Elevating Productivity: Cloudera Data Engineering Brings External IDE Connectivity to Apache Spark



As advanced analytics and AI continue to drive enterprise strategy, leaders are tasked with building flexible, resilient data pipelines that accelerate trusted insights. AI pioneer Andrew Ng recently underscored that robust data engineering is foundational to the success of data-centric AI—a strategy that prioritizes data quality over model complexity. McKinsey Quarterly’s latest research further forecasts a future of “data ubiquity” by 2030, where enterprise data is seamlessly embedded across systems, processes, and decision points. For enterprises, the challenge now is not just rapid deployment; it’s about building trusted, iterative processes that ensure high-quality and actionable data at scale.
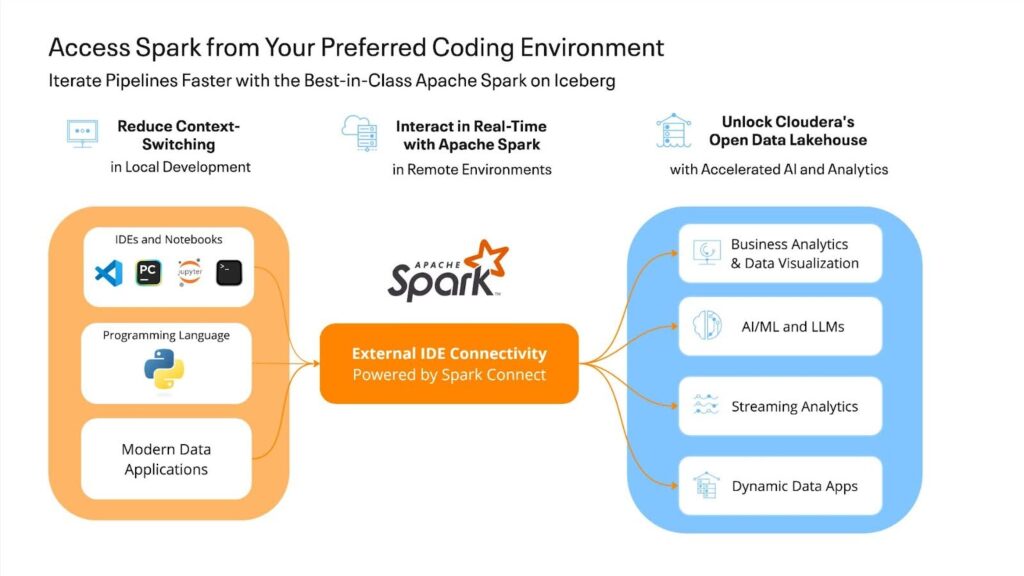
Cloudera Data Engineering’s latest version release on public cloud addresses this rising challenge by introducing major enhancements in development productivity with enterprise-secured toolings, bringing remote access to Apache Spark from the practitioner’s preferred coding environments. This release marks a milestone toward Cloudera Data Engineering’s vision of providing the best practitioner-centric, production-grade pipelining and orchestration solutions.
A New Level of Productivity with Remote Access
The new Cloudera Data Engineering 1.23 on public cloud spotlights External IDE Connectivity, which enables data engineers to access Apache Spark clusters and data pipelines directly from their preferred development environments (e.g., Jupyter, PyCharm, and VS Code). Extended data practitioner teams can work in their preferred coding environments without proprietary lock-ins.
Along with Cloudera Data Engineering’s Interactive Sessions, data teams can reap the benefits of iterative development, fostering more collaborative iterative workflows to drive quality while maintaining robust security standards.
Best-in-Class Apache Spark on Iceberg
This release also brings new capabilities designed to enhance cost-effectiveness. Support for Apache Iceberg 1.5, together with Apache Spark 3.5, delivers better performance and optimized cost management. In Change Data Capture (CDC) use cases, advanced row-level deletes with Merge-on-Read improve query efficiency, reducing resource consumption and operational costs.
Why Cloudera Data Engineering?
Cloudera customers benefit from enterprise-secured tools to build collaborative sandboxes, empowering data engineers, data scientists, and extended data practitioner teams that need insights to drive decisions. With 100x more data under management compared to other cloud-only vendors, Cloudera empowers enterprises to build open data lakehouses for scalable and secure data management with portable analytics across hybrid cloud environments.
Top innovators from financial, healthcare, and other data-intensive industries rely on Cloudera Data Engineering for several reasons:
- Secure Data Pipelining Across Hybrid Environments: With Apache Spark as the engine, Cloudera Data Engineering provides secure ingestion, seamlessly handling data in different formats across hybrid clouds to meet the varied needs of modern data pipelines. Powered by integrated platform services, Cloudera Data Engineering ensures data governance with robust data handling and automated lifecycle lineage tracking.
- Simplified Workflows and Iterative Collaborations: With Apache Airflow, Cloudera Data Engineering provides API integrations for external data tools like dbt. Interactive Sessions and the latest External IDE Connectivity support quick iterations and collaborations.
- Data Interoperability With Lower TCO: Cloudera Data Engineering has native support for Apache Iceberg - the leading open table format purpose-built for managing exabyte-scale data lakes and delivering high-performance queries. Unlike cloud vendors with proprietary engines, Cloudera Data Engineering optimizes cost efficiency by leveraging open-source technologies and integrated platform services like Cloudera Observability.
Ready to Explore?
Discover how Cloudera Data Engineering can accelerate time-to-value in building future-proof modern data architectures:
- Download the new datasheet for Cloudera Data Engineering
- View Product Release Notes
- Join the community for upcoming demos