Cloudera Data Flow
Achieve universal data distribution, agility, and scale without limits.

Accelerate AI and analytics through effective data distribution
Cloudera Data Flow is a cloud-native data service powered by Apache NiFi that facilitates universal data distribution by streamlining the end-to-end process of data movement.
Seamlessly move any data from any source to any destination across data centers and clouds with 450+ agnostic connectors.
Maximize efficiency with simplified architecture, side-stepping data lock-in while reducing the proliferation of tools and duplicative data movement.
Reach next-level agility by enabling no-code developer self-service across all phases of the data pipeline lifecycle.
Cloudera is the only vendor to support Apache NiFi 2.0
On premises
In the public cloud
And as operators for Kubernetes for bring-your-own cluster deployments
USE CASES
Deliver business-critical data in real time with maximum efficiency.
-
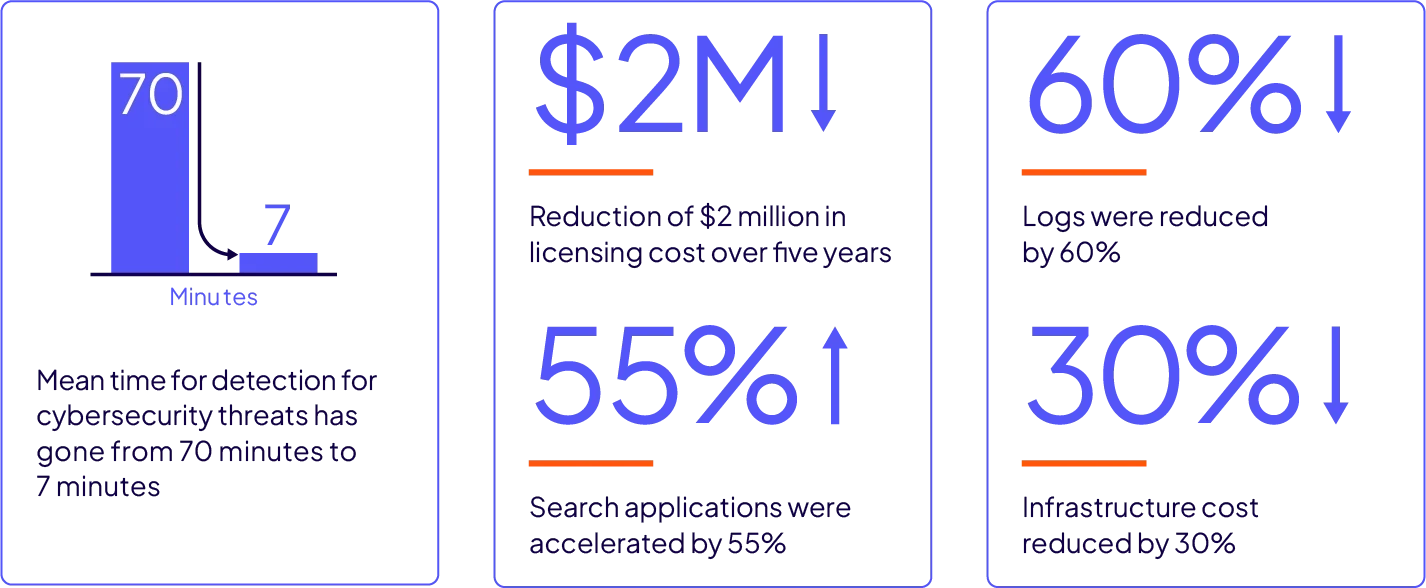
Immediate fraud, cyber threat, and anomaly detection
Reduce time to detect on mission-critical events to milliseconds.
-
Streamline process automation with real-time AI agents
Immediately flow context and events to AI agents to drive proactive actions.
-
Real-time observability
Adjust any process in real time with immediate situational awareness.
-
Immediate fraud, cyber threat, and anomaly detection
Reduce time to detect on mission-critical events to milliseconds.
-
Streamline process automation with real-time AI agents
Immediately flow context and events to AI agents to drive proactive actions.
-
Real-time observability
Adjust any process in real time with immediate situational awareness.
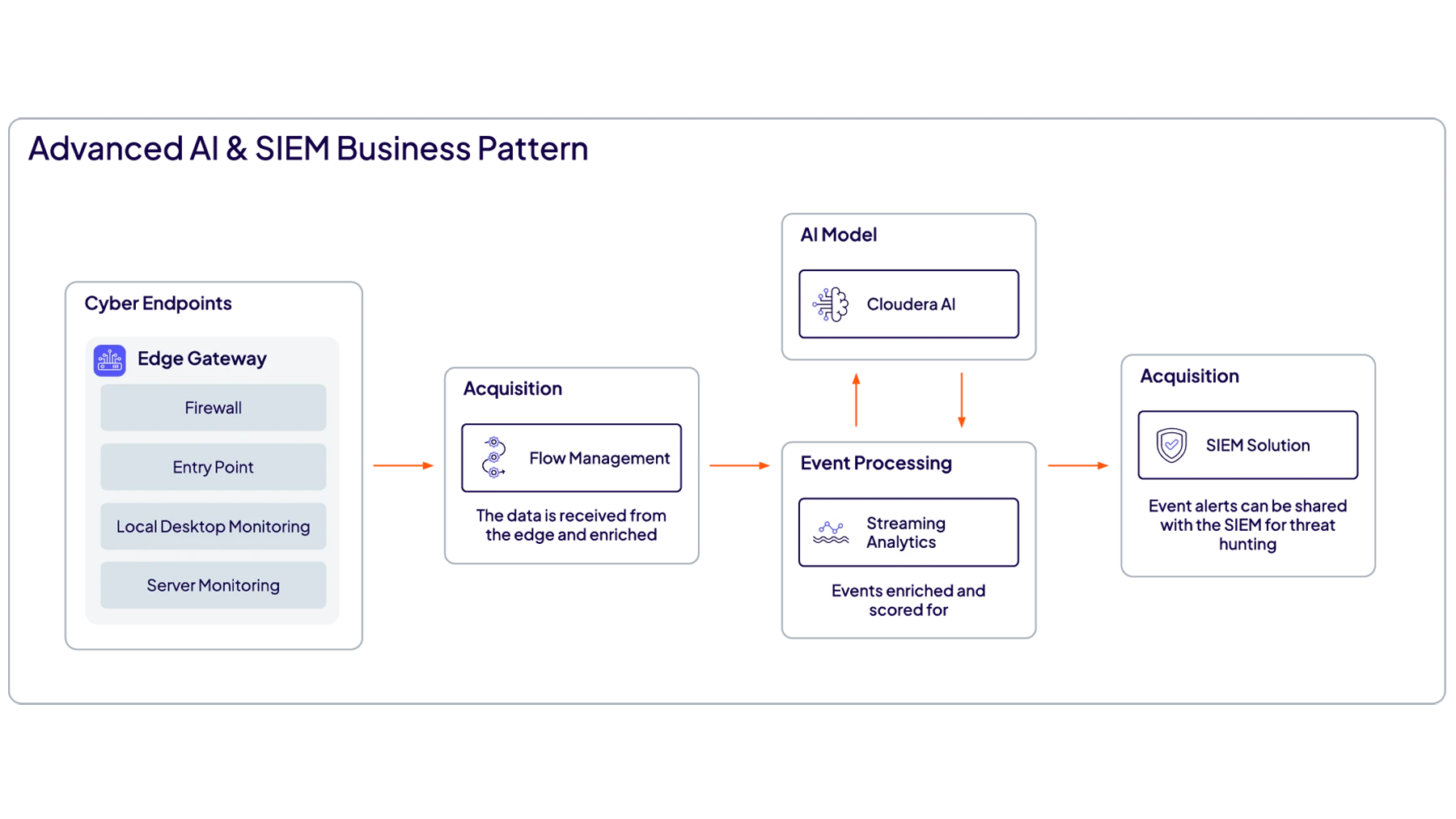
Process and analyze data as it happens to prevent anomalies, cyber attacks, and fraud.
Act on data immediately from edge to cloud to stop damage before it happens.
Fuel AI agents with fresh multimodal data and add real-time context to prompts.
Provide AI agents the most recent context and data when reasoning and automating action.
Continuous visibility, faster decisions, and greater operational resilience.
Instantly detect, understand, and respond to critical events across business operations.
Capture and process data of any type from any system or device to make data accessible for analysis and deliver in real time to any user or system.
Enable rapid deployment of common data flows, leading to faster business outcomes through “author once, deploy anywhere” functionality. Simplify version management to accommodate evolving business and data needs.
Enable serverless, cost-optimized, and scalable operations. Supports event-driven use cases and real-time file processing via AWS Lambda, Azure Functions, and Google Cloud Functions. Build microservices triggered by HTTPS requests via an intuitive no-code UI.
Consolidate the monitoring of all NiFi flow deployments into a single dashboard. Set up KPI alerts for flow deployments to track critical performance metrics. Achieve dynamic scalability to maintain performance and meet SLAs efficiently.
Universal connectivity
Universal connectivity to any system, on premises or in any cloud, through purpose-built connectors for data streams, databases, data lakes, enterprise applications, and more, leveraging industry-standard protocols.
FEATURED CONNECTORS
Apache Iceberg
DATA LAKES & DATA WAREHOUSES
Apache Kafka
DATA STREAMS
Delta Lake
DATA LAKES & DATA WAREHOUSES
Google BigQuery
DATA LAKES & DATA WAREHOUSES
MongoDB
DATABASES
Salesforce
ENTERPRISE APPLICATIONS
Snowflake
DATA LAKES & DATA WAREHOUSES

Milvus
GENERATIVE AI
Deployment options
Any data, anywhere, with flexible deployment options.
Cloudera on cloud
Deploy Data Flow as part of Cloudera on cloud and benefit from simplified management and elasticity.
Cloudera on premises
Deploy a NiFi flow as part of Cloudera Flow Management to minimize latency and maximize control over data and resources.
As operator for Kubernetes
Deploy Cloudera Flow Management Operator for Kubernetes independently for fastest time to value.
Customers
Data Flow drives real value across industries.
We aim to become even more agile with hybrid cloud and utilize AI that can help us create more impactful digital advertising. Cloudera has been one of our partners in transforming our business to offer services beyond telco.

 public sector
IRS
public sector
IRS
 technology
Telkomsel
technology
Telkomsel
 public sector
SEDI GO
public sector
SEDI GO
{kind=link}
Take the next step
Discover how Cloudera Data Flow can help you connect to any data source, process, and deliver to any destination.
Data Flow documentation
Read the documentation for Cloudera Data Flow on Cloud with self-serve deployments of Apache NiFi data flows from a central catalog.
Data Flow architecture
Dig deeper with an overview of Cloudera Data Flow architecture.
Explore more products
Ingest, process, and analyze real-time structured and unstructured data anywhere it lives for immediate insight, action, and AI.
Tap into Kafka and Flink to create high-performance, real-time services and applications to drive your business.
Manage, control, and monitor data from edge devices with real-time collection and processing at the edge.
Accelerate data-driven decision making from research to production with a secure, scalable, and open platform for enterprise AI.