Democratize Data for AI Using Interoperability Across Engines and Zero-Copy Data Collaboration




How Cloudera Iceberg REST Catalog Enables Open, AI-Ready Enterprises
Interoperability has long been a buzzword, not a capability enterprises can count on in practice. Instead, data architects are often left stitching together fragmented systems, chief data officers face massive risk and vendor lock-in from siloed governance, and platform leaders are restricted from providing a consistent data view to their teams. Whether driven by mergers, multi-cloud strategies, or external partnerships, the pattern repeats: rising costs, slower innovation, and limited ability to scale AI with confidence.
At Cloudera, we’ve helped our customers navigate these challenges—disconnected metadata layers, duplicated data pipelines, and governance models that fail to extend across tools—always striving to enable open, AI-ready enterprises that unlock interoperability at scale.
Why Openness Matters for Enterprise AI
To scale AI workloads, organizations require visibility and control over the data that fuels them. Metadata intelligence plays a critical role in this equation, enabling organizations to understand where data lives, how it’s structured, and how it’s used across teams and tools.
With open standards like Apache Iceberg and the Iceberg REST Catalog, enterprises gain a unified layer of metadata that supports zero-ETL data sharing, enforces governance, and powers secure interoperability across analytics and AI engines. This foundation transforms fragmented infrastructure into a connected, AI-ready data architecture—one where metadata becomes the key to accelerating access to insights while maintaining trust.
Open, Secure, and Simple: Cloudera Iceberg REST Catalog
The Cloudera Iceberg REST Catalog powers our open data lakehouse and helps organizations simplify architecture, reduce duplication, and extend secure data access wherever it’s needed.
It acts as a universal, interoperable metadata layer and provides zero-copy access to Iceberg tables across tools, clouds, and teams, enabling open-source and third-party tools to access the same data. Features and benefits include:
- Open and engine-agnostic: Provides standards-based APIs that support tools like Athena, Databricks, Redshift, and Snowflake—enabling interoperability without vendor lock-in
- Decoupled by design: Abstracts query engines from backend metastores, reducing complexity and increasing portability across environments
- Real-time metadata access: Supports fast, up-to-date metadata queries from Iceberg-compatible metastores, improving data visibility across teams
- Governed and secure: Extends fine-grained access controls, row-level permissions, and enterprise identity access management (IAM) integration (such as LDAP and OAuth2) to all connected systems—ensuring consistent policy enforcement at scale
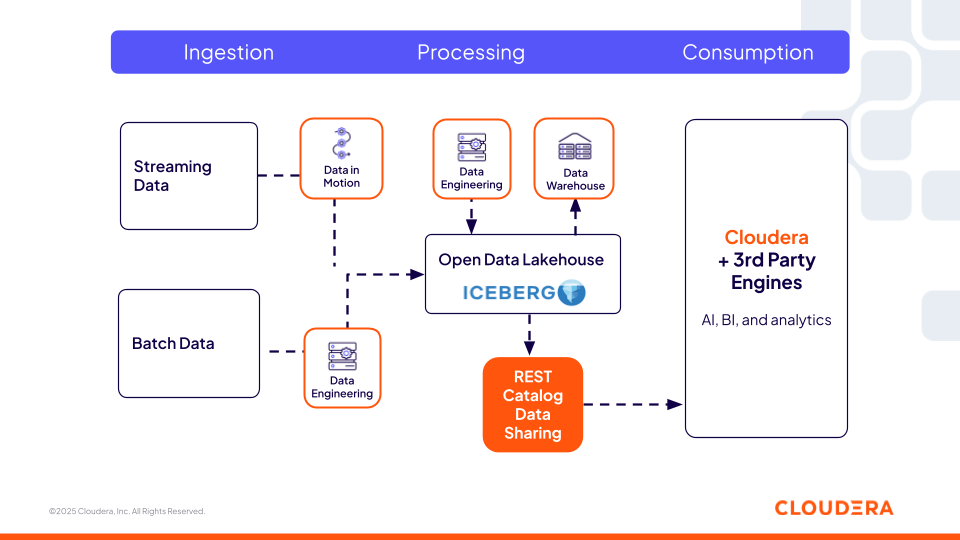
Figure 1. Cloudera's Iceberg REST Catalog provides a universal, interoperable metadata layer, enabling open source and third-party tools to access the same data.
Real-World Use Cases and Impact of Iceberg REST Catalog
The following real-world examples illustrate how organizations are using the Iceberg REST Catalog to simplify their data stack, reduce total cost of ownership (TCO), and accelerate time to value–all while keeping data where it belongs.
Together, these examples demonstrate how Cloudera’s open and interoperable approach accelerates AI outcomes, drives operational efficiency at enterprise scale, and enables security and compliance.
Data Sharing: Scale AI Applications to 3,000+ Cross-Platform Users
A luxury automotive manufacturer faced mounting challenges in securely sharing data with an external partner using Databricks. Traditional methods relied on data duplication, which introduced cost, complexity, and architectural inflexibility.
By adopting the Iceberg REST Catalog, the customer established secure, zero-ETL data sharing across both internal systems and external platforms. This open, standards-based approach allowed them to choose the best tools for the job—using Spark for complex data pipelines and Impala for fast SQL analytics. With this foundation, the company scaled AI applications to more than 3,000 users while maintaining full governance and control over data access.
Data Warehouse Optimization: Reduce Data Movement Costs 74%
Following a merger activity, a global satellite company encountered significant roadblocks in unifying fragmented data locked in proprietary systems. Without a consistent, interoperable data layer, their AI and analytics initiatives were slow to scale and difficult to manage.
Cloudera’s open data lakehouse architecture, powered by the Iceberg REST Catalog, helped the customer consolidate these silos and establish a single source of truth for all of its AI and analytics workloads. By querying managed Iceberg tables directly in S3, they eliminated the need for redundant data pipelines and replatforming efforts, leading to a 74% reduction in data movement costs.
Demo: A Closer Look at Data Sharing via Cloudera’s Iceberg REST Catalog
This interactive demo brings the Iceberg REST Catalog to life through a financial services scenario. At the fictional Parent Bank, different teams use their preferred tools—such as Snowflake and AWS Athena—to securely access one governed source of data, all without complex ETL or costly data movement.
For a deeper dive into this offering and how it can benefit your organization, explore these resources:
- Visit our product page to learn more about Cloudera’s open data lakehouse.
- Read the press release for the full announcement about Cloudera’s vision for open data sharing.