What’s Your Return on Intelligence? Moving from Public Token Tolls to Predictable AI Economic


The token-based economy is running into a wall of economic reality. Whether it’s an accidental half-a-billion-dollar token usage bill [Axios] or burning through an annual token budget in four months [TechCrunch], finance teams are quietly implementing stricter cost controls after getting burned by unpredictable AI-related invoices.
While hardware innovation outpaced Moore’s law for over a decade, our recent AI consumption habits grew faster. The massive token volumes required for "reasoning" or “thinking” models outstripped compute gains. This is Jevons paradox on full display: as compute becomes more efficient, we simply find ways to burn exponentially more of it; and burning through tokens is mistakenly treated as a proxy for innovation. The real challenge is optimizing for the highest return on intelligence by carefully adjusting where and how to run today’s compute-hungry models so that every token spent drives a clear business outcome.
Why Cost Control and Efficiency Are Paramount
Control over intelligence costs is paramount to stay competitive as AI capabilities become commoditized. To rein in costs, an enterprise must own its operational setup—underlying infrastructure, models, and data—whether sitting in a data center or a private virtual cloud. Infrastructure ownership shifts the account unit from variable token fees to predictable compute capacity. Self-hosting allows companies to link Large Language Models (LLMs) to deterministic data systems where costs and workflows are entirely predictable as scale increases, and stable for repetitive tasks.
Model ownership is equally critical. Commercial labs face pressure to optimize consumer endpoints, but relying on these changing endpoints introduces enterprise unpredictability. External provider updates can ruin business logic, and sunsetting models forces outsized resources into retesting pipelines or paying unsubsidized market rates. Training or fine-tuning on third-party cloud platforms traps your intellectual property if you cannot export the weights and fine-tuned adapters. You need the flexibility to migrate assets if host pricing spikes or performance drops. Moving massive datasets also incurs data movement fees and complicates governance frameworks under variable cloud pricing. Retaining control over your environment and the inference layer is a strategic necessity to protect your balance sheet.
Ownership grants the freedom to optimize what runs and where. Enterprises can route everyday automation to optimized Small Language Models (SLMs) while reserving premium computing for complex reasoning requests with LLMs. You control version updates, fine-tune locations, and keep proprietary prompts and data secure from public models. This matters most at the inference layer, which consumes most of a GenAI model's lifetime compute overhead and serves as the primary cost driver for production workloads running chatbots or long-horizon agentic workflows. Cloudera provides an integrated, end-to-end framework covering the full enterprise AI lifecycle from data ingestion and wrangling to model training and serving. Operating an end-to-end platform eliminates the fragmentation tax of multi-vendor enterprise setups, and the Cloudera AI Inference service provides the ultimate point of leverage.
Efficient AI, Today?
On an individual level, calculating a precise return on intelligence for LLM usage is difficult. Individual choice tends to be subjective and highly context-dependent, consisting mostly of one-off research queries, ad-hoc question-and-answer pairs, or a vibe-coded prototype. In contrast, repeatable enterprise data workflows are highly structured, with well-defined tasks and expected outcomes. Pipelines do not require massive generalists; smaller, faster models deliver lower latency and higher throughput while maximizing hardware efficiency. Cloudera evaluates these economics through private AI, ensuring privacy via platform governance while maintaining ownership over data and model endpoints.
When an enterprise operates high-volume production workloads—such as running 70-billion-parameter frontier-class models at scale—the cumulative total cost of ownership quickly diverges from public cloud token APIs. Based on evaluations of high-utilization enterprise environments, deploying inference on private infrastructure yields a stark cost advantage over paying third-party token fees once a company moves beyond a certain workload volume.
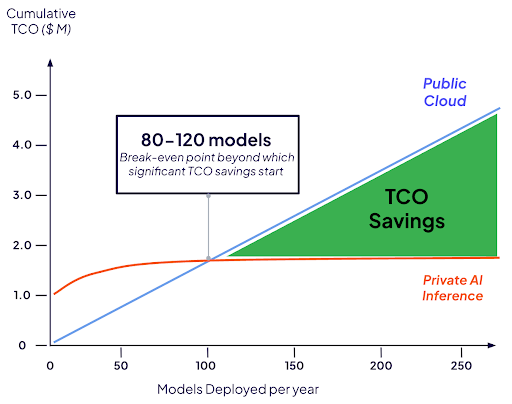
To illustrate how these economics function in practice, consider an agentic wealth management co-pilot running long-horizon, multi-step workflows like meeting prep, KYC verification, portfolio rebalancing, and CRM updates. A single manager can easily use more than 70 million tokens per month. At scale, running this assistant via public APIs is more than 4x more expensive than deploying private AI inference.
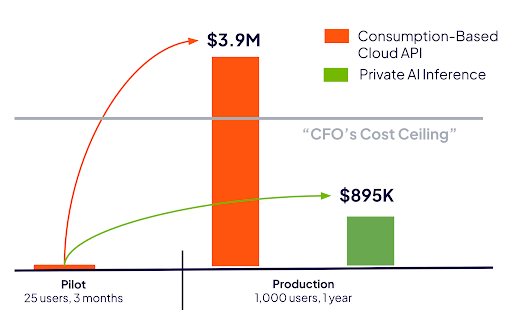
Keep in mind that these are illustrative estimates focused on a specific model, parameter size, and compute setup. Model capabilities shift rapidly, and smaller, specialized open models frequently outperform yesterday's massive generalist engines within a span of a few months. Savings will vary depending on your reasoning complexity, token input-to-output ratios, and underlying hardware configuration.
However, the financial thesis remains constant: for repeatable enterprise automation, private model serving removes the unpredictable pricing penalty of public token tolls, allowing companies to scale their AI applications sustainably.
The Era of Control and Efficiency is NOW
The period of unconstrained, pay-as-you-go experimentation with public cloud AI endpoints is drawing to a close. As enterprises move from exploratory pilots into steady-state production, the evaluation criteria must expand beyond simple model accuracy to include predictable AI economics.
Maximizing your return on intelligence means shifting from a framework where you perpetually rent third-party models or risk unchecked token consumption, to one where you own and optimize your core computing assets. By retaining control over your underlying data, your customized models, and your inference stack, your organization can comfortably scale AI workflows without risking unpredictable cost overruns. Operational efficiency is the very foundation required to deliver sustainable enterprise AI at scale.
Join us at the upcoming ClouderaNOW to learn more about how we can make that possible for your organization.