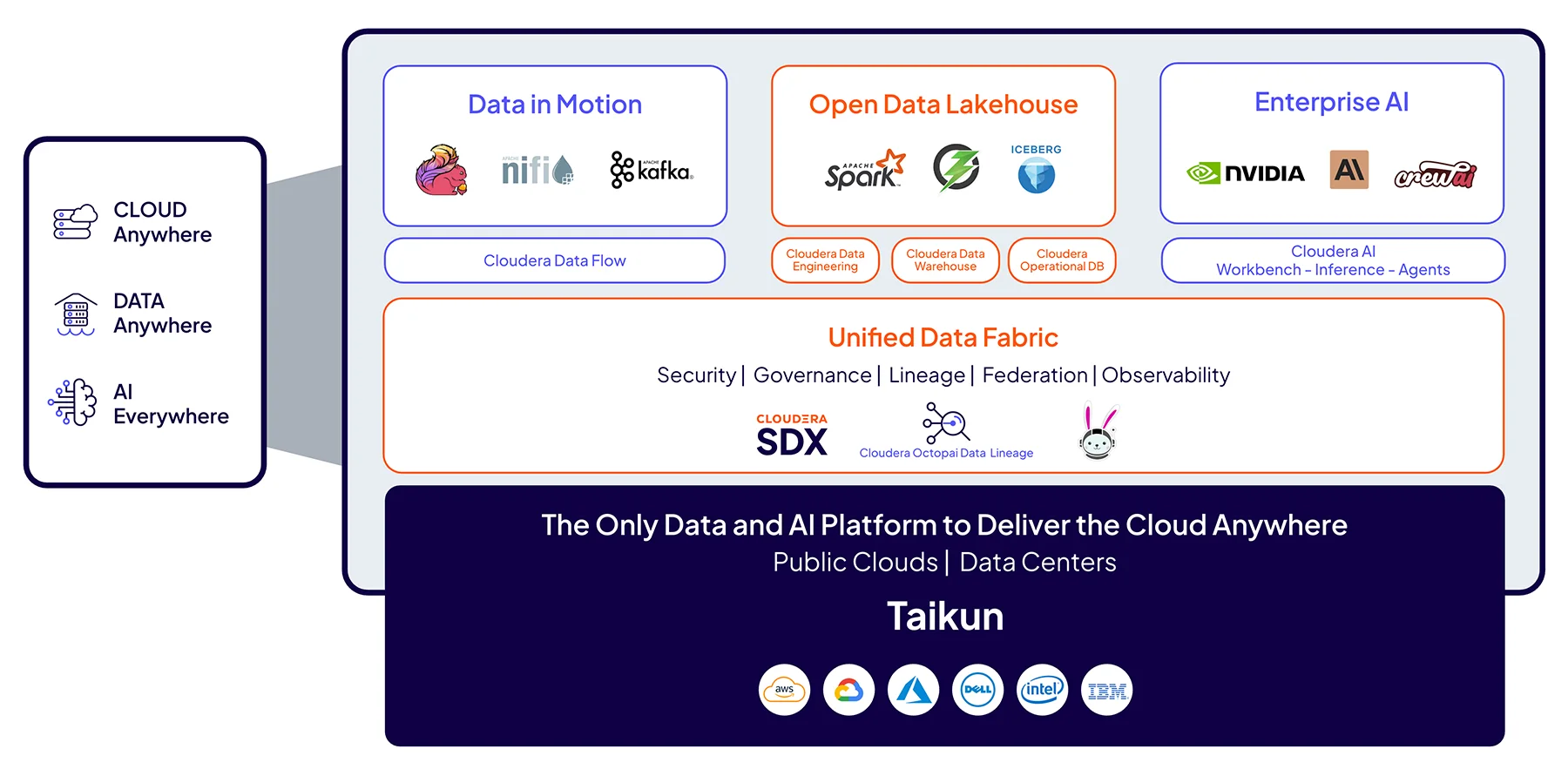
Cloudera Products
The only data and AI platform to deliver the cloud anywhere, delivering end-to-end containerized data services in a single platform.

We empower enterprises with a data and AI platform that transforms 100% of data anywhere into trusted, valuable insights for business-critical impact everywhere.
Cloud Anywhere
Control workloads and data across infrastructures with a fully interoperable and consistent cloud experience without workload refactoring or application rewrites. Maintain flexibility seamlessly, lowering TCO and reducing migration costs.
Cloudera Platform
The industry’s only data and AI platform that large organizations trust to bring AI to their data anywhere it lives.
Cloudera Object Store
Scale to billions of objects with full S3 compatibility and a lower TCO with the object store powered by Apache Ozone.
Cloudera Data Services
Get the agility of the cloud for data and AI applications, anywhere, with powerful services to accelerate innovation.
Enterprise AI
Initiate, accelerate, and capitalize on AI opportunities with full control and complete security and governance. Build and run private AI for enterprise-grade applications and agents, at scale, lowering costs without sacrificing compliance. Learn more
Accelerate data-driven decision making from research to production with a secure, scalable, and open platform for enterprise AI.
Deploy and scale private AI applications, agents, and assistants with unmatched speed, security, and efficiency.
Unlock private generative AI and agentic workflows for any skill level, with low-code speed and full-code control.
Bring the power of AI to your business securely and at scale, ensuring every insight is traceable, explainable, and trusted.
Securely build, train,and deploy private AI with unified collaborative AI development on governed data anywhere.
Accelerators for ML Projects (AMPs)
Explore the end-to-end framework for building, deploying, and monitoring business-ready machine learning applications instantly.
Open Data Lakehouse
Deliver unified, secure, and reliable data across the entire data lifecycle while integrating seamlessly with existing enterprise systems thanks to Apache Iceberg’s open table format for large data sets. Learn more
Securely build, orchestrate, and govern enterprise-grade data pipelines with Apache Spark on Iceberg.
Power real-time, critical applications with a high-performance NoSQL solution built for the demands of hybrid environments.
Analyze massive amounts of data for thousands of concurrent users without compromising speed, cost, or security.
Confidently manage your toughest data challenges with the industry’s only open data lakehouse for data and AI built on Apache Iceberg.
Connect data sources across platforms, clouds, and data centers, delivering AI-ready data that’s fast, secure, and optimized.
Unified Data Fabric
Lower risk and ensure compliance while democratizing self-service access to trusted data with centralized enterprisewide data lineage and metadata management, access controls, and governance. Learn more

Cloudera Shared Data Experience
Unifying security and governance with open cloud-native storage formats, SDX decreases costs, increases business agility and insights, and lets you stay compliant by centrally managing all your data.
Manage and understand data lineage and metadata for complete visibility across complex hybrid environments.
Discover, classify, and profile all your data, enforcing compliance with policy-based controls for sensitive or regulated information.
Monitor and optimize Cloudera deployments anywhere they live for better resource utilization and financial governance.
Enables business users to quickly and easily explore governed data, collaborate, and unlock insights with AI-powered dashboards.
Data in Motion
Deliver true, real-time, data-driven insights on any infrastructure, enabling faster decisions, increasing operational efficiency, improving customer satisfaction, and growing revenue faster. Learn more
Collect and move your data from any source to any destination in a simple, secure, scalable, and cost-effective way.
Tap into Kafka and Flink to create high-performance, real-time services and applications to drive your business.
Gain control of your data from edge devices with real-time edge data collection and management.
Cloudera deployment options
Deploy Cloudera anywhere with a cloud-native, portable, and consistent experience everywhere.
Cloudera on cloud
Cloudera on cloud data services are managed by Cloudera, but unlike other public cloud services, your data will always remain under your control in your VPC. Cloudera runs on AWS, Azure, and Google Cloud.
- Control cloud costs: Automatically spin up workloads when needed and suspend their operation when complete.
- Manage workloads: Isolate and control workloads by user type, workload type, and workload priority.
- Break down silos: Centrally control customer and operational data across multi-cloud and hybrid environments.
Cloudera on premises
Cloudera on premises modernizes traditional monolithic cluster deployments; provides powerful analytic, transactional, and ML workloads; and supports traditional and elastic analytics and scalable object storage in a hybrid data platform.
- Rapid time to value: Simple provisioning of easy-to-use, self-service analytics in minutes rather than days.
- Improved cost-efficiency: Optimized resource utilization and decoupling of compute and storage.
- Predictable performance: Proven workload isolation and perfectly managed multi-tenancy.
Our customers
 financial services
United Overseas Bank
financial services
United Overseas Bank
 telecommunications
Amdocs
telecommunications
Amdocs
 transportation
Halifax International Airport Authority
transportation
Halifax International Airport Authority