open source
Apache Iceberg on Cloudera
Solve the toughest data challenges by unifying your data, analytics, and AI with Apache Iceberg.

Migrating to Apache® Iceberg For Dummies
Overview
Why Apache Iceberg?
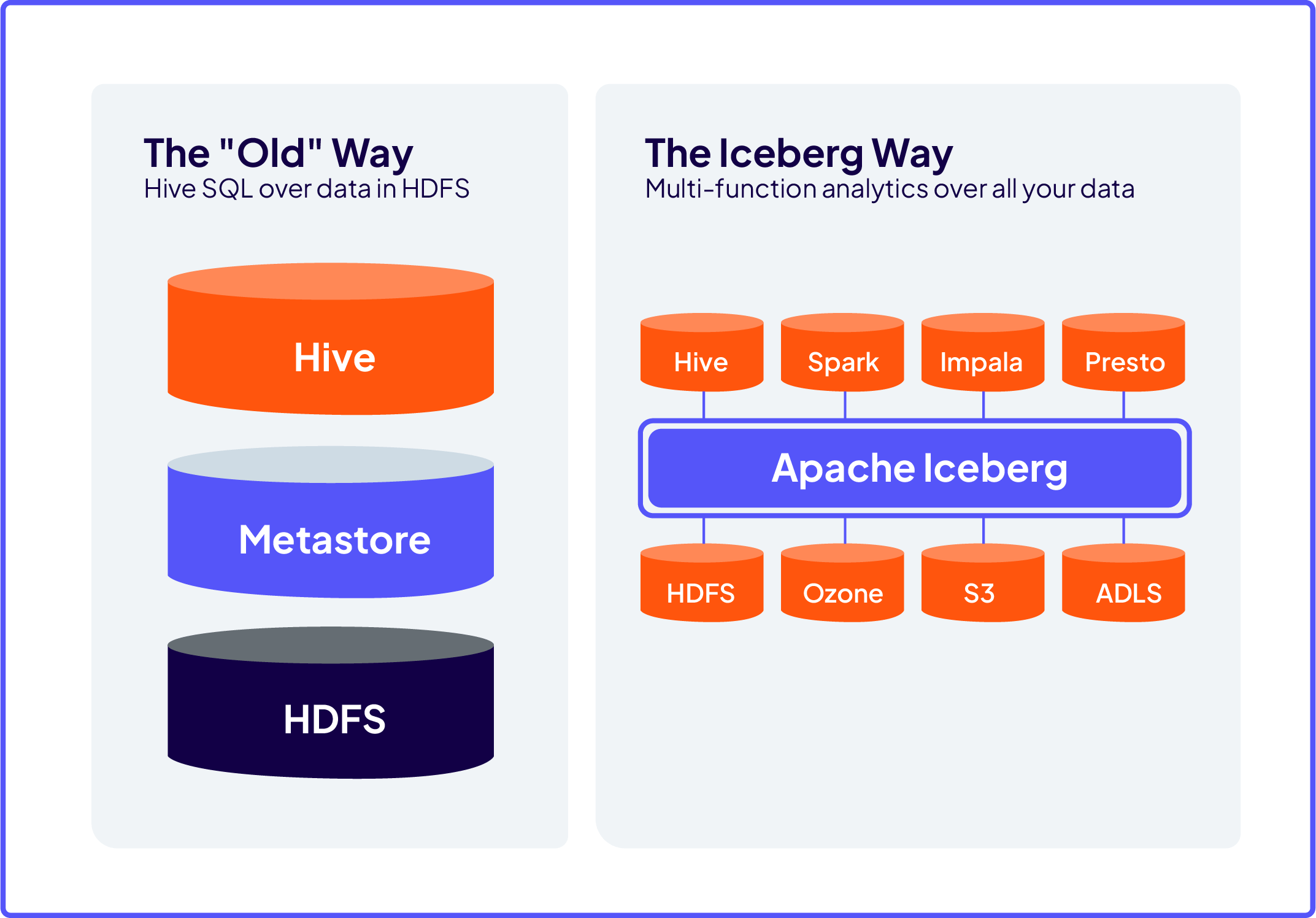
Apache Iceberg is an open table format purpose-built for large scale analytics. It delivers the reliability and simplicity of SQL tables, providing data warehouse-like capabilities directly on data lake storage.
Apache Iceberg is not a storage, it’s not a database, and it’s not a compute engine. It is a metadata management layer that sits on top of your data files, stored wherever you want. Iceberg makes data accessible to multiple compute engines concurrently while guaranteeing data reliability and consistency.
Agent-ready Data to Power Your AI
Build your next AI agent, powered by your enterprise data, in a secure and controlled way.

Reasons for adopting Iceberg.
Openness
Iceberg is fully open, vendor-agnostic, and engine-agnostic. It has the broadest community support from both vendors and non-vendors, which accelerates unbiased innovation.
Modern data warehouse functionality
Iceberg features, such as transactional consistency, hidden partitioning, schema evolution, and time travel, ease data operations.
Petabyte-scale analytics
Iceberg was built from the ground up, eliminating the bottlenecks of previous table formats by maintaining its own metadata layer
Apache Iceberg on Cloudera.
We integrate Iceberg as a first-class citizen, right into our Data Lakehouse.
Run high-performance analytics, data engineering, data science, and AI, while bringing the right engine for the right job to your data in place, eliminating data movement and data copies.
Abstract storage from compute. Get unified access to structured, semi-structured, and unstructured data in the data lakehouse. Use built-in AI chatbots to explore and leverage all of your data.
Why run Apache Iceberg on Cloudera?

The only hybrid open data lakehouse powered by Iceberg
Deploy anywhere, on any cloud or in your data center, wherever your data resides
Multi-engine support
Get the broadest set of pre-integrated data services and capabilities for ingestion, processing, analytics and AI to support your entire data lifecycle
Lower TCO by up to 75%
Common standard for data with unified security and governance, eliminates ETL, data silos, and data copies, reducing TCO by up to 75%
Benefits of Cloudera's open data lakehouse, powered by Apache Iceberg
Democratize data: Empower everyone to access data-driven insights with natural language
Accelerate analytics and AI: Deploy Generative AI applications and dashboards on your data
Keep data open & interoperable: Own your data and leverage your choice of tools
Future-proof your data lake with interoperability
Migrating to Apache® Iceberg For Dummies
Customers
Apache Iceberg guarantees full ownership of your data
Cloudera’s open data lakehouse with Iceberg means we have an open table format with a lot of advanced functionality, which makes it easier to use and maintain our data. The open table format is important to us, because it means data can be accessed easily by many users with a variety of tools. The open table format is a fundamental requirement because the company data is the property of the company itself, not a specific vendor. So an open table format guarantees that whatever may happen with technology in the future, you have full ownership of your data.
 retail
eMAG
retail
eMAG
 telecommunications
Eutelsat Group
telecommunications
Eutelsat Group
 public sector
CDC
public sector
CDC
Documentation
Getting started with Apache Iceberg
From quick-starts to technical details and beyond, learn everything you need to get started with Apache Iceberg on Cloudera.
Apache Iceberg in Cloudera on private cloud
VIEW DOCUMENTATION
Apache Iceberg in Cloudera on public cloud
VIEW DOCUMENTATION
Apache Iceberg in an open data lakehouse
VIEW DOCUMENTATION
Migrating Hive tables to Iceberg tables
VIEW DOCUMENTATION