
Cloudera’s open foundations enable organizations to access 100% of their data, wherever it resides
Across industries, data teams are rethinking how to build and run systems that do more than store information: they’re looking to turn data into intelligence. Just as important, they need these systems to interoperate. AI models, feature pipelines, business intelligence (BI) reports, and batch jobs often span multiple teams and engines. Sharing data across those boundaries without copying or refactoring is now a first-order requirement.
Traditionally, organizations have relied on a two-tier architecture: data warehouses optimized for BI and reporting, and data lakes designed for large-scale AI and machine learning (ML). This separation came at a cost: complex data movement, specialized engineering, and duplicated storage across systems that rarely stayed in sync.
Cloudera’s open lakehouse architecture addresses this challenge, bringing together analytical (BI, ad-hoc queries) and AI (predictive and generative AI, or GenAI) workloads on a single, governed data foundation. With open table formats like Apache Iceberg, this unified data architecture enables organizations to bring compute to data (not the other way around) and provides the foundation for running AI workloads closer to the data. AI workloads on the lakehouse can operate directly on governed, versioned, and high-quality data.
Cloudera is the only data and AI platform company that brings AI to data anywhere. Leveraging our proven open-source foundation, we deliver a consistent cloud experience that converges public clouds, data centers, and the edge.
The Importance of Open Foundations for Running AI Workloads
Over the last decade, enterprises have learned that performance and scalability alone are not enough, and that flexibility and interoperability determine long-term success. AI workloads, in particular, depend on the ability to use disparate data sources, frameworks, and tools without being constrained by proprietary formats or systems.
That’s where open table formats like Apache Iceberg have reshaped the architecture of data platforms. Iceberg separates the logical definition of a table from its physical storage layout, allowing multiple engines and frameworks to read and write the same data with full transactional guarantees. This openness makes it possible to evolve infrastructure and adopt new compute engines without rewriting pipelines.
Running production-grade pipelines requires a unified platform that can connect data, models, and governance across every stage of the AI lifecycle. At the core, there are data and feature engineering pipelines that continuously transform raw structured, semi-structured, and unstructured data into AI-ready features, maintaining lineage and reproducibility for model training and evaluation.
Beyond traditional ML, GenAI introduces new operational requirements. Teams need infrastructure and access to data for retrieval-augmented generation (RAG), fine-tuning large language models (LLMs) on private data, and building agentic workflows that combine models, prompts, and model context protocols (MCPs) (APIs) to solve domain-specific tasks. These workloads rely on both tabular and unstructured data (text, documents, images, and embeddings)—all governed under a single data and metadata plane. Additionally, a scalable inference layer is essential to deploy and serve these models securely and efficiently.
As AI workloads become increasingly multi-modal and agentic, access to catalogs and metadata becomes just as critical. AI pipelines, retrieval systems, and autonomous agents all rely on metadata to discover datasets, reproduce training states, and maintain lineages. An open catalog provides a universal way for these systems to query, register, and track datasets—regardless of where or how they are processed.
Cloudera’s open foundation enables organizations to support the complete spectrum of analytical, predictive, and GenAI workloads.
Cloudera’s Unified Data and AI Platform
Cloudera’s open data lakehouse unifies data engineering, analytics, and AI on the same governed architecture by building on open foundations like Apache Iceberg and REST catalog. The platform is designed around the principle that workloads (whether analytical or AI) should operate where the data already lives. By eliminating the friction of moving or duplicating data, teams can build continuous pipelines that span ingestion, transformation, analytics, and model operations with full lineage and governance.
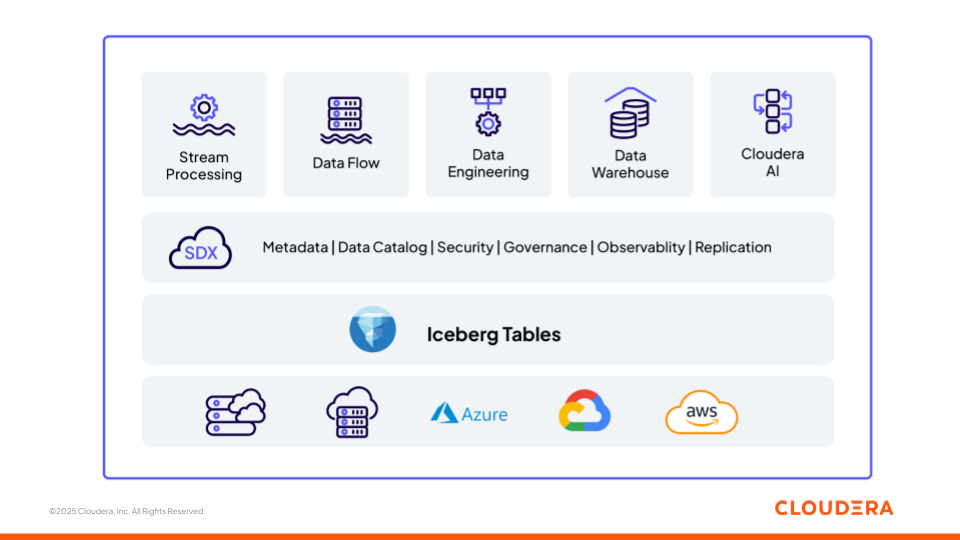
Figure 1: Cloudera’s Data and AI Platform Built on Open Foundations (Apache Iceberg)
We’ll now review how the different components in Cloudera's platform (Figure 1) support teams in building ML pipelines and GenAI applications, as well as the different stages of the data and AI lifecycle—from ingest to inference—while operating as one interoperable platform. Each component is built on open standards, ensuring flexibility and interoperability across environments.
Storage: Apache Iceberg
Apache Iceberg is the open, versioned, and transactional table format that underpins Cloudera’s lakehouse architecture. Iceberg enables schema evolution, time travel, and atomic operations, allowing both analytical and AI workloads to operate consistently on the same governed data. Cloudera offers a governed and versioned foundation that ensures that every model, prompt, or retrieval task draws from a consistent and traceable view of data.
Iceberg’s native capabilities like schema evolution also align closely with how AI datasets evolve. Feature stores, training datasets, and retrieval corpora can all share the same Iceberg tables in Cloudera’s lakehouse, using snapshots to freeze consistent views for training while new data continues to flow in for inference. This eliminates the divide between analytical tables and AI-specific storage.
Ingestion: Cloudera Data in Motion
Cloudera DataFlow, built on Apache NiFi, forms the foundation for continuous data movement into the lakehouse. It enables low-latency ingestion from diverse enterprise sources—databases, APIs, IoT devices, and event logs—to support both batch and streaming workloads. Recent innovations in NiFi’s native Apache Iceberg integration now allow data to be written directly into the open lakehouse without intermediate staging. This tight coupling between NiFi and Iceberg reduces pipeline complexity and brings ingestion closer to the open table format itself.
In real-time use cases, NiFi, Apache Kafka, and Apache Flink form an event-driven ingestion fabric: NiFi orchestrates and routes data, Kafka provides durable streaming, and Flink enables real-time enrichment before persisting data into Iceberg. This design ensures that data remains both fresh and governed across all downstream consumers. This continuous flow of multimodal data is what also powers AI workloads on the lakehouse. By making real-time data continuously available in Iceberg tables under consistent governance, enterprises can feed GenAI systems with timely, domain-specific information, making RAG pipelines and agentic workflows more precise, grounded, and reliable.
Catalog: Cloudera Iceberg REST Catalog
The Cloudera Iceberg REST Catalog (based on the open REST specification) provides a centralized and interoperable metadata service that allows any third-party engine (such as Snowflake, Redshift, and Databricks) that supports the open specification to have zero-copy access to Iceberg tables. This is a key aspect for organizations, as they are not restricted to just one compute engine offered by one platform and therefore have the flexibility to choose the best compute for the task. Users can use their preferred tools while the same security and governance policies offered by Cloudera follow the data everywhere, ensuring consistency across environments.
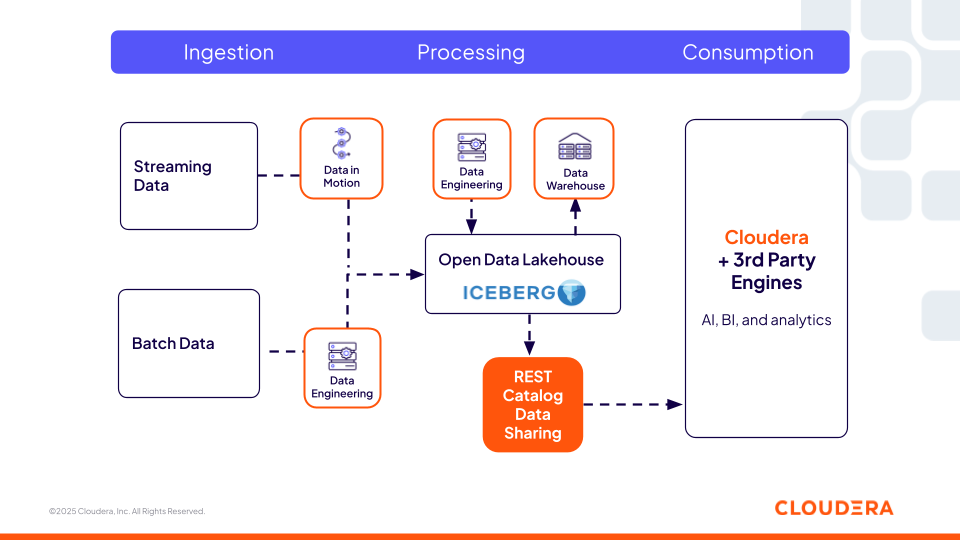
Figure 2: Cloudera’s Iceberg REST Catalog Enables Interoperability with Third-Party Engines
This catalog layer is critical for feature engineering pipelines, agentic workflows, and retrieval systems to locate and access governed datasets dynamically. AI agents can query Iceberg tables using the REST Catalog just like a knowledge graph of enterprise data. They can discover available tables, interpret their schemas, and reason over table metadata, such as partitioning, snapshots, and lineage to determine which datasets to use.
Security and Governance: Cloudera SDX
Cloudera Shared Data Experience (SDX) is the unified security and governance framework that spans every service, from ingestion to inference. SDX provides a single, consistent layer for data lineage, auditing, access control, and policy enforcement, ensuring that every workload inherits the same security model regardless of where it runs. It integrates with enterprise identity systems (LDAP, SSO, OAuth) and supports fine-grained, role- and attribute-based access controls across structured and unstructured data.
By coupling SDX with the open lakehouse foundation, Cloudera ensures that data, models, and AI agents operate within the same governed boundary—delivering transparency, reproducibility, and trust for both analytical and GenAI workloads.
Cloudera Data and AI Services
The unified services layer brings together all the functional capabilities that teams need to transform, analyze, and operationalize AI, all while working on the same governed data.
Data Engineering
Cloudera Data Engineering, built on open-source Apache Spark and Apache Airflow, provides a serverless service for building, orchestrating, and scaling data pipelines directly on Iceberg tables—enabling reliable, reproducible ETL and feature pipelines for analytics and AI workloads across hybrid environments.
AI Services
The Cloudera AI services layer operationalizes the full lifecycle of AI, starting from model training and fine-tuning to secure deployment—all running natively on the same governed data foundation with Iceberg. It unifies model development, registry, and inference into a single workflow that bridges data engineering and AI operations.
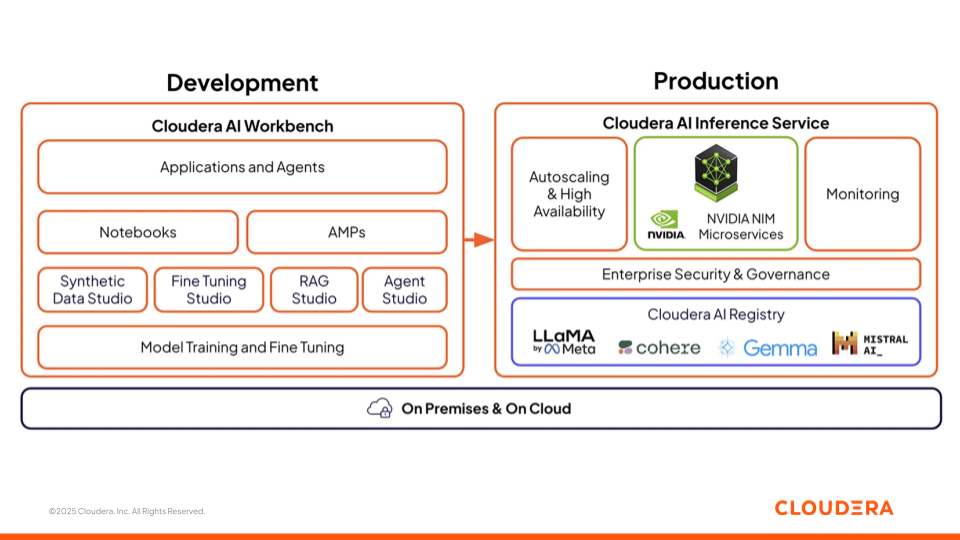
Figure 3: Cloudera AI’s Offering with AI Workbench and Inference Service
Cloudera AI Workbench
Cloudera AI Workbench is the collaborative environment where data scientists, analysts, and engineers develop, fine-tune, and test models. It brings together notebooks, low-code application builders (AMPs), and specialized studios for every stage of AI development. To accelerate AI development and deployment, Cloudera AI Workbench underpins four AI studios that bridge the gap between business and technical teams, fostering collaboration on AI projects.
- Synthetic Data Studio generates synthetic datasets for testing and model training when real data is limited or restricted.
- Fine-Tuning Studio adapts open foundation models with enterprise-specific datasets for higher relevance and accuracy.
- RAG Studio builds RAG pipelines that connect LLMs (such as OpenAI, Anthropic, Amazon Bedrock) to relevant private data for grounded, contextual outputs.
- Agent Studio enables the creation of multi-step, agentic workflows that use models, MCPs, APIs, and internal data sources to automate domain-specific tasks.
All of these capabilities operate on the open lakehouse (on Iceberg’s foundations), giving teams governed, zero-copy access to the data needed for specific tasks.
Cloudera MCP Server
Cloudera is also extending the openness of its AI platform through a series of emerging MCP services, beginning with the open-source Cloudera AI Workbench MCP Server. This service is designed for AI system integration, enabling agentic and tool-calling capabilities within the AI Workbench. It provides the framework for LLMs to securely interact with Cloudera AI Workbench features and components—bringing models, data, and applications into automated enterprise workflows. In this architecture, intelligent agents can reason, act, and automate tasks across the trusted, governed Cloudera environment while maintaining the security, control, and auditability required in regulated industries.
Cloudera AI Inference Service
The Cloudera AI Inference Service brings models into production with autoscaling, high availability, and end-to-end observability. It supports both traditional ML models and large language models (LLMs), serving predictions and responses with low latency. Models can be deployed as REST or gRPC endpoints with enterprise-grade security, ensuring reliable and consistent access from applications and agents.
The Cloudera AI Registry, integrated within the inference layer, provides a centralized model lifecycle management with MLflow-compatible APIs for tracking, versioning, artifact storage, and lineage. You have the choice to select from the various open and enterprise language models options such as LlaMa, Cohere, Gemma, Mistral.
The inference layer also includes built-in monitoring and observability, enabling teams to track latency, throughput, and model drift while maintaining full lineage and compliance through SDX governance. This ensures that model predictions are explainable and traceable, which is a key requirement for enterprise-grade AI.
The Future is Driven by AI, and AI is Fueled by All Data
AI success depends as much on data architecture as on model/agent capability. The lakehouse provides that foundation, unifying analytical, operational, and AI workloads on a single, governed data plane. When built on open standards, it ensures that data, metadata, and models can interoperate across tools, clouds, and teams without friction.
Together, Cloudera AI Workbench, AI Inference Service, and the integrated AI Registry complete the data-to-AI lifecycle on an open lakehouse foundation. Built directly on governed Iceberg tables and open metadata access, this stack ensures that every model, prompt, and agent operates on trusted, versioned data.
The future of enterprise AI will not be defined by proprietary stacks, but by open foundations that unify data, governance, and intelligence through shared standards and transparent interoperability.
To learn more about how to securely prepare, integrate, and analyze data at scale with Cloudera, check out our product demos.
