
If the AI revolution has given way to one universal data management truth, it’s the need for openness and interoperability across the data estate. After all, AI is only as good as the data it can actually reach.
No longer are enterprises willing to invest in disconnected legacy technologies. The cost of silos, once measured in infrastructure alone, is now exponentially higher when measured in lost time to value and the inability to run AI at scale. Considering this landscape, enterprises can’t afford not to rethink their data architectures.
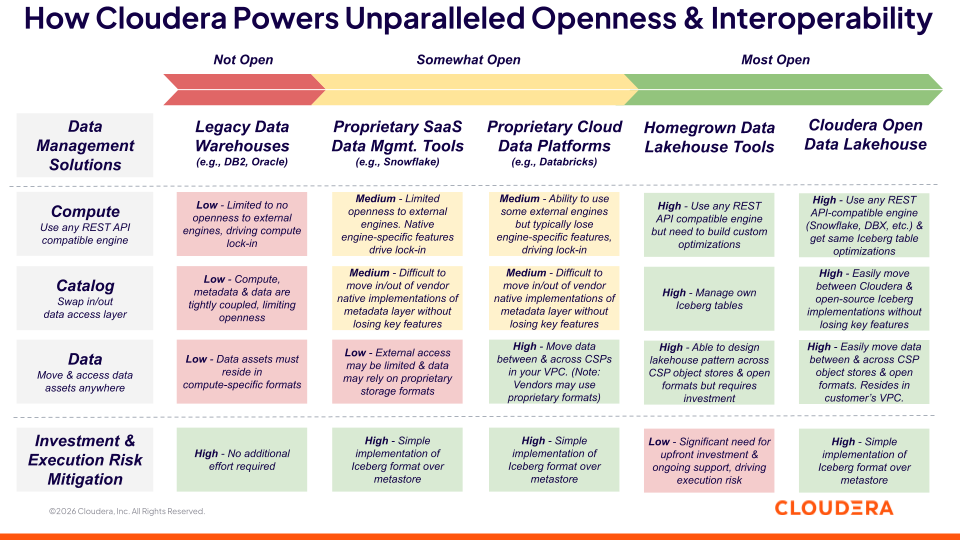
At Cloudera, we define openness as a three-layered data management architecture (see Figure 1):
Open compute: The ability to use any engine regardless of where the data is stored
Open catalog: The ability to swap in and out, and interoperate across different data access layers, ensuring schema and governance are consistent regardless of the viewing engine
Open data: The ability to move and access data assets wherever they sit
More broadly, openness is at the heart of who we are at Cloudera:
Early proponent of Apache Iceberg: Cloudera began supporting Iceberg in our public cloud Lakehouse in 2021. Other vendors quickly followed suit—implicitly acknowledging Iceberg as the winner of the open table format war. In 2024, Databricks acquired Tabular, due in part to its open governance and sophisticated features. In 2025, both Snowflake and Amazon Web Services (AWS) invested in expanding Iceberg support and features.
Open-source foundation and ecosystem: Deeply embedded in the open-source community since its founding in 2008, Cloudera was the first company to commercialize open-source data lake technology and continues to contribute to and support more than 50 open-source projects. Our open-source foundation gives freedom of choice by allowing our customers to opt in or out of Cloudera distributions far more easily compared to vendors whose proprietary overlays lock them in. Cloudera customers don’t have to stay; they choose to stay.
Interoperability across the data management stack: Providing open compute, catalog, and data ensures interoperability at each level of the data management stack so our customers can truly win in the age of AI without having to build from scratch. Additionally, Cloudera provides the flexibility to use any compute engine or land data in any cloud service provider (CSP), and provides full access to features regardless of where the data resides or what compute engine is used. Conversely, some vendors restrict access to features based on whether all layers of the stack are running in the same platform. Own your data. Control your data. Use your data—that is the promise of Cloudera.
For a deeper dive on the importance of openness in the age of AI, read our blog: The Future Delivered Today: The AI-Powered Data Lakehouse.
