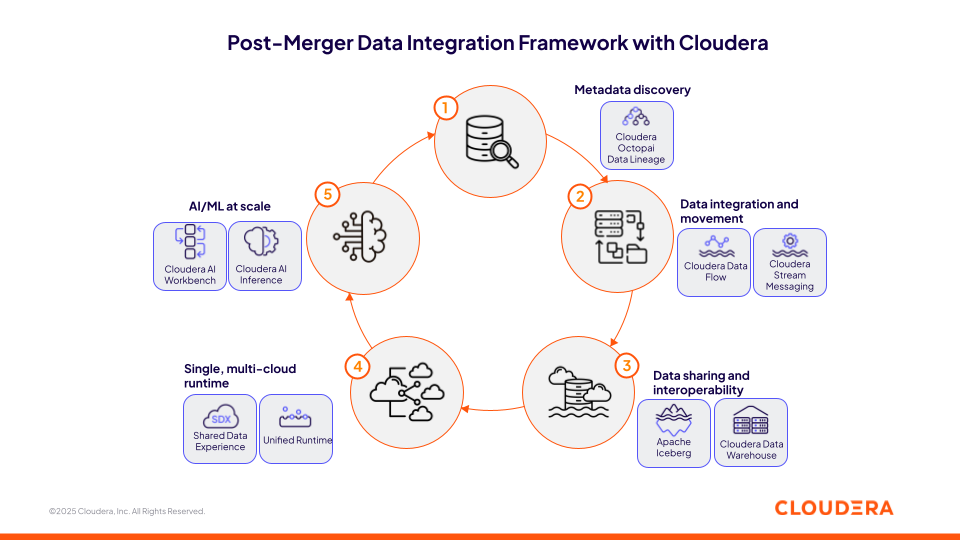
Figure 1: Post-Merger Data Integration Framework with Cloudera
1. Accelerate Post-Merger Integration with Cloudera Octopai Data Lineage
At the start of post-merger integration, the data discovery phase frequently becomes a bottleneck, since fragmented and undocumented sources delay critical analytics and compliance efforts. Cloudera Octopai Data Lineage addresses this challenge by providing an automated, AI-powered metadata management solution that accelerates data discovery, end-to-end lineage, and cataloging across complex hybrid and multi-cloud environments.
Cloudera Octopai Data Lineage effectively maps data flows and fills metadata gaps, providing multi-dimensional lineage that traces origins and transformations for complete visibility. With more than 60 native integrations and universal connectors for non-native systems, Cloudera Octopai Data Lineage streamlines the onboarding of acquired data estates, thereby improving data transparency, quality, and trust.
For example, in banking merger scenarios, this capability facilitates rapid identification and tagging of risk-related datasets, ensuring compliance with regulatory standards such as BCBS 239, while minimizing the need for extensive manual audits or intervention.
2. Integrate Disparate Data Sources with Cloudera Data In Motion
Integrating diverse data sources and eliminating complex, custom ETL pipelines is a critical post-merger challenge. Cloudera delivers robust capabilities for batch and real-time data ingestion, processing, and data distribution through Cloudera Data Flow (powered by Apache NiFi) and Cloudera Streaming (powered by Apache Kafka and Apache Flink).
With more than 450 connectors, Cloudera Data Flow provides a visual, drag-and-drop interface to ingest data from a variety of heterogeneous data sources, whether on-premises, in the clouds, or at the edge. In addition, Cloudera Streaming provides a messaging bus architecture that decouples source systems from consuming systems between the two entities, thereby eliminating point-to-point integrations that add architectural complexity and higher costs.
During post-merger integration, these capabilities can significantly accelerate and simplify data movement between organizations. For instance, Cloudera Data Flow can be used to quickly integrate on-premises data from legacy source systems of the acquired company into the cloud-native data warehouse of the parent company, expediting decision-making.
3. Build a Secure Data Sharing Layer on Cloudera Open Data Lakehouse with Apache Iceberg
Data sharing between merging entities is an essential requirement for integrated decision-making and deriving insights. This process can be complex due to the diverse exploratory analytics and business intelligence technologies, as well as the varying data security models used by different systems.
An open data lakehouse approach that combines Apache Iceberg, the Cloudera Iceberg REST Catalog, and Cloudera Shared Data Experience (SDX) enables organizations to develop a unified data sharing layer. This layer is compatible with various analytical engines (for example, Snowflake, Databricks, AWS EMR, AWS Athena, and Salesforce Data Cloud, as long as these engines are Iceberg REST Catalog enabled) and provides a fine-grained security and governance model to manage access for a diverse range of users, including the newly integrated data science teams.
For example, two healthcare organizations engaged in drug manufacturing can leverage Cloudera to construct a GxP-compliant data lakehouse that consolidates the data assets of the merging entities while ensuring adherence to regulatory requirements.
4. Standardize Cross-Environmental Initiatives on a Single, Multi-Cloud Environment
The different environments used for analytical activities in the two merging entities lead to duplicative operations throughout the data lifecycle, including multiple data engineering pipelines for common tasks such as data ingestion and standardization.
Cloudera empowers organizations to standardize data and AI operations on a common runtime across various private and public cloud environments. This capability derives from the underlying containerized infrastructure model used across environments, a consistent user authentication and authorization mechanism (Cloudera SDX), and Cloudera Manager, which serves as the single pane of glass for managing clusters across different deployment environments and regions.
In a post-merger context, this standardization is transformative: the two companies can integrate their data lifecycle operations onto a single runtime, eliminating redundant tools and facilitating the sharing of data, insights, and AI models. This leads to reduced technology and labor costs for data operations and AI/ML model development, increased practitioner productivity, consolidation of multiple tools, and reduction of data silos.
5. Scale AI Initiatives Anywhere with Cloudera AI
Post-acquisition or merger, the immediate challenge is integrating the disparate tools, models, and data scientists from the newly acquired innovative start-up, all while managing changing capacity demands. Cloudera AI Workbench and AI Inference empower organizations to scale AI initiatives on-premises or in the cloud by:
Providing a container-based, end-to-end solution for feature engineering, model training, experimentation tracking, and model deployment
Facilitating AI model sharing that allows data scientists to collaborate among disparate teams
Leveraging hardware and software acceleration services from Clouder partners that can speed up the entire data science lifecycle by improving data engineering performance by 20x and AI inference performance by up to 6x
With Cloudera, the integrated company can achieve substantial cost reduction by moving persistent, compute-intensive workloads such as AI/ML model serving to on-premises environments. More importantly, it can accelerate the time-to-market for new, combined AI applications. This allows the organization to rapidly realize the “competitive advantage” it sought from the M&A in the first place
Take the Next Step to Ensure Successful Integration After Your Next Merger and Acquisition
Cloudera can accelerate the post-merger integration of data assets and analytical capabilities between the two integrating entities. Our platform offers scalability across the data lifecycle, an infrastructure-agnostic deployment model, and interoperability of the data lakehouse on Cloudera services and Apache Iceberg. This combination provides an architectural blueprint for standardizing AI/ML initiatives and data operations, and for delivering a data sharing model that can be used by both Cloudera and non-Cloudera services.
To schedule a demo or product tour, contact our team.
